 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D ShapeNets: A Deep Representation for Volumetric Shapes
Apr 15, 2015



3D shape is a crucial but heavily underutilized cue in today's computer vision systems, mostly due to the lack of a good generic shape representation. With the recent availability of inexpensive 2.5D depth sensors (e.g. Microsoft Kinect), it is becoming increasingly important to have a powerful 3D shape representation in the loop. Apart from category recognition, recovering full 3D shapes from view-based 2.5D depth maps is also a critical part of visual understanding. To this end, we propose to represent a geometric 3D shape as a probability distribution of binary variables on a 3D voxel grid, using a Convolutional Deep Belief Network. Our model, 3D ShapeNets, learns the distribution of complex 3D shapes across different object categories and arbitrary poses from raw CAD data, and discovers hierarchical compositional part representations automatically. It naturally supports joint object recognition and shape completion from 2.5D depth maps, and it enables active object recognition through view planning. To train our 3D deep learning model, we construct ModelNet -- a large-scale 3D CAD model dataset. Extensive experiments show that our 3D deep representation enables significant performance improvement over the-state-of-the-arts in a variety of tasks.
DeepID3: Face Recognition with Very Deep Neural Networks
Feb 03, 2015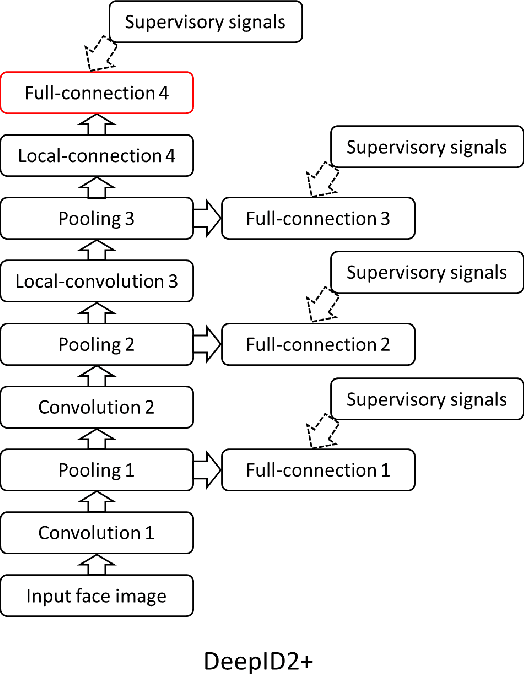
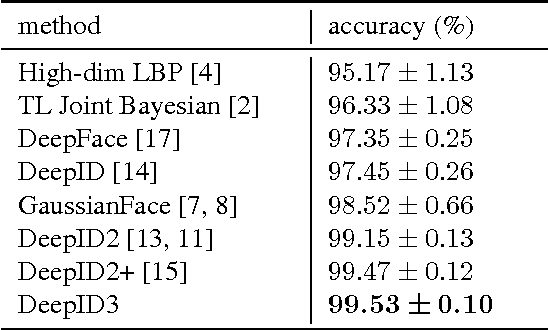
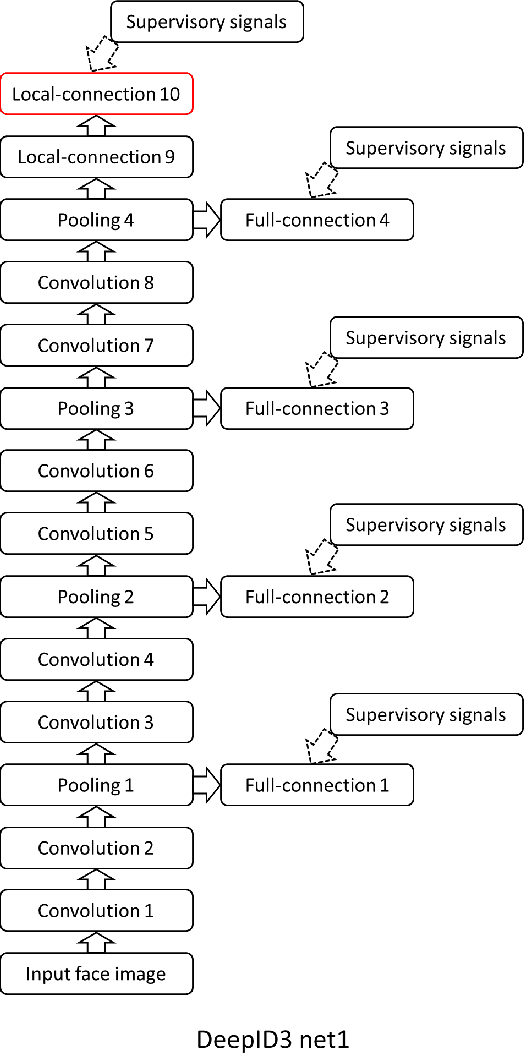
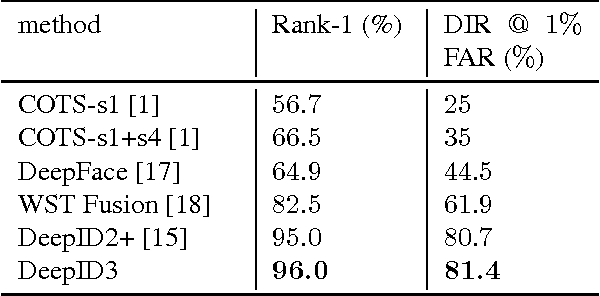
The state-of-the-art of face recognition has been significantly advanced by the emergence of deep learning. Very deep neural networks recently achieved great success on general object recognition because of their superb learning capacity. This motivates us to investigate their effectiveness on face recognition. This paper proposes two very deep neural network