 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Attention Network for Image Classification
Apr 23, 2017
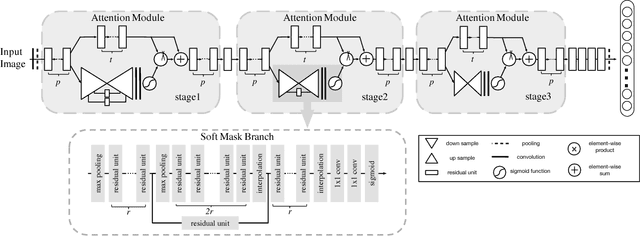
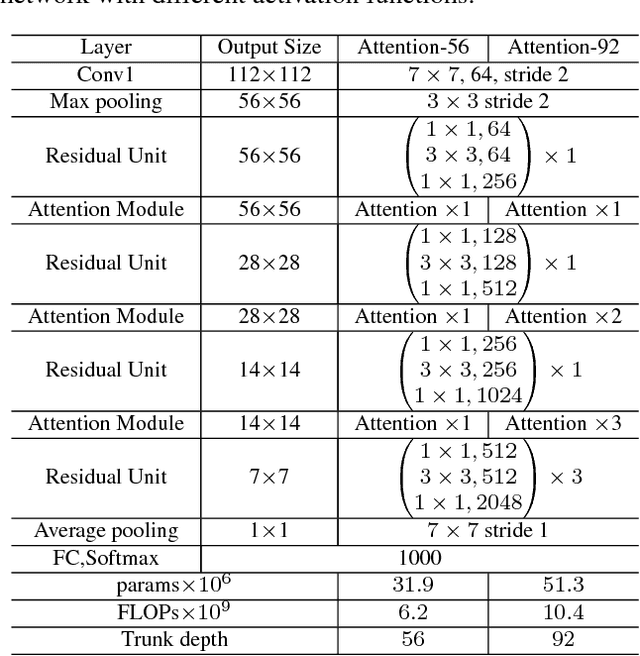
In this work, we propose "Residual Attention Network", a convolutional neural network using attention mechanism which can incorporate with state-of-art feed forward network architecture in an end-to-end training fashion. Our Residual Attention Network is built by stacking Attention Modules which generate attention-aware features. The attention-aware features from different modules change adaptively as layers going deeper. Inside each Attention Module, bottom-up top-down feedforward structure is used to unfold the feedforward and feedback attention process into a single feedforward process. Importantly, we propose attention residual learning to train very deep Residual Attention Networks which can be easily scaled up to hundreds of layers. Extensive analyses are conducted on CIFAR-10 and CIFAR-100 datasets to verify the effectiveness of every module mentioned above. Our Residual Attention Network achieves state-of-the-art object recognition performance on three benchmark datasets including CIFAR-10 (3.90% error), CIFAR-100 (20.45% error) and ImageNet (4.8% single model and single crop, top-5 error). Note that, our method achieves 0.6% top-1 accuracy improvement with 46% trunk depth and 69% forward FLOPs comparing to ResNet-200. The experiment also demonstrates that our network is robust against noisy labels.
