 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTD: Sparse-to-Dense 3D Object Detector for Point Cloud
Jul 22, 2019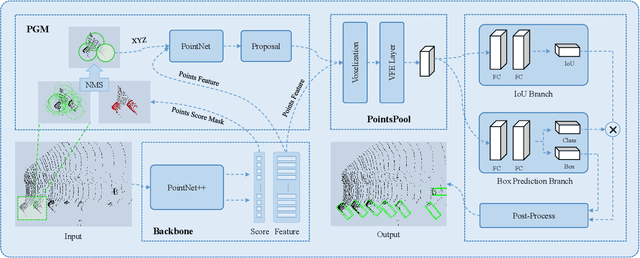
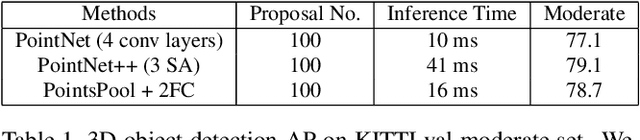
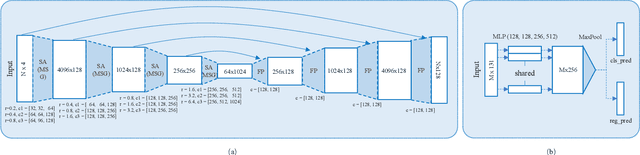

We present a new two-stage 3D object detection framework, named sparse-to-dense 3D Object Detector (STD). The first stage is a bottom-up proposal generation network that uses raw point cloud as input to generate accurate proposals by seeding each point with a new spherical anchor. It achieves a high recall with less computation compared with prior works. Then, PointsPool is applied for generating proposal features by transforming their interior point features from sparse expression to compact representation, which saves even more computation time. In box prediction, which is the second stage, we implement a parallel intersection-over-union (IoU) branch to increase awareness of localization accuracy, resulting in further improved performance. We conduct experiments on KITTI dataset, and evaluate our method in terms of 3D object and Bird's Eye View (BEV) detection. Our method outperforms other state-of-the-arts by a large margin, especially on the hard set, with inference speed more than 10 FPS.
Attribute-Driven Spontaneous Motion in Unpaired Image Translation
Jul 02, 2019
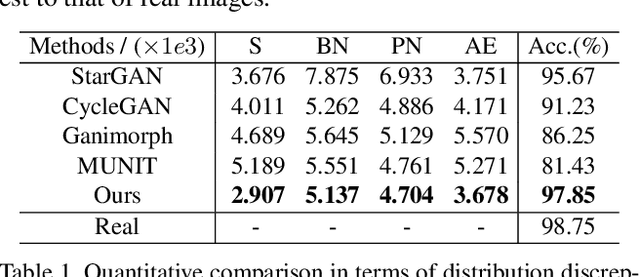
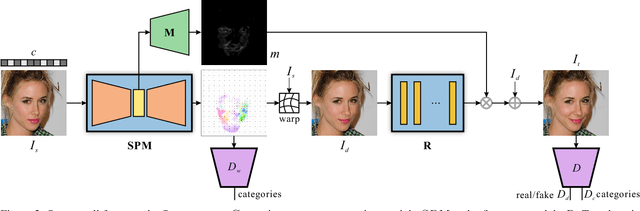
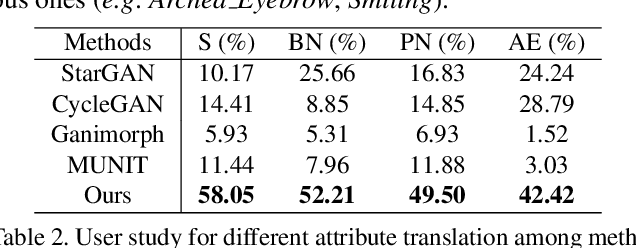
Current image translation methods, albeit effective to produce high-quality results on various applications, still do not consider much geometric transforms. We in this paper propose spontaneous motion estimation module, along with a refinement module, to learn attribute-driven deformation between source and target domains. Extensive experiments and visualization demonstrate effectiveness of these modules. We achieve promising results in unpaired image translation tasks, and enable interesting applications with spontaneous motion basis.