architectures, referred to as DeepID3, for face recognition. These two architectures are rebuilt from stacked convolution and inception layers proposed in VGG net and GoogLeNet to make them suitable to face recognition. Joint face identification-verification supervisory signals are added to both intermediate and final feature extraction layers during training. An ensemble of the proposed two architectures achieves 99.53% LFW face verification accuracy and 96.0% LFW rank-1 face identification accuracy, respectively. A further discussion of LFW face verification result is given in the end.
Surpassing Human-Level Face Verification Performance on LFW with GaussianFace
Dec 20, 2014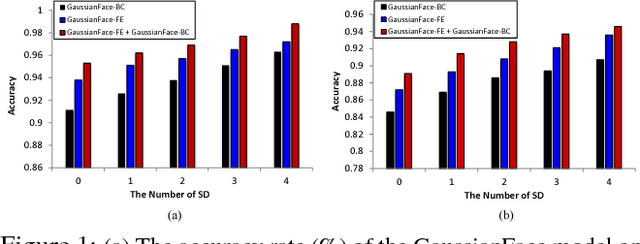
Face verification remains a challenging problem in very complex conditions with large variations such as pose, illumination, expression, and occlusions. This problem is exacerbated when we rely unrealistically on a single training data source, which is often insufficient to cover the intrinsically complex face variations. This paper proposes a principled multi-task learning approach based on Discriminative Gaussian Process Latent Variable Model, named GaussianFace, to enrich the diversity of training data. In comparison to existing methods, our model exploits additional data from multiple source-domains to improve the generalization performance of face verification in an unknown target-domain. Importantly, our model can adapt automatically to complex data distributions, and therefore can well capture complex face variations inherent in multiple sources. Extensive experiments demonstrate the effectiveness of the proposed model in learning from diverse data sources and generalize to unseen domain. Specifically, the accuracy of our algorithm achieves an impressive accuracy rate of 98.52% on the well-known and challenging Labeled Faces in the Wild (LFW) benchmark. For the first time, the human-level performance in face verification (97.53%) on LFW is surpassed.
