 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Sparsely Activated Transformer with Stochastic Experts
Oct 12, 2021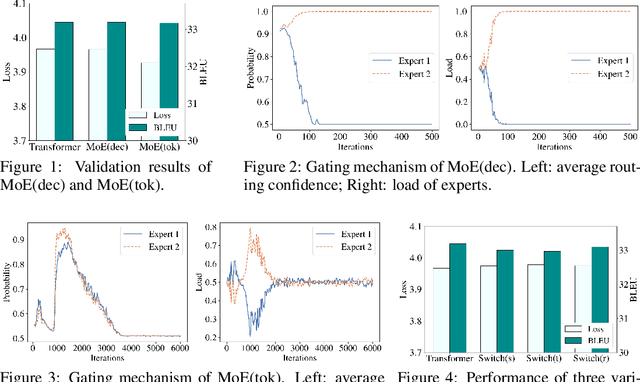
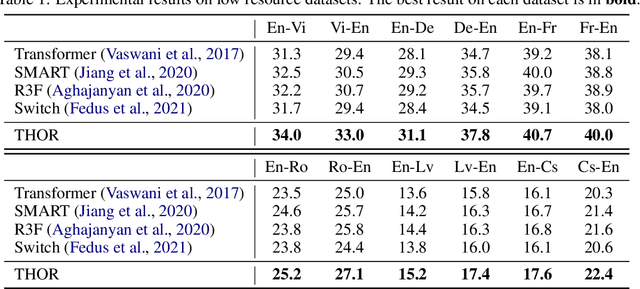
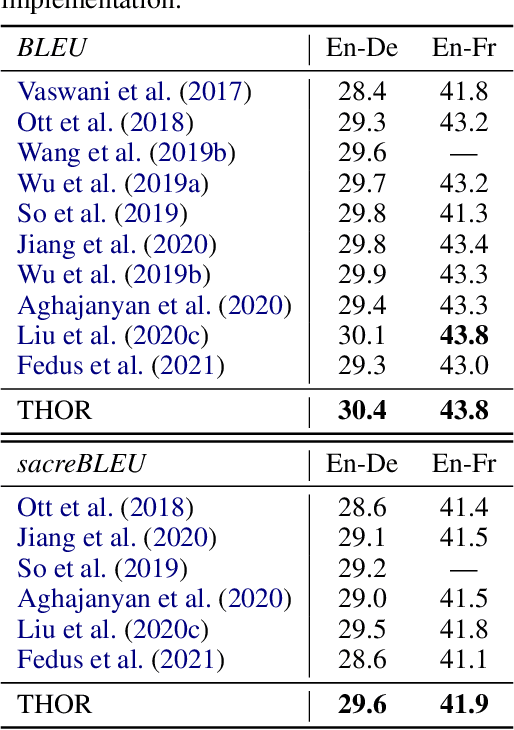

Sparsely activated models (SAMs), such as Mixture-of-Experts (MoE), can easily scale to have outrageously large amounts of parameters without significant increase in computational cost. However, SAMs are reported to be parameter inefficient such that larger models do not always lead to better performance. While most on-going research focuses on improving SAMs models by exploring methods of routing inputs to experts, our analysis reveals that such research might not lead to the solution we expect, i.e., the commonly-used routing methods based on gating mechanisms do not work better than randomly routing inputs to experts. In this paper, we propose a new expert-based model, THOR (Transformer witH StOchastic ExpeRts). Unlike classic expert-based models, such as the Switch Transformer, experts in THOR are randomly activated for each input during training and inference. THOR models are trained using a consistency regularized loss, where experts learn not only from training data but also from other experts as teachers, such that all the experts make consistent predictions. We validate the effectiveness of THOR on machine translation tasks. Results show that THOR models are more parameter efficient in that they significantly outperform the Transformer and MoE models across various settings. For example, in multilingual translation, THOR outperforms the Switch Transformer by 2 BLEU scores, and obtains the same BLEU score as that of a state-of-the-art MoE model that is 18 times larger. Our code is publicly available at: https://github.com/microsoft/Stochastic-Mixture-of-Experts.