Landmark Assisted CycleGAN for Cartoon Face Generation
Jul 02, 2019

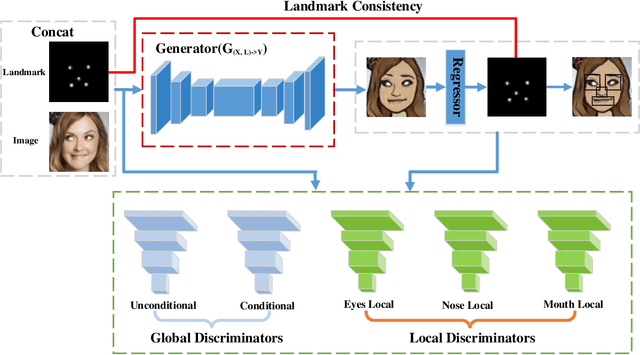
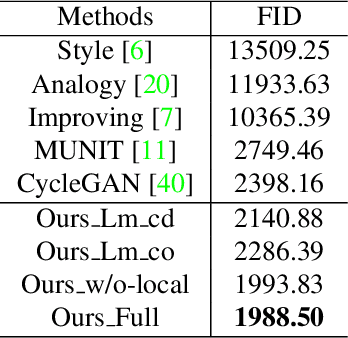
In this paper, we are interested in generating an cartoon face of a person by using unpaired training data between real faces and cartoon ones. A major challenge of this task is that the structures of real and cartoon faces are in two different domains, whose appearance differs greatly from each other. Without explicit correspondence, it is difficult to generate a high quality cartoon face that captures the essential facial features of a person. In order to solve this problem, we propose landmark assisted CycleGAN, which utilizes face landmarks to define landmark consistency loss and to guide the training of local discriminator in CycleGAN. To enforce structural consistency in landmarks, we utilize the conditional generator and discriminator. Our approach is capable to generate high-quality cartoon faces even indistinguishable from those drawn by artists and largely improves state-of-the-art.
Region Refinement Network for Salient Object Detection
Jun 27, 2019
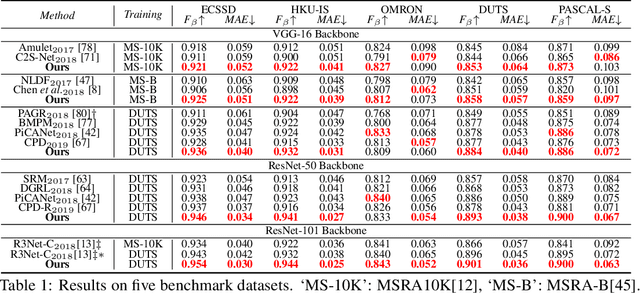


Albeit intensively studied, false prediction and unclear boundaries are still major issues of salient object detection. In this paper, we propose a Region Refinement Network (RRN), which recurrently filters redundant information and explicitly models boundary information for saliency detection. Different from existing refinement methods, we propose a Region Refinement Module (RRM) that optimizes salient region prediction by incorporating supervised attention masks in the intermediate refinement stages. The module only brings a minor increase in model size and yet significantly reduces false predictions from the background. To further refine boundary areas, we propose a Boundary Refinement Loss (BRL) that adds extra supervision for better distinguishing foreground from background. BRL is parameter free and easy to train. We further observe that BRL helps retain the integrity in prediction by refining the boundary. Extensive experiments on saliency detection datasets show that our refinement module and loss bring significant improvement to the baseline and can be easily applied to different frameworks. We also demonstrate that our proposed model generalizes well to portrait segmentation and shadow detection tasks.
