 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOTSOFAR-1 Challenge: New Datasets, Baseline, and Tasks for Distant Meeting Transcription
Jan 16, 2024

We introduce the first Natural Office Talkers in Settings of Far-field Audio Recordings (``NOTSOFAR-1'') Challenge alongside datasets and baseline system. The challenge focuses on distant speaker diarization and automatic speech recognition (DASR) in far-field meeting scenarios, with single-channel and known-geometry multi-channel tracks, and serves as a launch platform for two new datasets: First, a benchmarking dataset of 315 meetings, averaging 6 minutes each, capturing a broad spectrum of real-world acoustic conditions and conversational dynamics. It is recorded across 30 conference rooms, featuring 4-8 attendees and a total of 35 unique speakers. Second, a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. The tasks focus on single-device DASR, where multi-channel devices always share the same known geometry. This is aligned with common setups in actual conference rooms, and avoids technical complexities associated with multi-device tasks. It also allows for the development of geometry-specific solutions. The NOTSOFAR-1 Challenge aims to advance research in the field of distant conversational speech recognition, providing key resources to unlock the potential of data-driven methods, which we believe are currently constrained by the absence of comprehensive high-quality training and benchmarking datasets.
ELLA-V: Stable Neural Codec Language Modeling with Alignment-guided Sequence Reordering
Jan 14, 2024



The language model (LM) approach based on acoustic and linguistic prompts, such as VALL-E, has achieved remarkable progress in the field of zero-shot audio generation. However, existing methods still have some limitations: 1) repetitions, transpositions, and omissions in the output synthesized speech due to limited alignment constraints between audio and phoneme tokens; 2) challenges of fine-grained control over the synthesized speech with autoregressive (AR) language model; 3) infinite silence generation due to the nature of AR-based decoding, especially under the greedy strategy. To alleviate these issues, we propose ELLA-V, a simple but efficient LM-based zero-shot text-to-speech (TTS) framework, which enables fine-grained control over synthesized audio at the phoneme level. The key to ELLA-V is interleaving sequences of acoustic and phoneme tokens, where phoneme tokens appear ahead of the corresponding acoustic tokens. The experimental findings reveal that our model outperforms VALL-E in terms of accuracy and delivers more stable results using both greedy and sampling-based decoding strategies. The code of ELLA-V will be open-sourced after cleanups. Audio samples are available at https://ereboas.github.io/ELLAV/.
Convolutional Neural Networks for Segmentation of Malignant Pleural Mesothelioma: Analysis of Probability Map Thresholds (CALGB 30901, Alliance)
Nov 30, 2023Malignant pleural mesothelioma (MPM) is the most common form of mesothelioma. To assess response to treatment, tumor measurements are acquired and evaluated based on a patient's longitudinal computed tomography (CT) scans. Tumor volume, however, is the more accurate metric for assessing tumor burden and response. Automated segmentation methods using deep learning can be employed to acquire volume, which otherwise is a tedious task performed manually. The deep learning-based tumor volume and contours can then be compared with a standard reference to assess the robustness of the automated segmentations. The purpose of this study was to evaluate the impact of probability map threshold on MPM tumor delineations generated using a convolutional neural network (CNN). Eighty-eight CT scans from 21 MPM patients were segmented by a VGG16/U-Net CNN. A radiologist modified the contours generated at a 0.5 probability threshold. Percent difference of tumor volume and overlap using the Dice Similarity Coefficient (DSC) were compared between the standard reference provided by the radiologist and CNN outputs for thresholds ranging from 0.001 to 0.9. CNN annotations consistently yielded smaller tumor volumes than radiologist contours. Reducing the probability threshold from 0.5 to 0.1 decreased the absolute percent volume difference, on average, from 43.96% to 24.18%. Median and mean DSC ranged from 0.58 to 0.60, with a peak at a threshold of 0.5; no distinct threshold was found for percent volume difference. No single output threshold in the CNN probability maps was optimal for both tumor volume and DSC. This work underscores the need to assess tumor volume and spatial overlap when evaluating CNN performance. While automated segmentations may yield comparable tumor volumes to that of the reference standard, the spatial region delineated by the CNN at a specific threshold is equally important.
SCB-ST-Dataset4: Extending the Spatio-Temporal Behavior Dataset in Student Classroom Scenarios Through Image Dataset Method
Oct 25, 2023