ARCH: Efficient Adversarial Regularized Training with Caching
Sep 15, 2021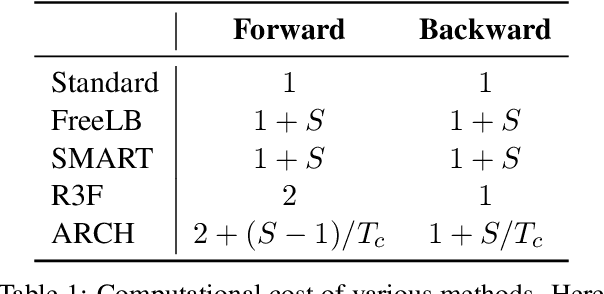
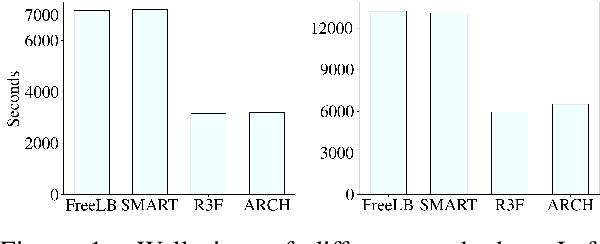
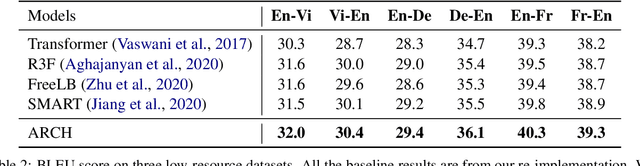
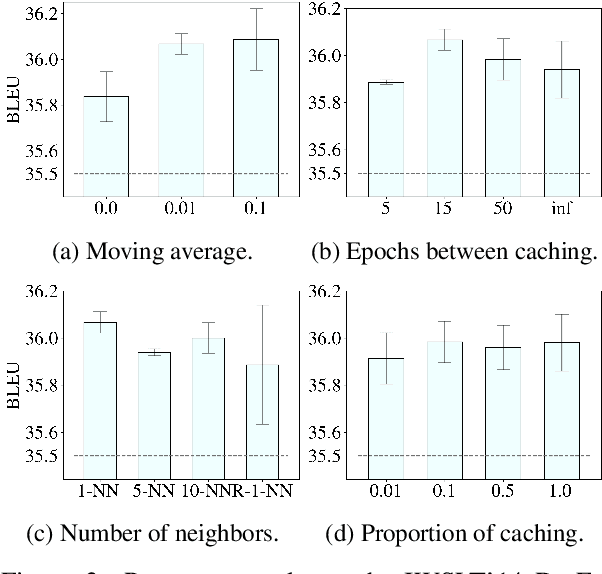
Adversarial regularization can improve model generalization in many natural language processing tasks. However, conventional approaches are computationally expensive since they need to generate a perturbation for each sample in each epoch. We propose a new adversarial regularization method ARCH (adversarial regularization with caching), where perturbations are generated and cached once every several epochs. As caching all the perturbations imposes memory usage concerns, we adopt a K-nearest neighbors-based strategy to tackle this issue. The strategy only requires caching a small amount of perturbations, without introducing additional training time. We evaluate our proposed method on a set of neural machine translation and natural language understanding tasks. We observe that ARCH significantly eases the computational burden (saves up to 70\% of computational time in comparison with conventional approaches). More surprisingly, by reducing the variance of stochastic gradients, ARCH produces a notably better (in most of the tasks) or comparable model generalization. Our code is publicly available.
