 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Disambiguate by Asking Discriminative Questions
Aug 09, 2017


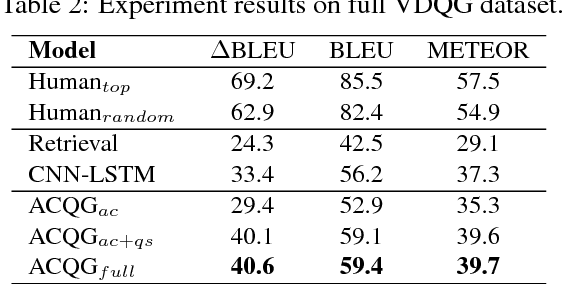
The ability to ask questions is a powerful tool to gather information in order to learn about the world and resolve ambiguities. In this paper, we explore a novel problem of generating discriminative questions to help disambiguate visual instances. Our work can be seen as a complement and new extension to the rich research studies on image captioning and question answering. We introduce the first large-scale dataset with over 10,000 carefully annotated images-question tuples to facilitate benchmarking. In particular, each tuple consists of a pair of images and 4.6 discriminative questions (as positive samples) and 5.9 non-discriminative questions (as negative samples) on average. In addition, we present an effective method for visual discriminative question generation. The method can be trained in a weakly supervised manner without discriminative images-question tuples but just existing visual question answering datasets. Promising results are shown against representative baselines through quantitative evaluations and user studies.
DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection
Jun 02, 2015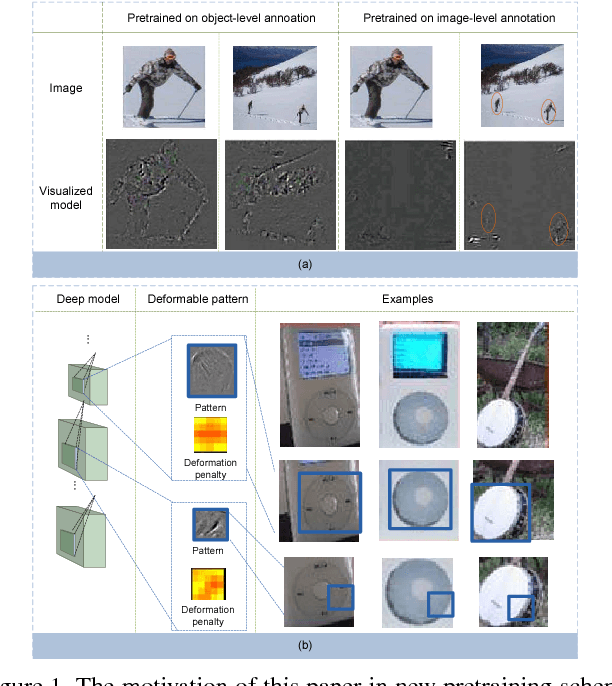
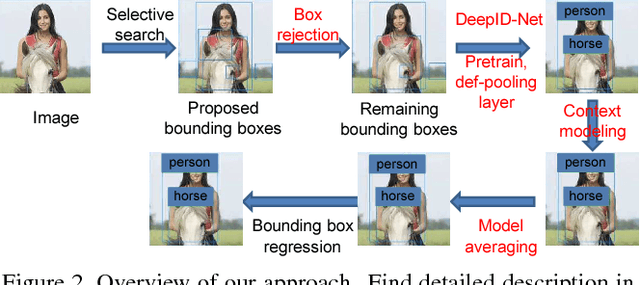
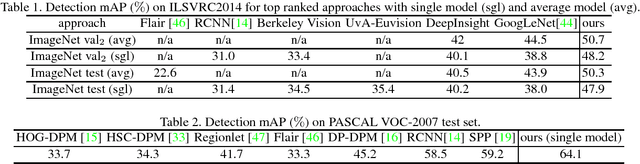
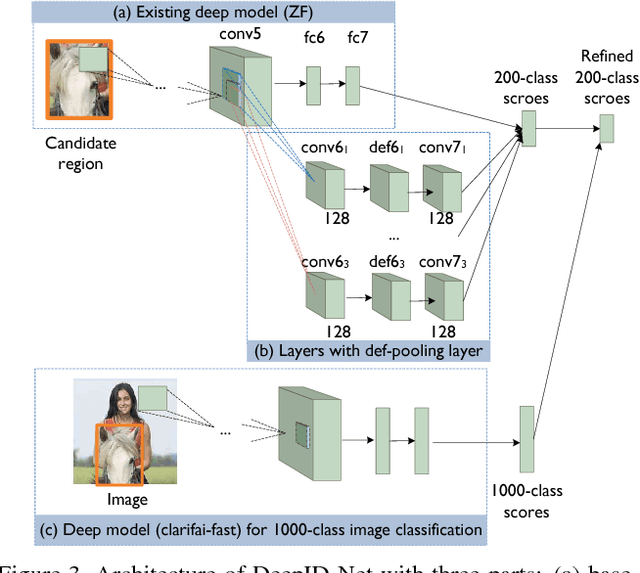
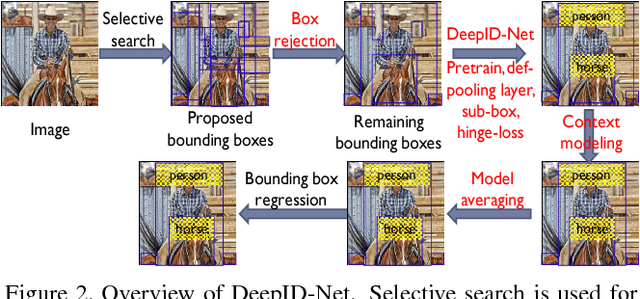
In this paper, we propose deformable deep convolutional neural networks for generic object detection. This new deep learning object detection framework has innovations in multiple aspects. In the proposed new deep architecture, a new deformation constrained pooling (def-pooling) layer models the deformation of object parts with geometric constraint and penalty. A new pre-training strategy is proposed to learn feature representations more suitable for the object detection task and with good generalization capability. By changing the net