Using deep learning methods to detect students' classroom behavior automatically is a promising approach for analyzing their class performance and improving teaching effectiveness. However, the lack of publicly available spatio-temporal datasets on student behavior, as well as the high cost of manually labeling such datasets, pose significant challenges for researchers in this field. To address this issue, we proposed a method for extending the spatio-temporal behavior dataset in Student Classroom Scenarios (SCB-ST-Dataset4) through image dataset. Our SCB-ST-Dataset4 comprises 754094 images with 25670 labels, focusing on 3 behaviors: hand-raising, reading, writing. Our proposed method can rapidly generate spatio-temporal behavioral datasets without requiring annotation. Furthermore, we proposed a Behavior Similarity Index (BSI) to explore the similarity of behaviors. We evaluated the dataset using the YOLOv5, YOLOv7, YOLOv8, and SlowFast algorithms, achieving a mean average precision (map) of up to 82.3%. The experiment further demonstrates the effectiveness of our method. This dataset provides a robust foundation for future research in student behavior detection, potentially contributing to advancements in this field. The SCB-ST-Dataset4 is available for download at: https://github.com/Whiffe/SCB-dataset.
DiariST: Streaming Speech Translation with Speaker Diarization
Sep 14, 2023

End-to-end speech translation (ST) for conversation recordings involves several under-explored challenges such as speaker diarization (SD) without accurate word time stamps and handling of overlapping speech in a streaming fashion. In this work, we propose DiariST, the first streaming ST and SD solution. It is built upon a neural transducer-based streaming ST system and integrates token-level serialized output training and t-vector, which were originally developed for multi-talker speech recognition. Due to the absence of evaluation benchmarks in this area, we develop a new evaluation dataset, DiariST-AliMeeting, by translating the reference Chinese transcriptions of the AliMeeting corpus into English. We also propose new metrics, called speaker-agnostic BLEU and speaker-attributed BLEU, to measure the ST quality while taking SD accuracy into account. Our system achieves a strong ST and SD capability compared to offline systems based on Whisper, while performing streaming inference for overlapping speech. To facilitate the research in this new direction, we release the evaluation data, the offline baseline systems, and the evaluation code.
SpeechX: Neural Codec Language Model as a Versatile Speech Transformer
Aug 14, 2023Recent advancements in generative speech models based on audio-text prompts have enabled remarkable innovations like high-quality zero-shot text-to-speech. However, existing models still face limitations in handling diverse audio-text speech generation tasks involving transforming input speech and processing audio captured in adverse acoustic conditions. This paper introduces SpeechX, a versatile speech generation model capable of zero-shot TTS and various speech transformation tasks, dealing with both clean and noisy signals. SpeechX combines neural codec language modeling with multi-task learning using task-dependent prompting, enabling unified and extensible modeling and providing a consistent way for leveraging textual input in speech enhancement and transformation tasks. Experimental results show SpeechX's efficacy in various tasks, including zero-shot TTS, noise suppression, target speaker extraction, speech removal, and speech editing with or without background noise, achieving comparable or superior performance to specialized models across tasks. See https://aka.ms/speechx for demo samples.
A Comprehensive Study on the Robustness of Image Classification and Object Detection in Remote Sensing: Surveying and Benchmarking
Jun 21, 2023