Image Aesthetic Assessment: An Experimental Survey
Apr 20, 2017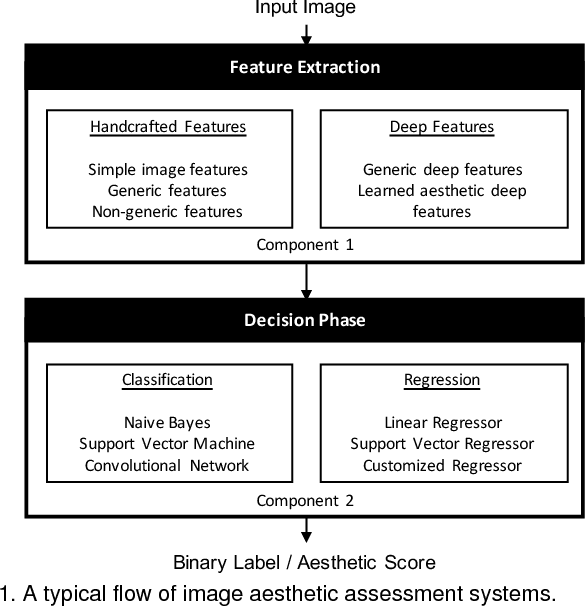
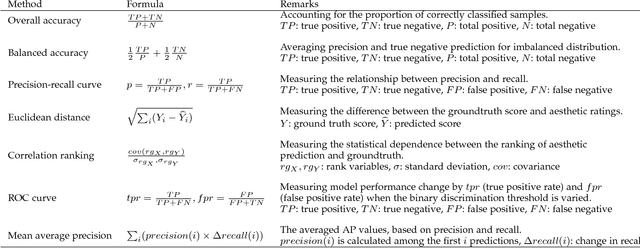


This survey aims at reviewing recent computer vision techniques used in the assessment of image aesthetic quality. Image aesthetic assessment aims at computationally distinguishing high-quality photos from low-quality ones based on photographic rules, typically in the form of binary classification or quality scoring. A variety of approaches has been proposed in the literature trying to solve this challenging problem. In this survey, we present a systematic listing of the reviewed approaches based on visual feature types (hand-crafted features and deep features) and evaluation criteria (dataset characteristics and evaluation metrics). Main contributions and novelties of the reviewed approaches are highlighted and discussed. In addition, following the emergence of deep learning techniques, we systematically evaluate recent deep learning settings that are useful for developing a robust deep model for aesthetic scoring. Experiments are conducted using simple yet solid baselines that are competitive with the current state-of-the-arts. Moreover, we discuss the possibility of manipulating the aesthetics of images through computational approaches. We hope that our survey could serve as a comprehensive reference source for future research on the study of image aesthetic assessment.
Not All Pixels Are Equal: Difficulty-aware Semantic Segmentation via Deep Layer Cascade
Apr 05, 2017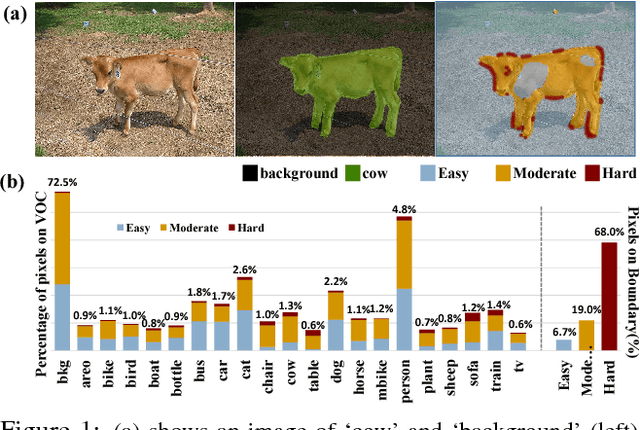
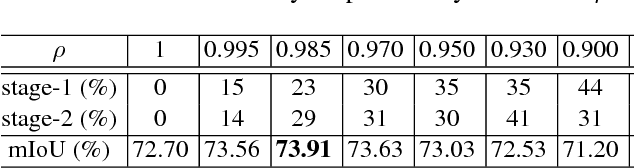
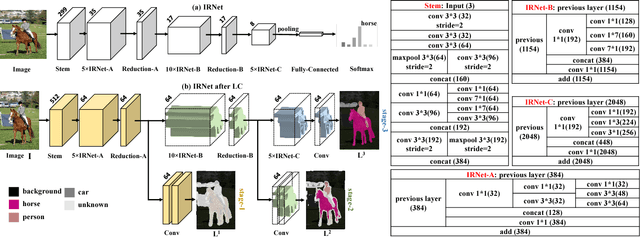
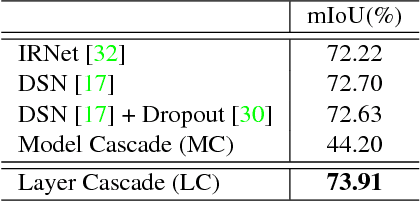
We propose a novel deep layer cascade (LC) method to improve the accuracy and speed of semantic segmentation. Unlike the conventional model cascade (MC) that is composed of multiple independent models, LC treats a single deep model as a cascade of several sub-models. Earlier sub-models are trained to handle easy and confident regions, and they progressively feed-forward harder regions to the next sub-model for processing. Convolutions are only calculated on these regions to reduce computations. The proposed method possesses several advantages. First, LC classifies most of the easy regions in the shallow stage and makes deeper stage focuses on a few hard regions. Such an adaptive and 'difficulty-aware' learning improves segmentation performance. Second, LC accelerates both training and testing of deep network thanks to early decisions in the shallow stage. Third, in comparison to MC, LC is an end-to-end trainable framework, allowing joint learning of all sub-models. We evaluate our method on PASCAL VOC and Cityscapes datasets, achieving state-of-the-art performance and fast speed.