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization
Jun 08, 2021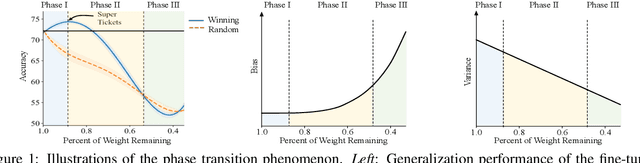

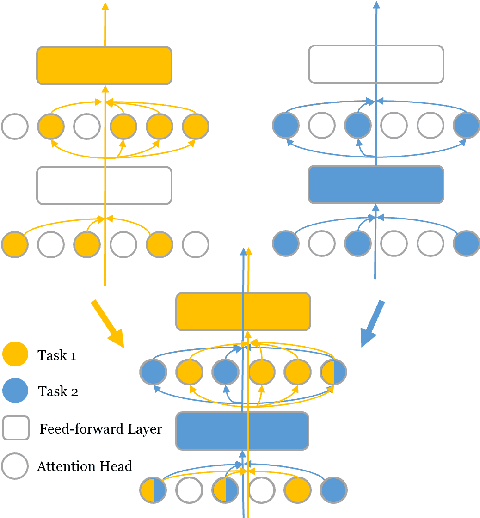

The Lottery Ticket Hypothesis suggests that an over-parametrized network consists of ``lottery tickets'', and training a certain collection of them (i.e., a subnetwork) can match the performance of the full model. In this paper, we study such a collection of tickets, which is referred to as ``winning tickets'', in extremely over-parametrized models, e.g., pre-trained language models. We observe that at certain compression ratios, the generalization performance of the winning tickets can not only match but also exceed that of the full model. In particular, we observe a phase transition phenomenon: As the compression ratio increases, generalization performance of the winning tickets first improves then deteriorates after a certain threshold. We refer to the tickets on the threshold as ``super tickets''. We further show that the phase transition is task and model dependent -- as the model size becomes larger and the training data set becomes smaller, the transition becomes more pronounced. Our experiments on the GLUE benchmark show that the super tickets improve single task fine-tuning by $0.9$ points on BERT-base and $1.0$ points on BERT-large, in terms of task-average score. We also demonstrate that adaptively sharing the super tickets across tasks benefits multi-task learning.
Targeted Adversarial Training for Natural Language Understanding
Apr 12, 2021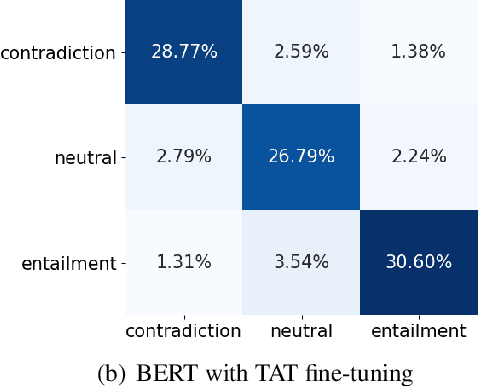
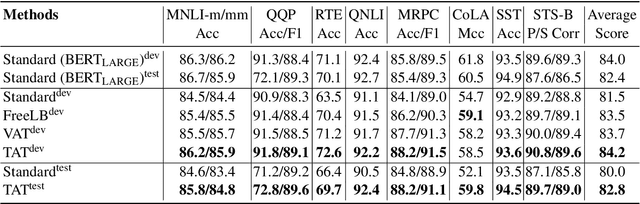
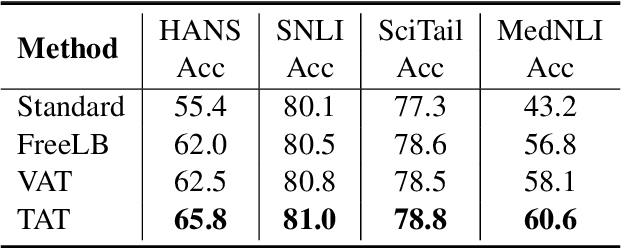
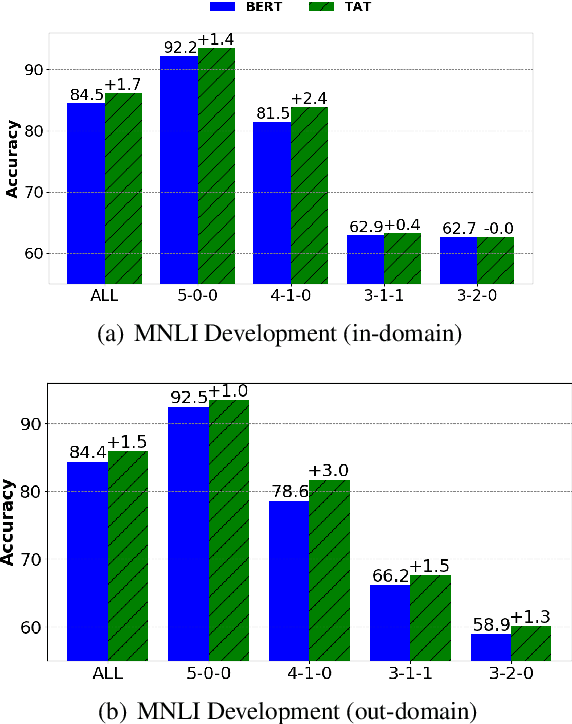
We present a simple yet effective Targeted Adversarial Training (TAT) algorithm to improve adversarial training for natural language understanding. The key idea is to introspect current mistakes and prioritize adversarial training steps to where the model errs the most. Experiments show that TAT can significantly improve accuracy over standard adversarial training on GLUE and attain new state-of-the-art zero-shot results on XNLI. Our code will be released at: https://github.com/namisan/mt-dnn.