Deeply learned face representations are sparse, selective, and robust
Dec 03, 2014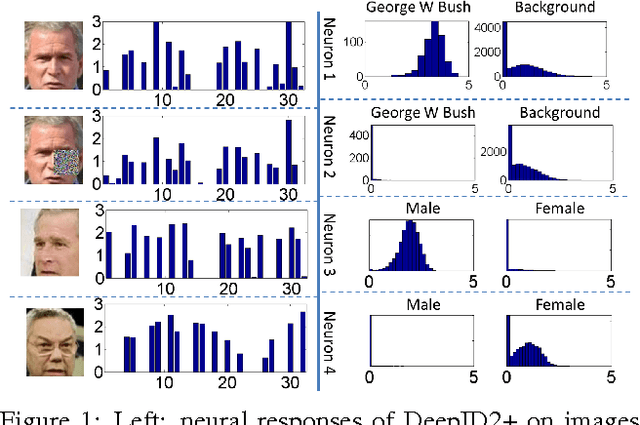
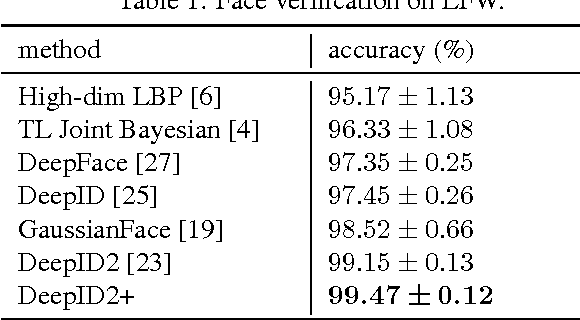
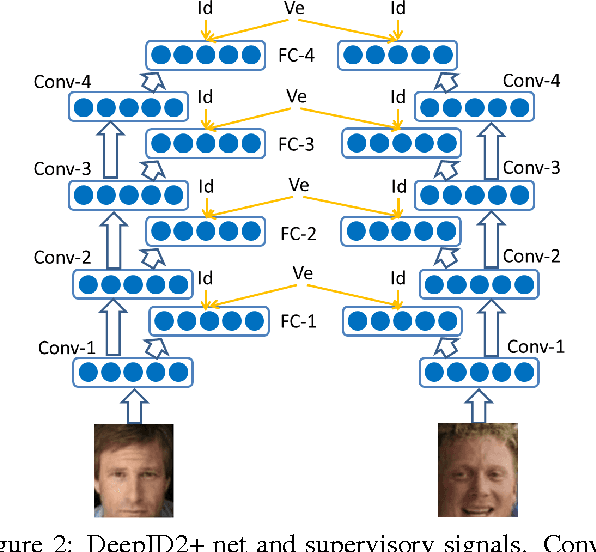
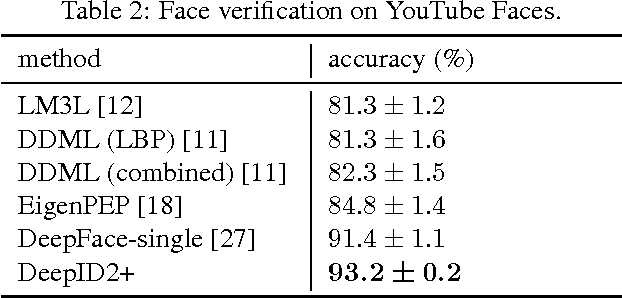
This paper designs a high-performance deep convolutional network (DeepID2+) for face recognition. It is learned with the identification-verification supervisory signal. By increasing the dimension of hidden representations and adding supervision to early convolutional layers, DeepID2+ achieves new state-of-the-art on LFW and YouTube Faces benchmarks. Through empirical studies, we have discovered three properties of its deep neural activations critical for the high performance: sparsity, selectiveness and robustness. (1) It is observed that neural activations are moderately sparse. Moderate sparsity maximizes the discriminative power of the deep net as well as the distance between images. It is surprising that DeepID2+ still can achieve high recognition accuracy even after the neural responses are binarized. (2) Its neurons in higher layers are highly selective to identities and identity-related attributes. We can identify different subsets of neurons which are either constantly excited or inhibited when different identities or attributes are present. Although DeepID2+ is not taught to distinguish attributes during training, it has implicitly learned such high-level concepts. (3) It is much more robust to occlusions, although occlusion patterns are not included in the training set.