A Pursuit of Temporal Accuracy in General Activity Detection
Mar 08, 2017
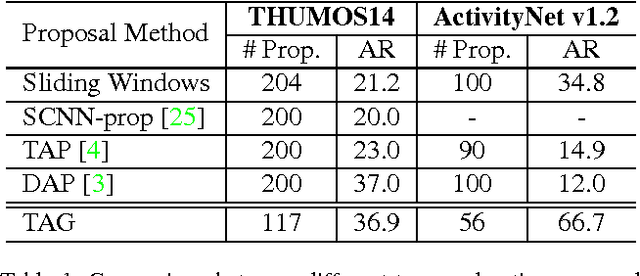
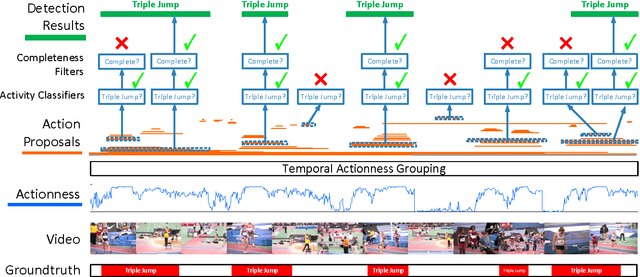
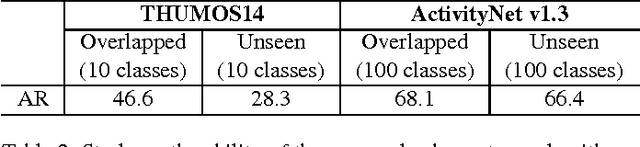
Detecting activities in untrimmed videos is an important but challenging task. The performance of existing methods remains unsatisfactory, e.g., they often meet difficulties in locating the beginning and end of a long complex action. In this paper, we propose a generic framework that can accurately detect a wide variety of activities from untrimmed videos. Our first contribution is a novel proposal scheme that can efficiently generate candidates with accurate temporal boundaries. The other contribution is a cascaded classification pipeline that explicitly distinguishes between relevance and completeness of a candidate instance. On two challenging temporal activity detection datasets, THUMOS14 and ActivityNet, the proposed framework significantly outperforms the existing state-of-the-art methods, demonstrating superior accuracy and strong adaptivity in handling activities with various temporal structures.