Adversarial Training as Stackelberg Game: An Unrolled Optimization Approach
Apr 11, 2021
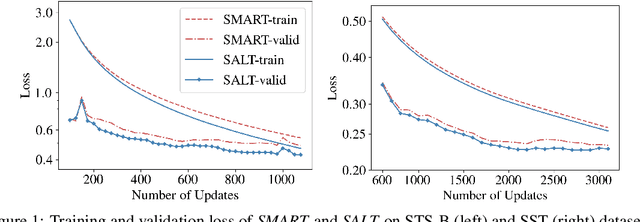
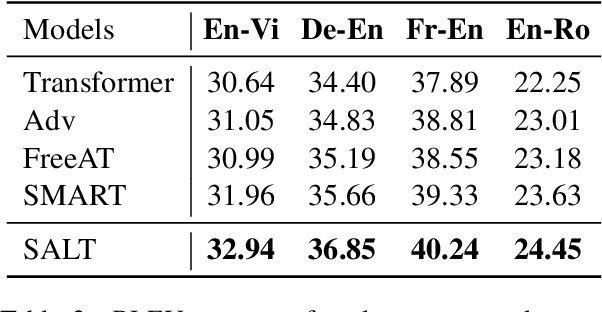
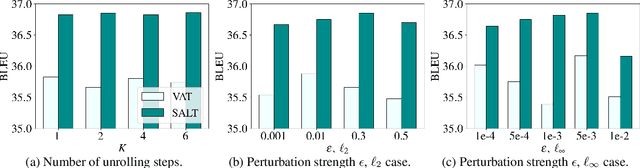
Adversarial training has been shown to improve the generalization performance of deep learning models in various natural language processing tasks. Existing works usually formulate adversarial training as a zero-sum game, which is solved by alternating gradient descent/ascent algorithms. Such a formulation treats the adversarial and the defending players equally, which is undesirable because only the defending player contributes to the generalization performance. To address this issue, we propose Stackelberg Adversarial Training (SALT), which formulates adversarial training as a Stackelberg game. This formulation induces a competition between a leader and a follower, where the follower generates perturbations, and the leader trains the model subject to the perturbations. Different from conventional adversarial training, in SALT, the leader is in an advantageous position. When the leader moves, it recognizes the strategy of the follower and takes the anticipated follower's outcomes into consideration. Such a leader's advantage enables us to improve the model fitting to the unperturbed data. The leader's strategic information is captured by the Stackelberg gradient, which is obtained using an unrolling algorithm. Our experimental results on a set of machine translation and natural language understanding tasks show that SALT outperforms existing adversarial training baselines across all tasks.