Pedestrian Detection aided by Deep Learning Semantic Tasks
Nov 29, 2014
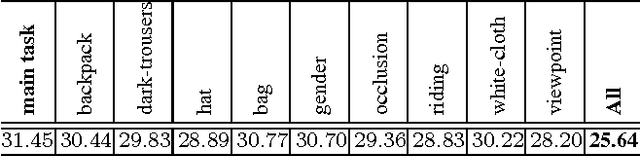
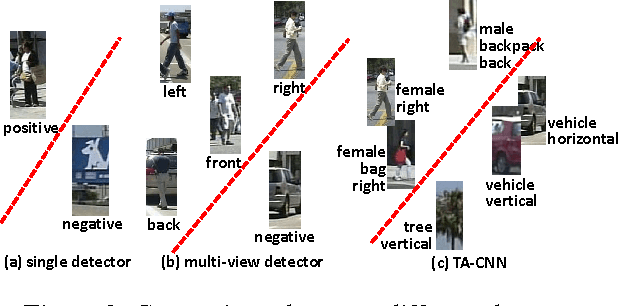
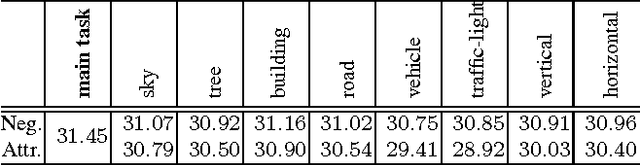
Deep learning methods have achieved great success in pedestrian detection, owing to its ability to learn features from raw pixels. However, they mainly capture middle-level representations, such as pose of pedestrian, but confuse positive with hard negative samples, which have large ambiguity, e.g. the shape and appearance of `tree trunk' or `wire pole' are similar to pedestrian in certain viewpoint. This ambiguity can be distinguished by high-level representation. To this end, this work jointly optimizes pedestrian detection with semantic tasks, including pedestrian attributes (e.g. `carrying backpack') and scene attributes (e.g. `road', `tree', and `horizontal'). Rather than expensively annotating scene attributes, we transfer attributes information from existing scene segmentation datasets to the pedestrian dataset, by proposing a novel deep model to learn high-level features from multiple tasks and multiple data sources. Since distinct tasks have distinct convergence rates and data from different datasets have different distributions, a multi-task objective function is carefully designed to coordinate tasks and reduce discrepancies among datasets. The importance coefficients of tasks and network parameters in this objective function can be iteratively estimated. Extensive evaluations show that the proposed approach outperforms the state-of-the-art on the challenging Caltech and ETH datasets, where it reduces the miss rates of previous deep models by 17 and 5.5 percent, respectively.