2D Attentional Irregular Scene Text Recognizer
Jun 13, 2019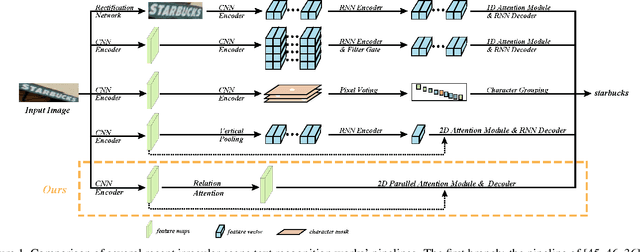
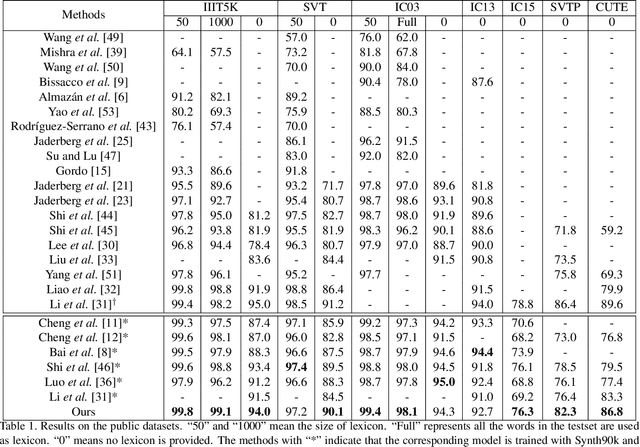
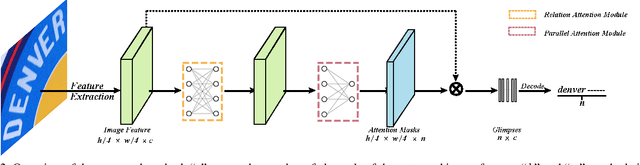
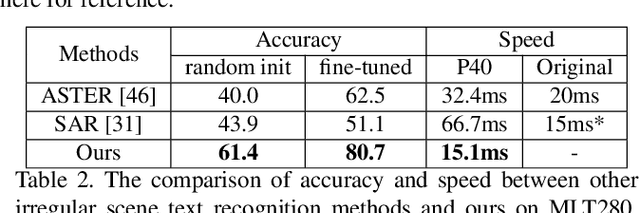
Irregular scene text, which has complex layout in 2D space, is challenging to most previous scene text recognizers. Recently, some irregular scene text recognizers either rectify the irregular text to regular text image with approximate 1D layout or transform the 2D image feature map to 1D feature sequence. Though these methods have achieved good performance, the robustness and accuracy are still limited due to the loss of spatial information in the process of 2D to 1D transformation. Different from all of previous, we in this paper propose a framework which transforms the irregular text with 2D layout to character sequence directly via 2D attentional scheme. We utilize a relation attention module to capture the dependencies of feature maps and a parallel attention module to decode all characters in parallel, which make our method more effective and efficient. Extensive experiments on several public benchmarks as well as our collected multi-line text dataset show that our approach is effective to recognize regular and irregular scene text and outperforms previous methods both in accuracy and speed.
Memory-Attended Recurrent Network for Video Captioning
May 10, 2019
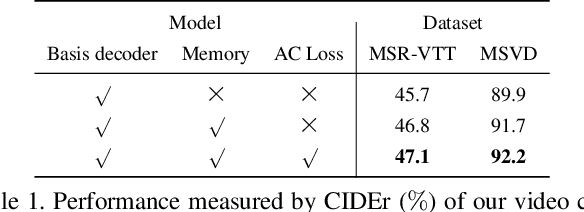
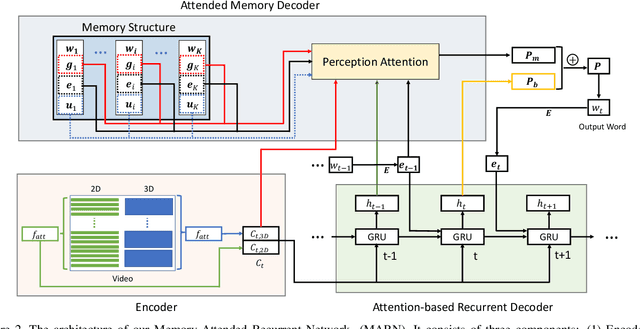

Typical techniques for video captioning follow the encoder-decoder framework, which can only focus on one source video being processed. A potential disadvantage of such design is that it cannot capture the multiple visual context information of a word appearing in more than one relevant videos in training data. To tackle this limitation, we propose the Memory-Attended Recurrent Network (MARN) for video captioning, in which a memory structure is designed to explore the full-spectrum correspondence between a word and its various similar visual contexts across videos in training data. Thus, our model is able to achieve a more comprehensive understanding for each word and yield higher captioning quality. Furthermore, the built memory structure enables our method to model the compatibility between adjacent words explicitly instead of asking the model to learn implicitly, as most existing models do. Extensive validation on two real-word datasets demonstrates that our MARN consistently outperforms state-of-the-art methods.