Unveiling personnel movement in a larger indoor area with a non-overlapping multi-camera system
Apr 10, 2021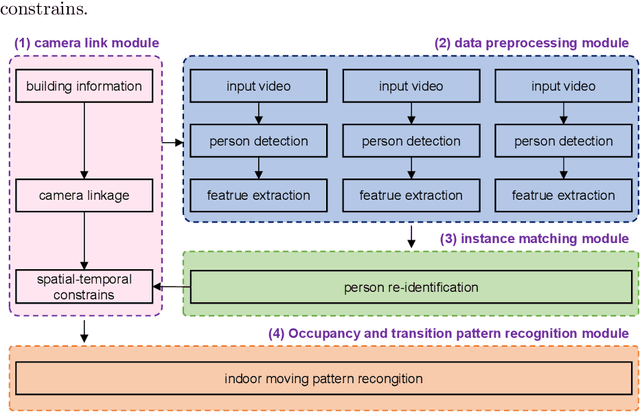
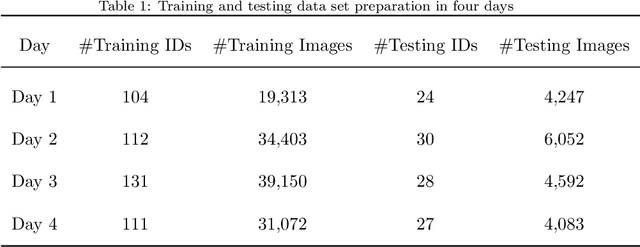
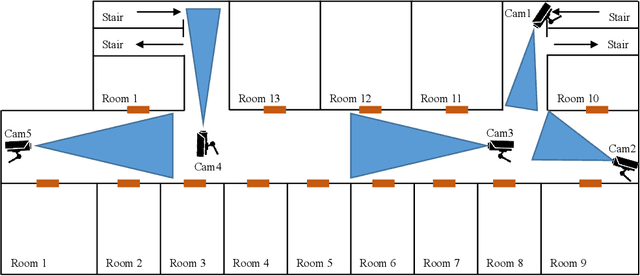

Surveillance cameras are widely applied for indoor occupancy measurement and human movement perception, which benefit for building energy management and social security. To address the challenges of limited view angle of single camera as well as lacking of inter-camera collaboration, this study presents a non-overlapping multi-camera system to enlarge the surveillance area and devotes to retrieve the same person appeared from different camera views. The system is deployed in an office building and four-day videos are collected. By training a deep convolutional neural network, the proposed system first extracts the appearance feature embeddings of each personal image, which detected from different cameras, for similarity comparison. Then, a stochastic inter-camera transition matrix is associated with appearance feature for further improving the person re-identification ranking results. Finally, a noise-suppression explanation is given for analyzing the matching improvements. This paper expands the scope of indoor movement perception based on non-overlapping multiple cameras and improves the accuracy of pedestrian re-identification without introducing additional types of sensors.
Token-wise Curriculum Learning for Neural Machine Translation
Mar 20, 2021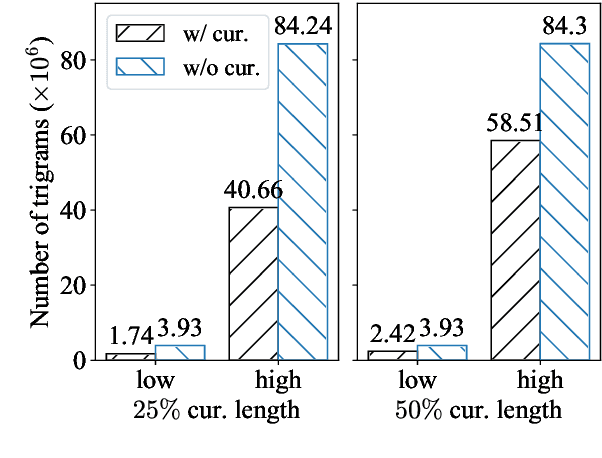