DeepID-Net: multi-stage and deformable deep convolutional neural networks for object detection
Sep 11, 2014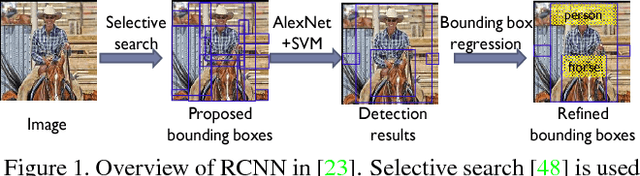
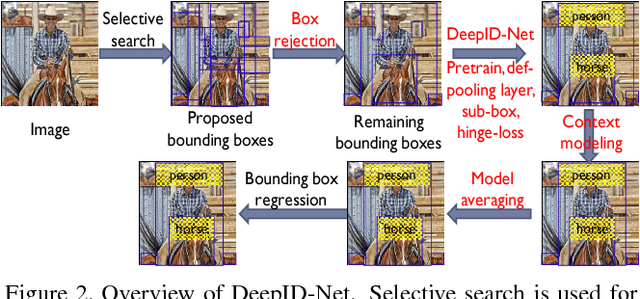

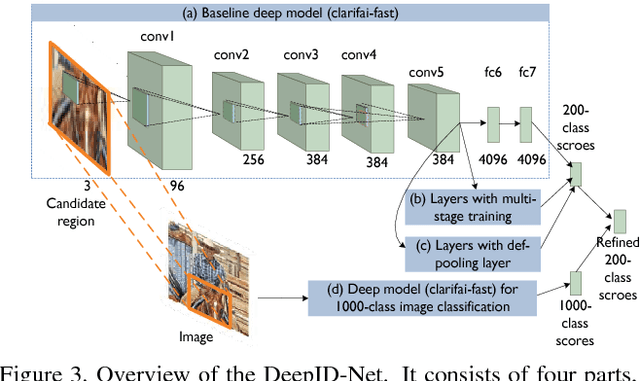
In this paper, we propose multi-stage and deformable deep convolutional neural networks for object detection. This new deep learning object detection diagram has innovations in multiple aspects. In the proposed new deep architecture, a new deformation constrained pooling (def-pooling) layer models the deformation of object parts with geometric constraint and penalty. With the proposed multi-stage training strategy, multiple classifiers are jointly optimized to process samples at different difficulty levels. A new pre-training strategy is proposed to learn feature representations more suitable for the object detection task and with good generalization capability. By changing the net structures, training strategies, adding and removing some key components in the detection pipeline, a set of models with large diversity are obtained, which significantly improves the effectiveness of modeling averaging. The proposed approach ranked \#2 in ILSVRC 2014. It improves the mean averaged precision obtained by RCNN, which is the state-of-the-art of object detection, from $31\%$ to $45\%$. Detailed component-wise analysis is also provided through extensive experimental evaluation.
Transferring Landmark Annotations for Cross-Dataset Face Alignment
Sep 02, 2014

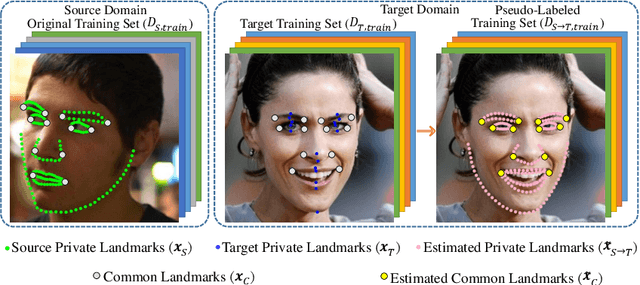

Dataset bias is a well known problem in object recognition domain. This issue, nonetheless, is rarely explored in face alignment research. In this study, we show that dataset plays an integral part of face alignment performance. Specifically, owing to face alignment dataset bias, training on one database and testing on another or unseen domain would lead to poor performance. Creating an unbiased dataset through combining various existing databases, however, is non-trivial as one has to exhaustively re-label the landmarks for standardisation. In this work, we propose a simple and yet effective method to bridge the disparate annotation spaces between databases, making datasets fusion possible. We show extensive results on combining various popular databases (LFW, AFLW, LFPW, HELEN) for improved cross-dataset and unseen data alignment.