Associatively Segmenting Instances and Semantics in Point Clouds
Feb 28, 2019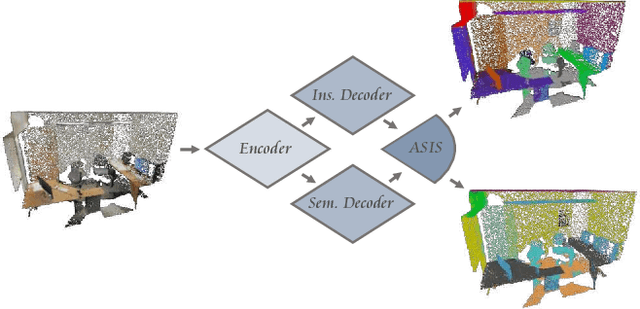
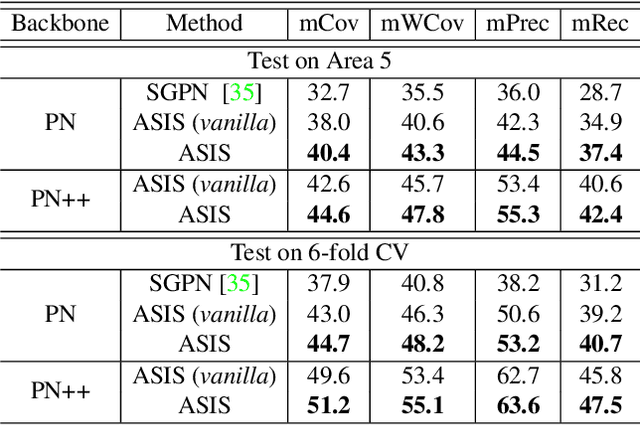

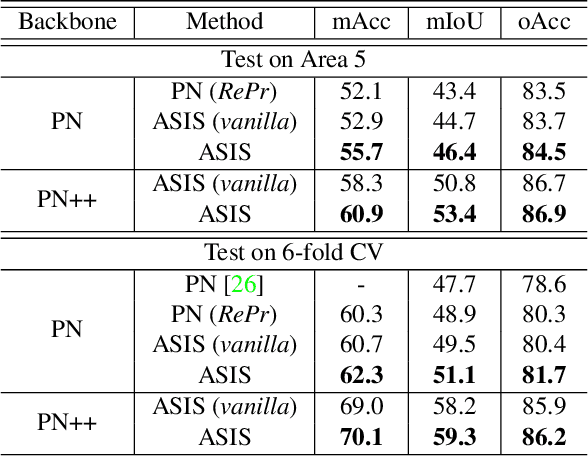
A 3D point cloud describes the real scene precisely and intuitively.To date how to segment diversified elements in such an informative 3D scene is rarely discussed. In this paper, we first introduce a simple and flexible framework to segment instances and semantics in point clouds simultaneously. Then, we propose two approaches which make the two tasks take advantage of each other, leading to a win-win situation. Specifically, we make instance segmentation benefit from semantic segmentation through learning semantic-aware point-level instance embedding. Meanwhile, semantic features of the points belonging to the same instance are fused together to make more accurate per-point semantic predictions. Our method largely outperforms the state-of-the-art method in 3D instance segmentation along with a significant improvement in 3D semantic segmentation. Code has been made available at: https://github.com/WXinlong/ASIS.