Local Similarity-Aware Deep Feature Embedding
Oct 27, 2016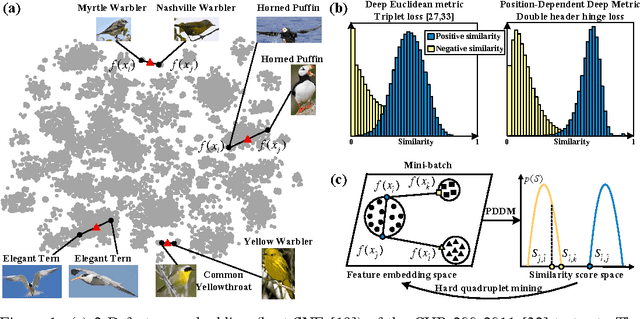
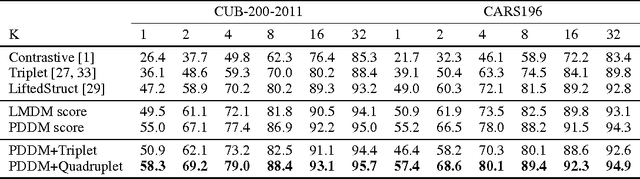
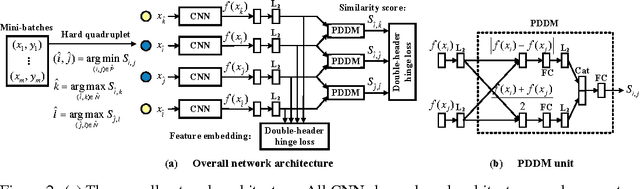

Existing deep embedding methods in vision tasks are capable of learning a compact Euclidean space from images, where Euclidean distances correspond to a similarity metric. To make learning more effective and efficient, hard sample mining is usually employed, with samples identified through computing the Euclidean feature distance. However, the global Euclidean distance cannot faithfully characterize the true feature similarity in a complex visual feature space, where the intraclass distance in a high-density region may be larger than the interclass distance in low-density regions. In this paper, we introduce a Position-Dependent Deep Metric (PDDM) unit, which is capable of learning a similarity metric adaptive to local feature structure. The metric can be used to select genuinely hard samples in a local neighborhood to guide the deep embedding learning in an online and robust manner. The new layer is appealing in that it is pluggable to any convolutional networks and is trained end-to-end. Our local similarity-aware feature embedding not only demonstrates faster convergence and boosted performance on two complex image retrieval datasets, its large margin nature also leads to superior generalization results under the large and open set scenarios of transfer learning and zero-shot learning on ImageNet 2010 and ImageNet-10K datasets.
Deep Markov Random Field for Image Modeling
Sep 07, 2016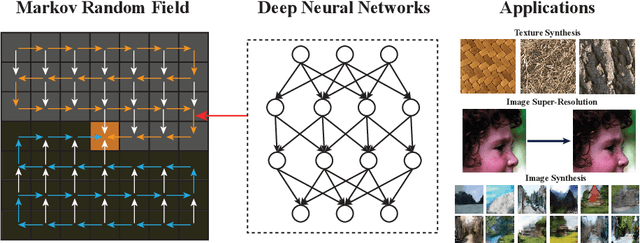
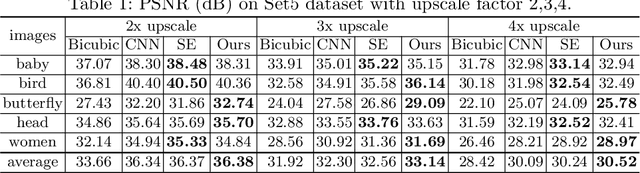
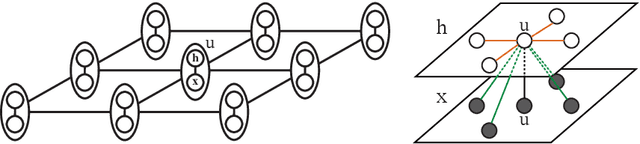
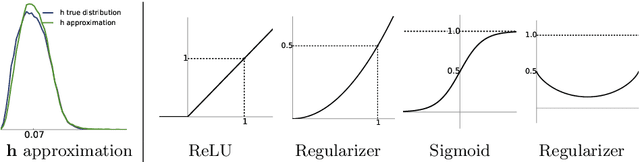
Markov Random Fields (MRFs), a formulation widely used in generative image modeling, have long been plagued by the lack of expressive power. This issue is primarily due to the fact that conventional MRFs formulations tend to use simplistic factors to capture local patterns. In this paper, we move beyond such limitations, and propose a novel MRF model that uses fully-connected neurons to express the complex interactions among pixels. Through theoretical analysis, we reveal an inherent connection between this model and recurrent neural networks, and thereon derive an approximated feed-forward network that couples multiple RNNs along opposite directions. This formulation combines the expressive power of deep neural networks and the cyclic dependency structure of MRF in a unified model, bringing the modeling capability to a new level. The feed-forward approximation also allows it to be efficiently learned from data. Experimental results on a variety of low-level vision tasks show notable improvement over state-of-the-arts.