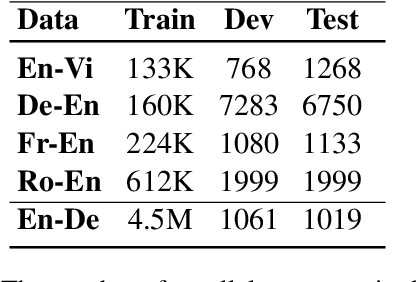
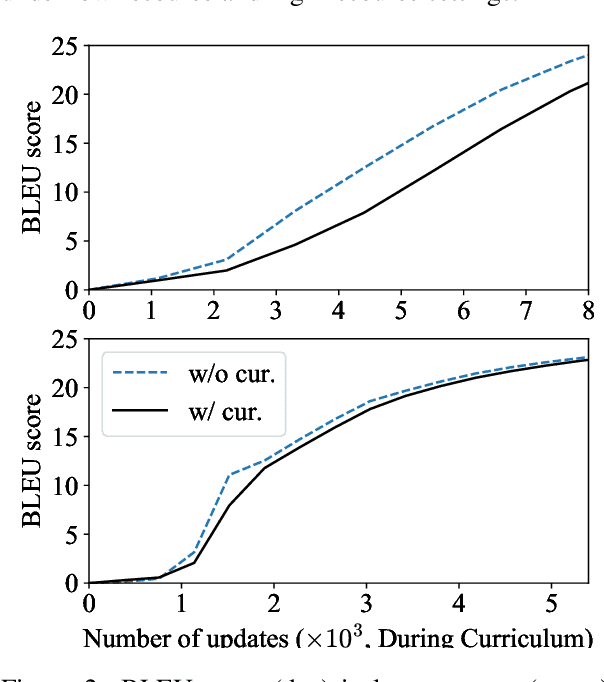
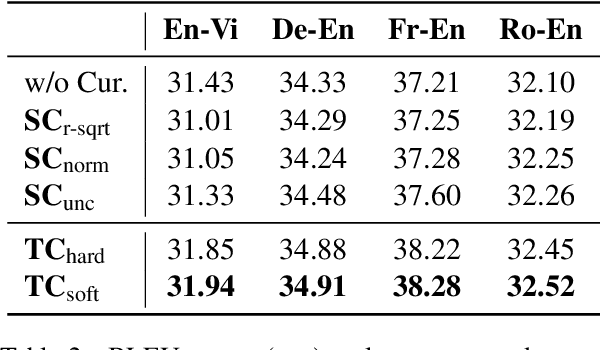
Existing curriculum learning approaches to Neural Machine Translation (NMT) require sampling sufficient amounts of "easy" samples from training data at the early training stage. This is not always achievable for low-resource languages where the amount of training data is limited. To address such limitation, we propose a novel token-wise curriculum learning approach that creates sufficient amounts of easy samples. Specifically, the model learns to predict a short sub-sequence from the beginning part of each target sentence at the early stage of training, and then the sub-sequence is gradually expanded as the training progresses. Such a new curriculum design is inspired by the cumulative effect of translation errors, which makes the latter tokens more difficult to predict than the beginning ones. Extensive experiments show that our approach can consistently outperform baselines on 5 language pairs, especially for low-resource languages. Combining our approach with sentence-level methods further improves the performance on high-resource languages.
Tracking Air Pollution in China: Near Real-Time PM2.5 Retrievals from Multiple Data Sources
Mar 11, 2021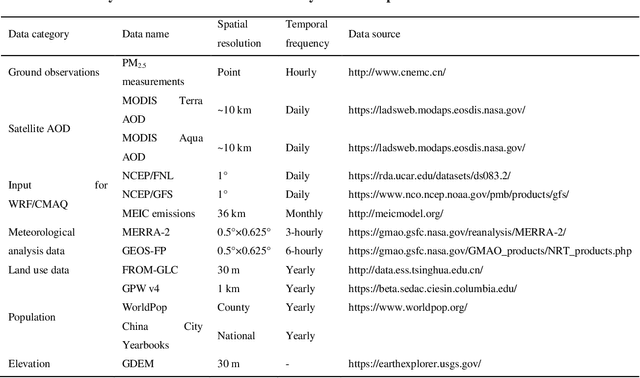
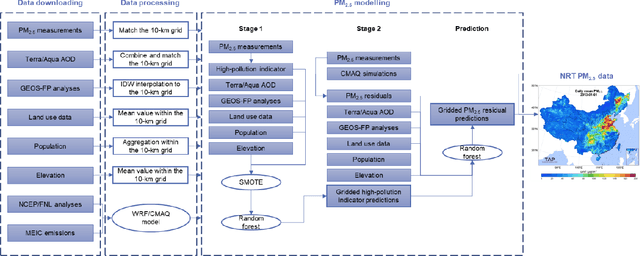
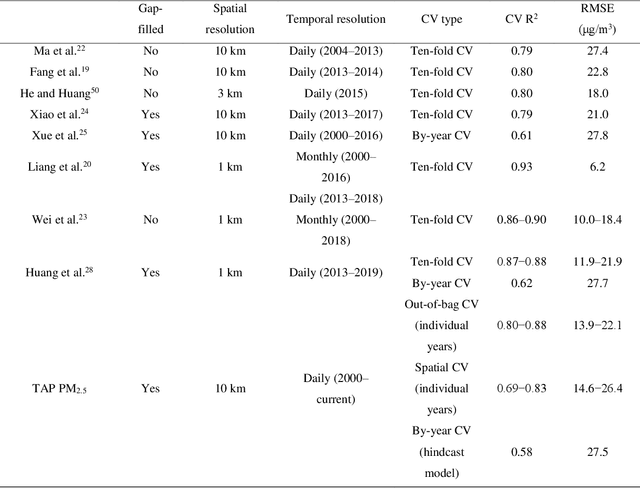
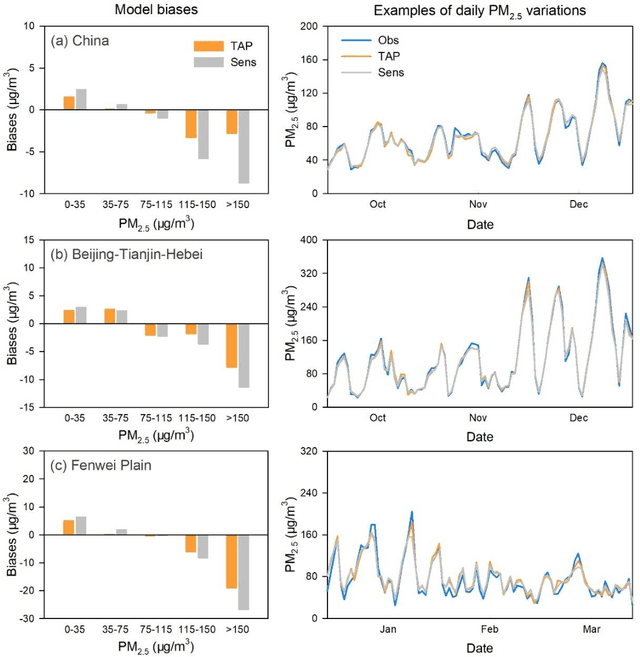
Air pollution has altered the Earth radiation balance, disturbed the ecosystem and increased human morbidity and mortality. Accordingly, a full-coverage high-resolution air pollutant dataset with timely updates and historical long-term records is essential to support both research and environmental management. Here, for the first time, we develop a near real-time air pollutant database known as Tracking Air Pollution in China (TAP, tapdata.org) that combines information from multiple data sources, including ground measurements, satellite retrievals, dynamically updated emission inventories, operational chemical transport model simulations and other ancillary data. Daily full-coverage PM2.5 data at a spatial resolution of 10 km is our first near real-time product. The TAP PM2.5 is estimated based on a two-stage machine learning model coupled with the synthetic minority oversampling technique and a tree-based gap-filling method. Our model has an averaged out-of-bag cross-validation R2 of 0.83 for different years, which is comparable to those of other studies, but improves its performance at high pollution levels and fills the gaps in missing AOD on daily scale. The full coverage and near real-time updates of the daily PM2.5 data allow us to track the day-to-day variations in PM2.5 concentrations over China in a timely manner. The long-term records of PM2.5 data since 2000 will also support policy assessments and health impact studies. The TAP PM2.5 data are publicly available through our website for sharing with the research and policy communities.
