 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMICON-Bench: Benchmarking and Enhancing Multi-Image Context Image Generation in Unified Multimodal Models
Feb 23, 2026Recent advancements in Unified Multimodal Models (UMMs) have enabled remarkable image understanding and generation capabilities. However, while models like Gemini-2.5-Flash-Image show emerging abilities to reason over multiple related images, existing benchmarks rarely address the challenges of multi-image context generation, focusing mainly on text-to-image or single-image editing tasks. In this work, we introduce \textbf{MICON-Bench}, a comprehensive benchmark covering six tasks that evaluate cross-image composition, contextual reasoning, and identity preservation. We further propose an MLLM-driven Evaluation-by-Checkpoint framework for automatic verification of semantic and visual consistency, where multimodal large language model (MLLM) serves as a verifier. Additionally, we present \textbf{Dynamic Attention Rebalancing (DAR)}, a training-free, plug-and-play mechanism that dynamically adjusts attention during inference to enhance coherence and reduce hallucinations. Extensive experiments on various state-of-the-art open-source models demonstrate both the rigor of MICON-Bench in exposing multi-image reasoning challenges and the efficacy of DAR in improving generation quality and cross-image coherence. Github: https://github.com/Angusliuuu/MICON-Bench.
Test-Time Computing for Referring Multimodal Large Language Models
Feb 23, 2026We propose ControlMLLM++, a novel test-time adaptation framework that injects learnable visual prompts into frozen multimodal large language models (MLLMs) to enable fine-grained region-based visual reasoning without any model retraining or fine-tuning. Leveraging the insight that cross-modal attention maps intrinsically encode semantic correspondences between textual tokens and visual regions, ControlMLLM++ optimizes a latent visual token modifier during inference via a task-specific energy function to steer model attention towards user-specified areas. To enhance optimization stability and mitigate language prompt biases, ControlMLLM++ incorporates an improved optimization strategy (Optim++) and a prompt debiasing mechanism (PromptDebias). Supporting diverse visual prompt types including bounding boxes, masks, scribbles, and points, our method demonstrates strong out-of-domain generalization and interpretability. The code is available at https://github.com/mrwu-mac/ControlMLLM.
CSMCIR: CoT-Enhanced Symmetric Alignment with Memory Bank for Composed Image Retrieval
Jan 07, 2026Composed Image Retrieval (CIR) enables users to search for target images using both a reference image and manipulation text, offering substantial advantages over single-modality retrieval systems. However, existing CIR methods suffer from representation space fragmentation: queries and targets comprise heterogeneous modalities and are processed by distinct encoders, forcing models to bridge misaligned representation spaces only through post-hoc alignment, which fundamentally limits retrieval performance. This architectural asymmetry manifests as three distinct, well-separated clusters in the feature space, directly demonstrating how heterogeneous modalities create fundamentally misaligned representation spaces from initialization. In this work, we propose CSMCIR, a unified representation framework that achieves efficient query-target alignment through three synergistic components. First, we introduce a Multi-level Chain-of-Thought (MCoT) prompting strategy that guides Multimodal Large Language Models to generate discriminative, semantically compatible captions for target images, establishing modal symmetry. Building upon this, we design a symmetric dual-tower architecture where both query and target sides utilize the identical shared-parameter Q-Former for cross-modal encoding, ensuring consistent feature representations and further reducing the alignment gap. Finally, this architectural symmetry enables an entropy-based, temporally dynamic Memory Bank strategy that provides high-quality negative samples while maintaining consistency with the evolving model state. Extensive experiments on four benchmark datasets demonstrate that our CSMCIR achieves state-of-the-art performance with superior training efficiency. Comprehensive ablation studies further validate the effectiveness of each proposed component.