Human Pose Estimation with Spatial Contextual Information
Jan 07, 2019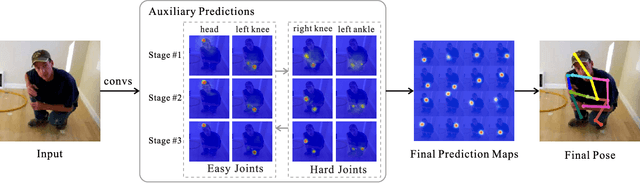
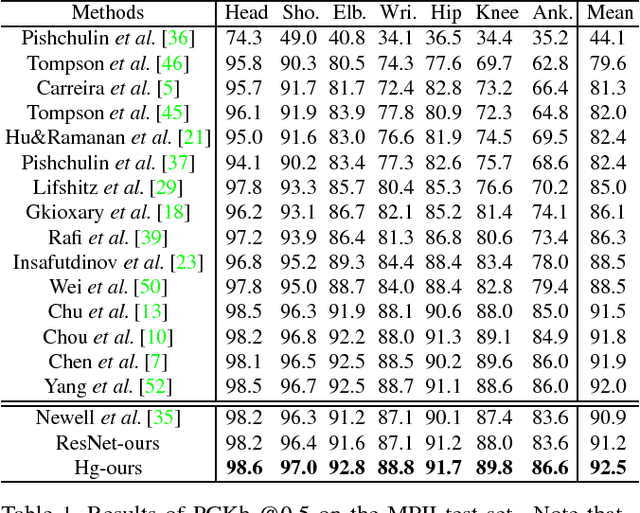
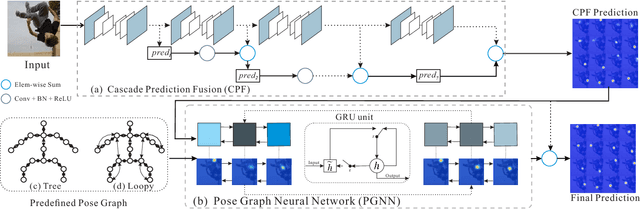
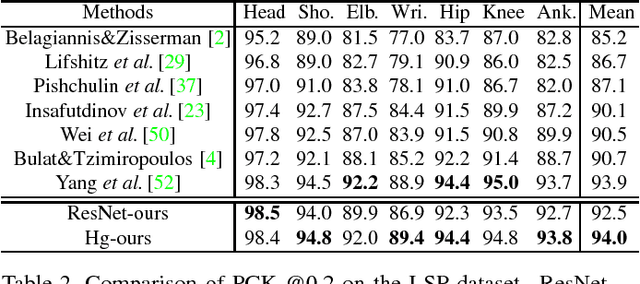
We explore the importance of spatial contextual information in human pose estimation. Most state-of-the-art pose networks are trained in a multi-stage manner and produce several auxiliary predictions for deep supervision. With this principle, we present two conceptually simple and yet computational efficient modules, namely Cascade Prediction Fusion (CPF) and Pose Graph Neural Network (PGNN), to exploit underlying contextual information. Cascade prediction fusion accumulates prediction maps from previous stages to extract informative signals. The resulting maps also function as a prior to guide prediction at following stages. To promote spatial correlation among joints, our PGNN learns a structured representation of human pose as a graph. Direct message passing between different joints is enabled and spatial relation is captured. These two modules require very limited computational complexity. Experimental results demonstrate that our method consistently outperforms previous methods on MPII and LSP benchmark.