Deep neural networks (DNNs) have found widespread applications in interpreting remote sensing (RS) imagery. However, it has been demonstrated in previous works that DNNs are vulnerable to different types of noises, particularly adversarial noises. Surprisingly, there has been a lack of comprehensive studies on the robustness of RS tasks, prompting us to undertake a thorough survey and benchmark on the robustness of image classification and object detection in RS. To our best knowledge, this study represents the first comprehensive examination of both natural robustness and adversarial robustness in RS tasks. Specifically, we have curated and made publicly available datasets that contain natural and adversarial noises. These datasets serve as valuable resources for evaluating the robustness of DNNs-based models. To provide a comprehensive assessment of model robustness, we conducted meticulous experiments with numerous different classifiers and detectors, encompassing a wide range of mainstream methods. Through rigorous evaluation, we have uncovered insightful and intriguing findings, which shed light on the relationship between adversarial noise crafting and model training, yielding a deeper understanding of the susceptibility and limitations of various models, and providing guidance for the development of more resilient and robust models
One for All: Unified Workload Prediction for Dynamic Multi-tenant Edge Cloud Platforms
Jun 02, 2023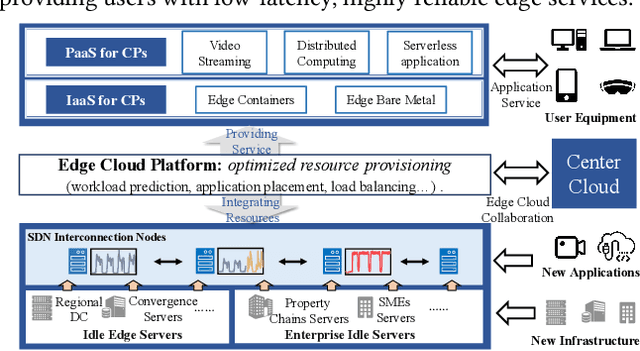
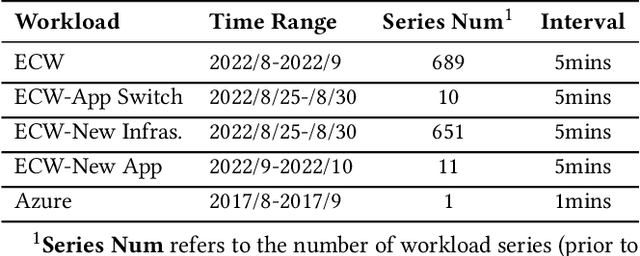
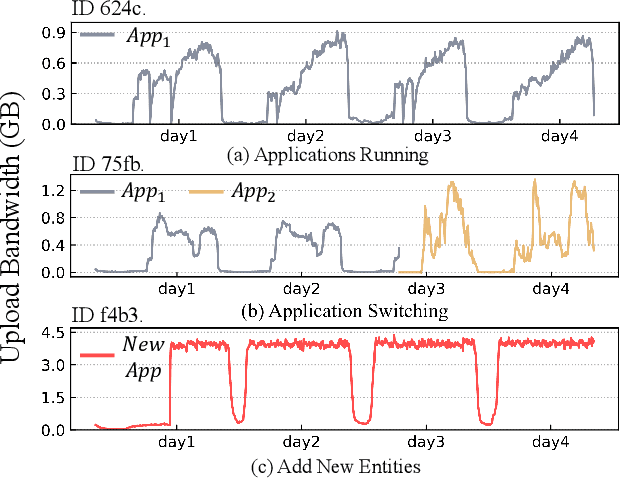
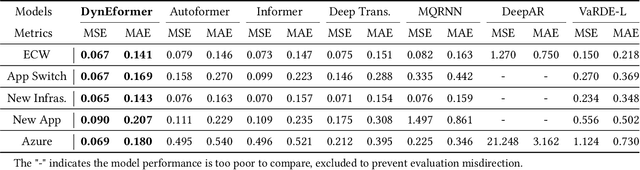
Workload prediction in multi-tenant edge cloud platforms (MT-ECP) is vital for efficient application deployment and resource provisioning. However, the heterogeneous application patterns, variable infrastructure performance, and frequent deployments in MT-ECP pose significant challenges for accurate and efficient workload prediction. Clustering-based methods for dynamic MT-ECP modeling often incur excessive costs due to the need to maintain numerous data clusters and models, which leads to excessive costs. Existing end-to-end time series prediction methods are challenging to provide consistent prediction performance in dynamic MT-ECP. In this paper, we propose an end-to-end framework with global pooling and static content awareness, DynEformer, to provide a unified workload prediction scheme for dynamic MT-ECP. Meticulously designed global pooling and information merging mechanisms can effectively identify and utilize global application patterns to drive local workload predictions. The integration of static content-aware mechanisms enhances model robustness in real-world scenarios. Through experiments on five real-world datasets, DynEformer achieved state-of-the-art in the dynamic scene of MT-ECP and provided a unified end-to-end prediction scheme for MT-ECP.
When Computing Power Network Meets Distributed Machine Learning: An Efficient Federated Split Learning Framework
May 22, 2023



In this paper, we advocate CPN-FedSL, a novel and flexible Federated Split Learning (FedSL) framework over Computing Power Network (CPN). We build a dedicated model to capture the basic settings and learning characteristics (e.g., training flow, latency and convergence). Based on this model, we introduce Resource Usage Effectiveness (RUE), a novel performance metric integrating training utility with system cost, and formulate a multivariate scheduling problem that maxi?mizes RUE by comprehensively taking client admission, model partition, server selection, routing and bandwidth allocation into account (i.e., mixed-integer fractional programming). We design Refinery, an efficient approach that first linearizes the fractional objective and non-convex constraints, and then solves the transformed problem via a greedy based rounding algorithm in multiple iterations. Extensive evaluations corroborate that CPN-FedSL is superior to the standard and state-of-the-art learning frameworks (e.g., FedAvg and SplitFed), and besides Refinery is lightweight and significantly outperforms its variants and de facto heuristic methods under a variety of settings.
Student Classroom Behavior Detection based on YOLOv7-BRA and Multi-Model Fusion
May 13, 2023Accurately detecting student behavior in classroom videos can aid in analyzing their classroom performance and improving teaching effectiveness. However, the current accuracy rate in behavior detection is low. To address this challenge, we propose the Student Classroom Behavior Detection system based on based on YOLOv7-BRA (YOLOv7 with Bi-level Routing Attention ). We identified eight different behavior patterns, including standing, sitting, speaking, listening, walking, raising hands, reading, and writing. We constructed a dataset, which contained 11,248 labels and 4,001 images, with an emphasis on the common behavior of raising hands in a classroom setting (Student Classroom Behavior dataset, SCB-Dataset). To improve detection accuracy, we added the biformer attention module to the YOLOv7 network. Finally, we fused the results from YOLOv7 CrowdHuman, SlowFast, and DeepSort models to obtain student classroom behavior data. We conducted experiments on the SCB-Dataset, and YOLOv7-BRA achieved an mAP@0.5 of 87.1%, resulting in a 2.2% improvement over previous results. Our SCB-dataset can be downloaded from: https://github.com/Whiffe/SCB-datase