CIR-CoT: Towards Interpretable Composed Image Retrieval via End-to-End Chain-of-Thought Reasoning
Oct 09, 2025



Composed Image Retrieval (CIR), which aims to find a target image from a reference image and a modification text, presents the core challenge of performing unified reasoning across visual and semantic modalities. While current approaches based on Vision-Language Models (VLMs, e.g., CLIP) and more recent Multimodal Large Language Models (MLLMs, e.g., Qwen-VL) have shown progress, they predominantly function as ``black boxes." This inherent opacity not only prevents users from understanding the retrieval rationale but also restricts the models' ability to follow complex, fine-grained instructions. To overcome these limitations, we introduce CIR-CoT, the first end-to-end retrieval-oriented MLLM designed to integrate explicit Chain-of-Thought (CoT) reasoning. By compelling the model to first generate an interpretable reasoning chain, CIR-CoT enhances its ability to capture crucial cross-modal interactions, leading to more accurate retrieval while making its decision process transparent. Since existing datasets like FashionIQ and CIRR lack the necessary reasoning data, a key contribution of our work is the creation of structured CoT annotations using a three-stage process involving a caption, reasoning, and conclusion. Our model is then fine-tuned to produce this structured output before encoding its final retrieval intent into a dedicated embedding. Comprehensive experiments show that CIR-CoT achieves highly competitive performance on in-domain datasets (FashionIQ, CIRR) and demonstrates remarkable generalization on the out-of-domain CIRCO dataset, establishing a new path toward more effective and trustworthy retrieval systems.
MIHBench: Benchmarking and Mitigating Multi-Image Hallucinations in Multimodal Large Language Models
Aug 01, 2025Despite growing interest in hallucination in Multimodal Large Language Models, existing studies primarily focus on single-image settings, leaving hallucination in multi-image scenarios largely unexplored. To address this gap, we conduct the first systematic study of hallucinations in multi-image MLLMs and propose MIHBench, a benchmark specifically tailored for evaluating object-related hallucinations across multiple images. MIHBench comprises three core tasks: Multi-Image Object Existence Hallucination, Multi-Image Object Count Hallucination, and Object Identity Consistency Hallucination, targeting semantic understanding across object existence, quantity reasoning, and cross-view identity consistency. Through extensive evaluation, we identify key factors associated with the occurrence of multi-image hallucinations, including: a progressive relationship between the number of image inputs and the likelihood of hallucination occurrences; a strong correlation between single-image hallucination tendencies and those observed in multi-image contexts; and the influence of same-object image ratios and the positional placement of negative samples within image sequences on the occurrence of object identity consistency hallucination. To address these challenges, we propose a Dynamic Attention Balancing mechanism that adjusts inter-image attention distributions while preserving the overall visual attention proportion. Experiments across multiple state-of-the-art MLLMs demonstrate that our method effectively reduces hallucination occurrences and enhances semantic integration and reasoning stability in multi-image scenarios.
AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models
Jul 03, 2025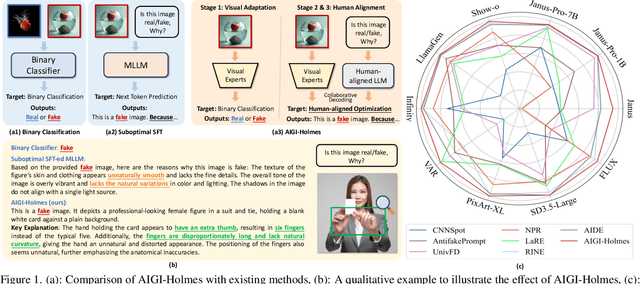
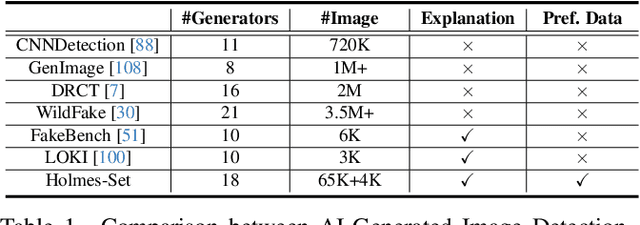
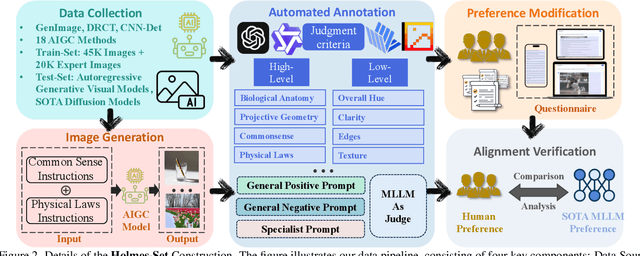
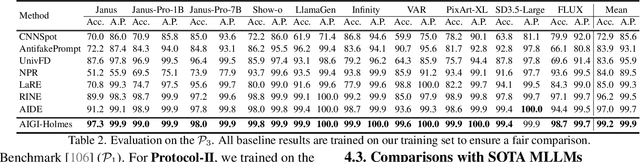
The rapid development of AI-generated content (AIGC) technology has led to the misuse of highly realistic AI-generated images (AIGI) in spreading misinformation, posing a threat to public information security. Although existing AIGI detection techniques are generally effective, they face two issues: 1) a lack of human-verifiable explanations, and 2) a lack of generalization in the latest generation technology. To address these issues, we introduce a large-scale and comprehensive dataset, Holmes-Set, which includes the Holmes-SFTSet, an instruction-tuning dataset with explanations on whether images are AI-generated, and the Holmes-DPOSet, a human-aligned preference dataset. Our work introduces an efficient data annotation method called the Multi-Expert Jury, enhancing data generation through structured MLLM explanations and quality control via cross-model evaluation, expert defect filtering, and human preference modification. In addition, we propose Holmes Pipeline, a meticulously designed three-stage training framework comprising visual expert pre-training, supervised fine-tuning, and direct preference optimization. Holmes Pipeline adapts multimodal large language models (MLLMs) for AIGI detection while generating human-verifiable and human-aligned explanations, ultimately yielding our model AIGI-Holmes. During the inference stage, we introduce a collaborative decoding strategy that integrates the model perception of the visual expert with the semantic reasoning of MLLMs, further enhancing the generalization capabilities. Extensive experiments on three benchmarks validate the effectiveness of our AIGI-Holmes.
RePrompt: Reasoning-Augmented Reprompting for Text-to-Image Generation via Reinforcement Learning
May 23, 2025Despite recent progress in text-to-image (T2I) generation, existing models often struggle to faithfully capture user intentions from short and under-specified prompts. While prior work has attempted to enhance prompts using large language models (LLMs), these methods frequently generate stylistic or unrealistic content due to insufficient grounding in visual semantics and real-world composition. Inspired by recent advances in reasoning for language model, we propose RePrompt, a novel reprompting framework that introduces explicit reasoning into the prompt enhancement process via reinforcement learning. Instead of relying on handcrafted rules or stylistic rewrites, our method trains a language model to generate structured, self-reflective prompts by optimizing for image-level outcomes. The tailored reward models assesse the generated images in terms of human preference, semantic alignment, and visual composition, providing indirect supervision to refine prompt generation. Our approach enables end-to-end training without human-annotated data. Experiments on GenEval and T2I-Compbench show that RePrompt significantly boosts spatial layout fidelity and compositional generalization across diverse T2I backbones, establishing new state-of-the-art results.