structures, training strategies, adding and removing some key components in the detection pipeline, a set of models with large diversity are obtained, which significantly improves the effectiveness of model averaging. The proposed approach improves the mean averaged precision obtained by RCNN \cite{girshick2014rich}, which was the state-of-the-art, from 31\% to 50.3\% on the ILSVRC2014 detection test set. It also outperforms the winner of ILSVRC2014, GoogLeNet, by 6.1\%. Detailed component-wise analysis is also provided through extensive experimental evaluation, which provide a global view for people to understand the deep learning object detection pipeline.
DeepID-Net: multi-stage and deformable deep convolutional neural networks for object detection
Sep 11, 2014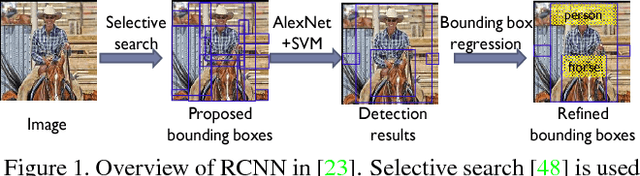

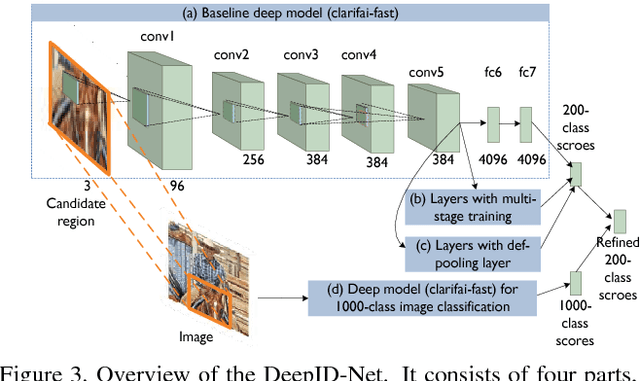
In this paper, we propose multi-stage and deformable deep convolutional neural networks for object detection. This new deep learning object detection diagram has innovations in multiple aspects. In the proposed new deep architecture, a new deformation constrained pooling (def-pooling) layer models the deformation of object parts with geometric constraint and penalty. With the proposed multi-stage training strategy, multiple classifiers are jointly optimized to process samples at different difficulty levels. A new pre-training strategy is proposed to learn feature representations more suitable for the object detection task and with good generalization capability. By changing the net structures, training strategies, adding and removing some key components in the detection pipeline, a set of models with large diversity are obtained, which significantly improves the effectiveness of modeling averaging. The proposed approach ranked \#2 in ILSVRC 2014. It improves the mean averaged precision obtained by RCNN, which is the state-of-the-art of object detection, from $31\%$ to $45\%$. Detailed component-wise analysis is also provided through extensive experimental evaluation.