Fashion Landmark Detection in the Wild
Aug 10, 2016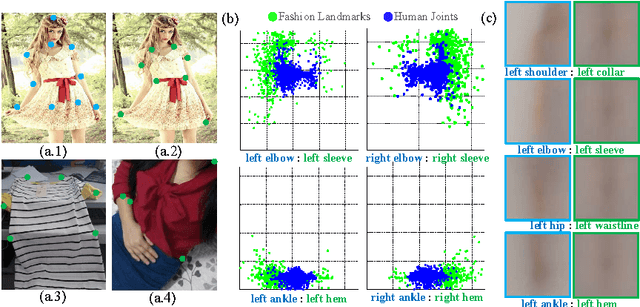

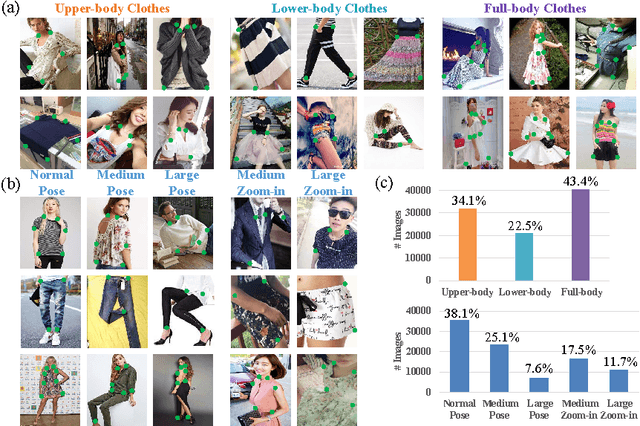
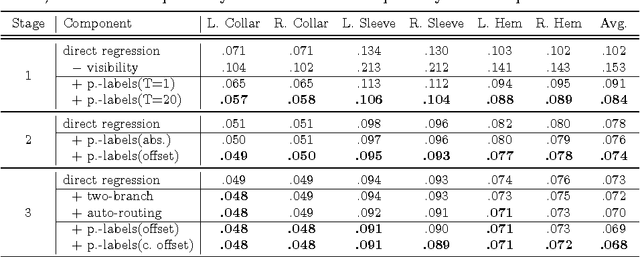
Visual fashion analysis has attracted many attentions in the recent years. Previous work represented clothing regions by either bounding boxes or human joints. This work presents fashion landmark detection or fashion alignment, which is to predict the positions of functional key points defined on the fashion items, such as the corners of neckline, hemline, and cuff. To encourage future studies, we introduce a fashion landmark dataset with over 120K images, where each image is labeled with eight landmarks. With this dataset, we study fashion alignment by cascading multiple convolutional neural networks in three stages. These stages gradually improve the accuracies of landmark predictions. Extensive experiments demonstrate the effectiveness of the proposed method, as well as its generalization ability to pose estimation. Fashion landmark is also compared to clothing bounding boxes and human joints in two applications, fashion attribute prediction and clothes retrieval, showing that fashion landmark is a more discriminative representation to understand fashion images.
Deep Convolution Networks for Compression Artifacts Reduction
Aug 09, 2016



Lossy compression introduces complex compression artifacts, particularly blocking artifacts, ringing effects and blurring. Existing algorithms either focus on removing blocking artifacts and produce blurred output, or restore sharpened images that are accompanied with ringing effects. Inspired by the success of deep convolutional networks (DCN) on superresolution, we formulate a compact and efficient network for seamless attenuation of different compression artifacts. To meet the speed requirement of real-world applications, we further accelerate the proposed baseline model by layer decomposition and joint use of large-stride convolutional and deconvolutional layers. This also leads to a more general CNN framework that has a close relationship with the conventional Multi-Layer Perceptron (MLP). Finally, the modified network achieves a speed up of 7.5 times with almost no performance loss compared to the baseline model. We also demonstrate that a deeper model can be effectively trained with features learned in a shallow network. Following a similar "easy to hard" idea, we systematically investigate three practical transfer settings and show the effectiveness of transfer learning in low-level vision problems. Our method shows superior performance than the state-of-the-art methods both on benchmark datasets and a real-world use case.