Zooming In on Fakes: A Novel Dataset for Localized AI-Generated Image Detection with Forgery Amplification Approach
Apr 16, 2025



The rise of AI-generated image editing tools has made localized forgeries increasingly realistic, posing challenges for visual content integrity. Although recent efforts have explored localized AIGC detection, existing datasets predominantly focus on object-level forgeries while overlooking broader scene edits in regions such as sky or ground. To address these limitations, we introduce \textbf{BR-Gen}, a large-scale dataset of 150,000 locally forged images with diverse scene-aware annotations, which are based on semantic calibration to ensure high-quality samples. BR-Gen is constructed through a fully automated Perception-Creation-Evaluation pipeline to ensure semantic coherence and visual realism. In addition, we further propose \textbf{NFA-ViT}, a Noise-guided Forgery Amplification Vision Transformer that enhances the detection of localized forgeries by amplifying forgery-related features across the entire image. NFA-ViT mines heterogeneous regions in images, \emph{i.e.}, potential edited areas, by noise fingerprints. Subsequently, attention mechanism is introduced to compel the interaction between normal and abnormal features, thereby propagating the generalization traces throughout the entire image, allowing subtle forgeries to influence a broader context and improving overall detection robustness. Extensive experiments demonstrate that BR-Gen constructs entirely new scenarios that are not covered by existing methods. Take a step further, NFA-ViT outperforms existing methods on BR-Gen and generalizes well across current benchmarks. All data and codes are available at https://github.com/clpbc/BR-Gen.
An Efficient and Mixed Heterogeneous Model for Image Restoration
Apr 15, 2025Image restoration~(IR), as a fundamental multimedia data processing task, has a significant impact on downstream visual applications. In recent years, researchers have focused on developing general-purpose IR models capable of handling diverse degradation types, thereby reducing the cost and complexity of model development. Current mainstream approaches are based on three architectural paradigms: CNNs, Transformers, and Mambas. CNNs excel in efficient inference, whereas Transformers and Mamba excel at capturing long-range dependencies and modeling global contexts. While each architecture has demonstrated success in specialized, single-task settings, limited efforts have been made to effectively integrate heterogeneous architectures to jointly address diverse IR challenges. To bridge this gap, we propose RestorMixer, an efficient and general-purpose IR model based on mixed-architecture fusion. RestorMixer adopts a three-stage encoder-decoder structure, where each stage is tailored to the resolution and feature characteristics of the input. In the initial high-resolution stage, CNN-based blocks are employed to rapidly extract shallow local features. In the subsequent stages, we integrate a refined multi-directional scanning Mamba module with a multi-scale window-based self-attention mechanism. This hierarchical and adaptive design enables the model to leverage the strengths of CNNs in local feature extraction, Mamba in global context modeling, and attention mechanisms in dynamic feature refinement. Extensive experimental results demonstrate that RestorMixer achieves leading performance across multiple IR tasks while maintaining high inference efficiency. The official code can be accessed at https://github.com/ClimBin/RestorMixer.
Exploring the Collaborative Advantage of Low-level Information on Generalizable AI-Generated Image Detection
Apr 01, 2025



Existing state-of-the-art AI-Generated image detection methods mostly consider extracting low-level information from RGB images to help improve the generalization of AI-Generated image detection, such as noise patterns. However, these methods often consider only a single type of low-level information, which may lead to suboptimal generalization. Through empirical analysis, we have discovered a key insight: different low-level information often exhibits generalization capabilities for different types of forgeries. Furthermore, we found that simple fusion strategies are insufficient to leverage the detection advantages of each low-level and high-level information for various forgery types. Therefore, we propose the Adaptive Low-level Experts Injection (ALEI) framework. Our approach introduces Lora Experts, enabling the backbone network, which is trained with high-level semantic RGB images, to accept and learn knowledge from different low-level information. We utilize a cross-attention method to adaptively fuse these features at intermediate layers. To prevent the backbone network from losing the modeling capabilities of different low-level features during the later stages of modeling, we developed a Low-level Information Adapter that interacts with the features extracted by the backbone network. Finally, we propose Dynamic Feature Selection, which dynamically selects the most suitable features for detecting the current image to maximize generalization detection capability. Extensive experiments demonstrate that our method, finetuned on only four categories of mainstream ProGAN data, performs excellently and achieves state-of-the-art results on multiple datasets containing unseen GAN and Diffusion methods.