Homophilic Clustering by Locally Asymmetric Geometry
Jul 05, 2014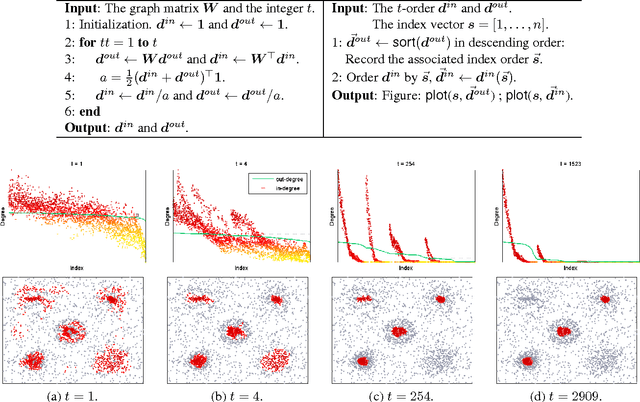

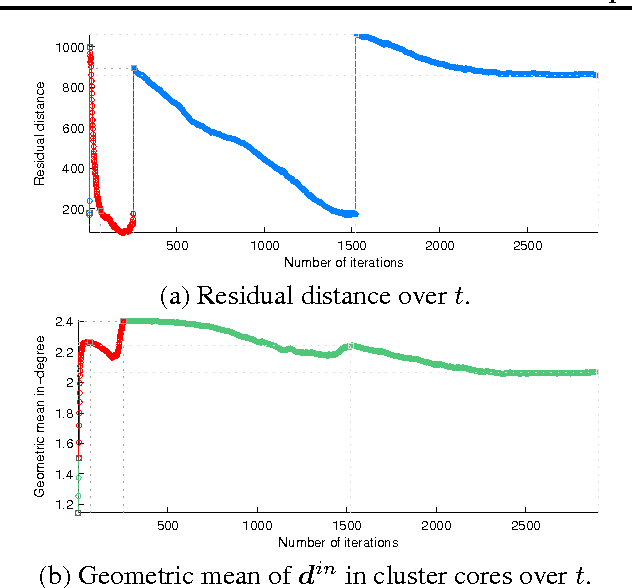
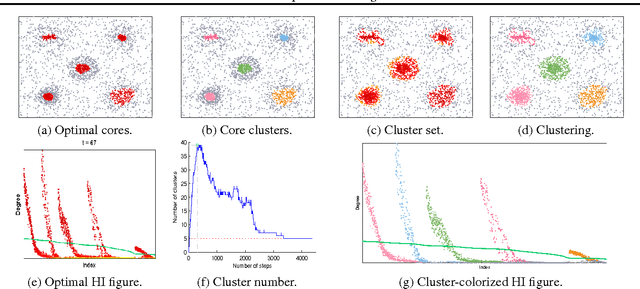
Clustering is indispensable for data analysis in many scientific disciplines. Detecting clusters from heavy noise remains challenging, particularly for high-dimensional sparse data. Based on graph-theoretic framework, the present paper proposes a novel algorithm to address this issue. The locally asymmetric geometries of neighborhoods between data points result in a directed similarity graph to model the structural connectivity of data points. Performing similarity propagation on this directed graph simply by its adjacency matrix powers leads to an interesting discovery, in the sense that if the in-degrees are ordered by the corresponding sorted out-degrees, they will be self-organized to be homophilic layers according to the different distributions of cluster densities, which is dubbed the Homophilic In-degree figure (the HI figure). With the HI figure, we can easily single out all cores of clusters, identify the boundary between cluster and noise, and visualize the intrinsic structures of clusters. Based on the in-degree homophily, we also develop a simple efficient algorithm of linear space complexity to cluster noisy data. Extensive experiments on toy and real-world scientific data validate the effectiveness of our algorithms.