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
Aug 02, 2016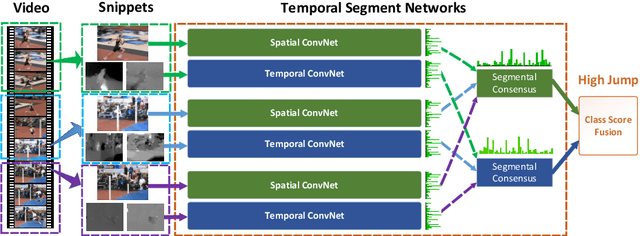
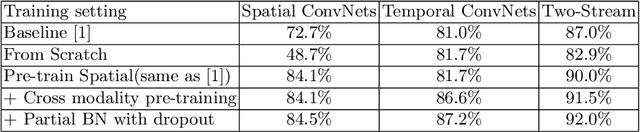


Deep convolutional networks have achieved great success for visual recognition in still images. However, for action recognition in videos, the advantage over traditional methods is not so evident. This paper aims to discover the principles to design effective ConvNet architectures for action recognition in videos and learn these models given limited training samples. Our first contribution is temporal segment network (TSN), a novel framework for video-based action recognition. which is based on the idea of long-range temporal structure modeling. It combines a sparse temporal sampling strategy and video-level supervision to enable efficient and effective learning using the whole action video. The other contribution is our study on a series of good practices in learning ConvNets on video data with the help of temporal segment network. Our approach obtains the state-the-of-art performance on the datasets of HMDB51 ( $ 69.4\% $) and UCF101 ($ 94.2\% $). We also visualize the learned ConvNet models, which qualitatively demonstrates the effectiveness of temporal segment network and the proposed good practices.
CUHK & ETHZ & SIAT Submission to ActivityNet Challenge 2016
Aug 02, 2016
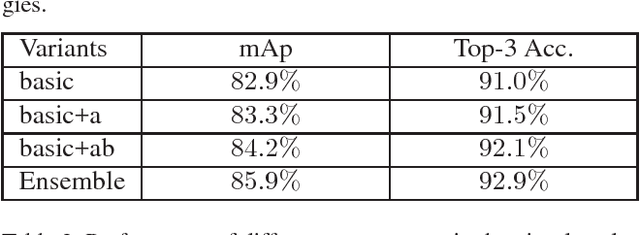
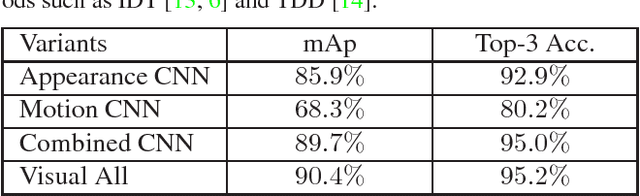
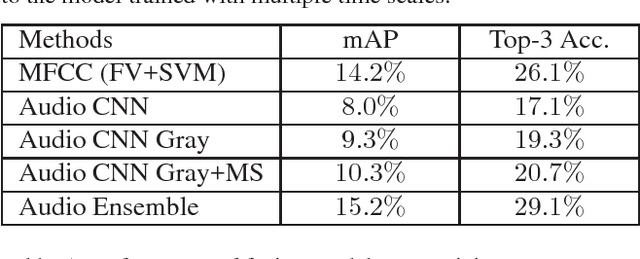
This paper presents the method that underlies our submission to the untrimmed video classification task of ActivityNet Challenge 2016. We follow the basic pipeline of temporal segment networks and further raise the performance via a number of other techniques. Specifically, we use the latest deep model architecture, e.g., ResNet and Inception V3, and introduce new aggregation schemes (top-k and attention-weighted pooling). Additionally, we incorporate the audio as a complementary channel, extracting relevant information via a CNN applied to the spectrograms. With these techniques, we derive an ensemble of deep models, which, together, attains a high classification accuracy (mAP $93.23\%$) on the testing set and secured the first place in the challenge.