IPOD: Intensive Point-based Object Detector for Point Cloud
Dec 13, 2018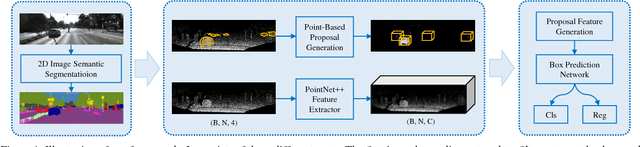
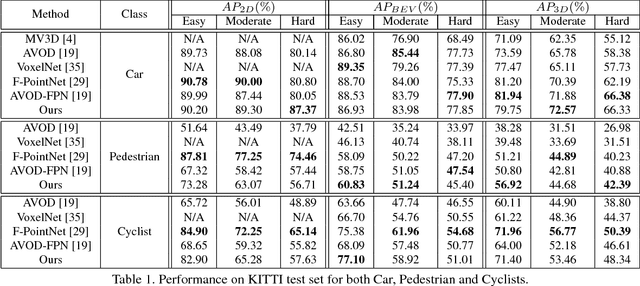
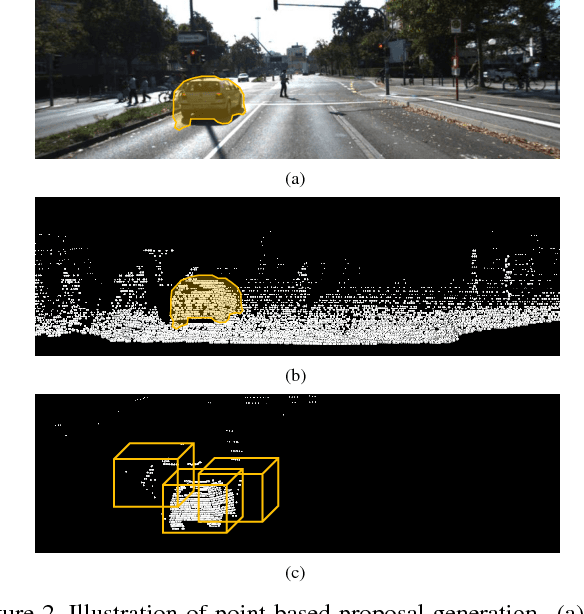
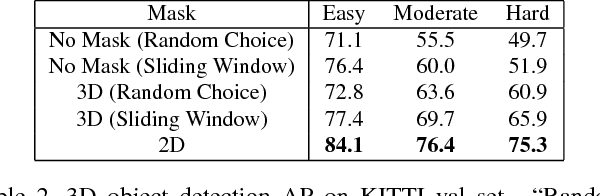
We present a novel 3D object detection framework, named IPOD, based on raw point cloud. It seeds object proposal for each point, which is the basic element. This paradigm provides us with high recall and high fidelity of information, leading to a suitable way to process point cloud data. We design an end-to-end trainable architecture, where features of all points within a proposal are extracted from the backbone network and achieve a proposal feature for final bounding inference. These features with both context information and precise point cloud coordinates yield improved performance. We conduct experiments on KITTI dataset, evaluating our performance in terms of 3D object detection, Bird's Eye View (BEV) detection and 2D object detection. Our method accomplishes new state-of-the-art , showing great advantage on the hard set.
Image Inpainting via Generative Multi-column Convolutional Neural Networks
Oct 20, 2018

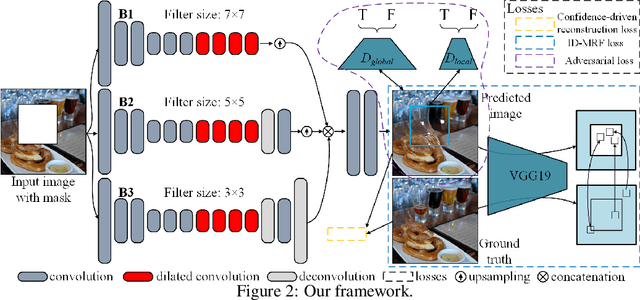

In this paper, we propose a generative multi-column network for image inpainting. This network synthesizes different image components in a parallel manner within one stage. To better characterize global structures, we design a confidence-driven reconstruction loss while an implicit diversified MRF regularization is adopted to enhance local details. The multi-column network combined with the reconstruction and MRF loss propagates local and global information derived from context to the target inpainting regions. Extensive experiments on challenging street view, face, natural objects and scenes manifest that our method produces visual compelling results even without previously common post-processing.