Deep Learning Multi-View Representation for Face Recognition
Jun 26, 2014
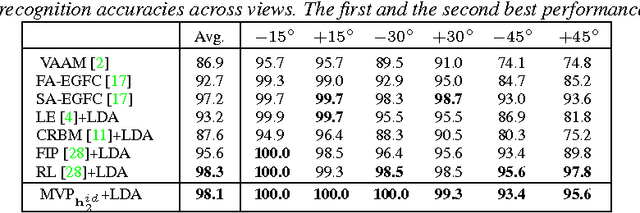
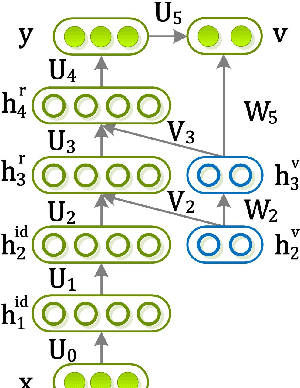
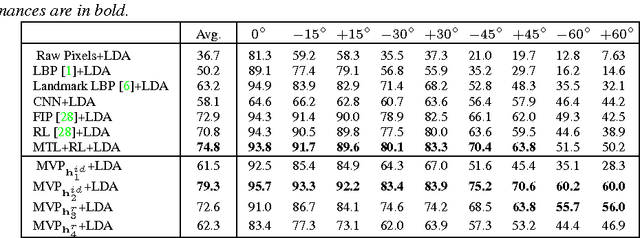
Various factors, such as identities, views (poses), and illuminations, are coupled in face images. Disentangling the identity and view representations is a major challenge in face recognition. Existing face recognition systems either use handcrafted features or learn features discriminatively to improve recognition accuracy. This is different from the behavior of human brain. Intriguingly, even without accessing 3D data, human not only can recognize face identity, but can also imagine face images of a person under different viewpoints given a single 2D image, making face perception in the brain robust to view changes. In this sense, human brain has learned and encoded 3D face models from 2D images. To take into account this instinct, this paper proposes a novel deep neural net, named multi-view perceptron (MVP), which can untangle the identity and view features, and infer a full spectrum of multi-view images in the meanwhile, given a single 2D face image. The identity features of MVP achieve superior performance on the MultiPIE dataset. MVP is also capable to interpolate and predict images under viewpoints that are unobserved in the training data.
Deep Learning Face Representation by Joint Identification-Verification
Jun 18, 2014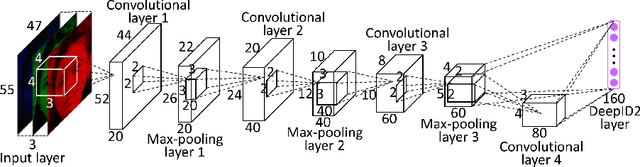


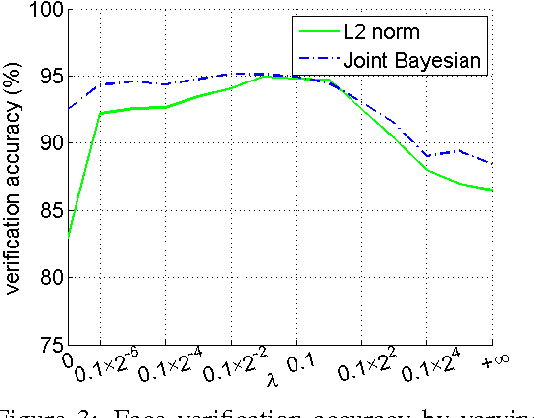
The key challenge of face recognition is to develop effective feature representations for reducing intra-personal variations while enlarging inter-personal differences. In this paper, we show that it can be well solved with deep learning and using both face identification and verification signals as supervision. The Deep IDentification-verification features (DeepID2) are learned with carefully designed deep convolutional networks. The face identification task increases the inter-personal variations by drawing DeepID2 extracted from different identities apart, while the face verification task reduces the intra-personal variations by pulling DeepID2 extracted from the same identity together, both of which are essential to face recognition. The learned DeepID2 features can be well generalized to new identities unseen in the training data. On the challenging LFW dataset, 99.15% face verification accuracy is achieved. Compared with the best deep learning result on LFW, the error rate has been significantly reduced by 67%.