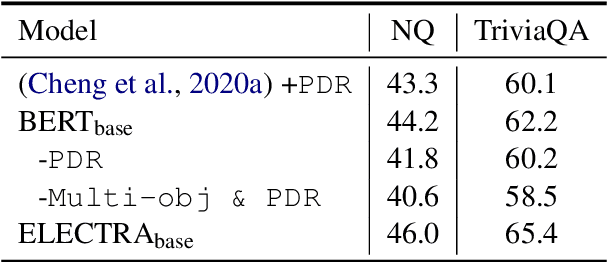
Reader-Guided Passage Reranking for Open-Domain Question Answering
Jan 01, 2021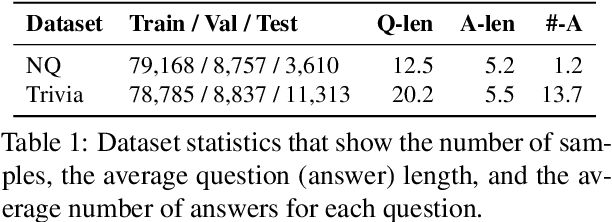
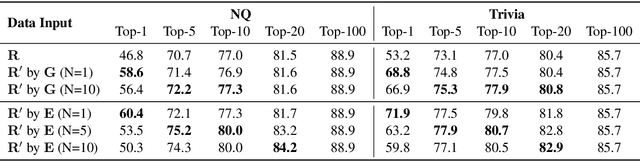
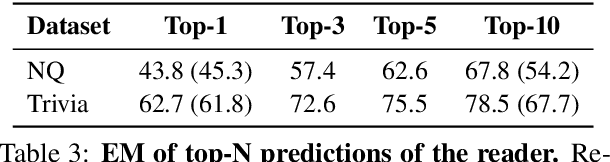
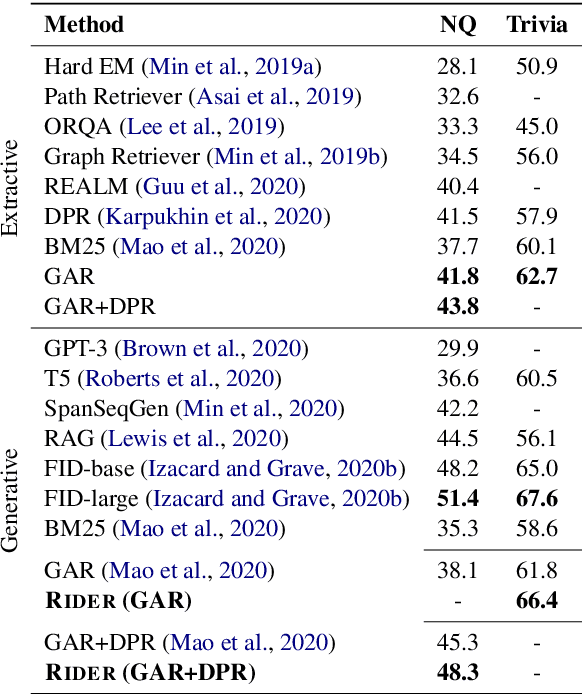
Current open-domain question answering (QA) systems often follow a Retriever-Reader (R2) architecture, where the retriever first retrieves relevant passages and the reader then reads the retrieved passages to form an answer. In this paper, we propose a simple and effective passage reranking method, Reader-guIDEd Reranker (Rider), which does not involve any training and reranks the retrieved passages solely based on the top predictions of the reader before reranking. We show that Rider, despite its simplicity, achieves 10 to 20 absolute gains in top-1 retrieval accuracy and 1 to 4 Exact Match (EM) score gains without refining the retriever or reader. In particular, Rider achieves 48.3 EM on the Natural Questions dataset and 66.4 on the TriviaQA dataset when only 1,024 tokens (7.8 passages on average) are used as the reader input.
UnitedQA: A Hybrid Approach for Open Domain Question Answering
Jan 01, 2021
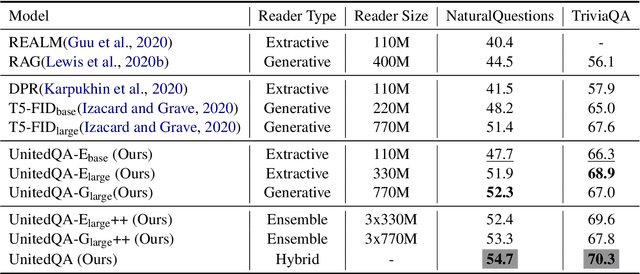
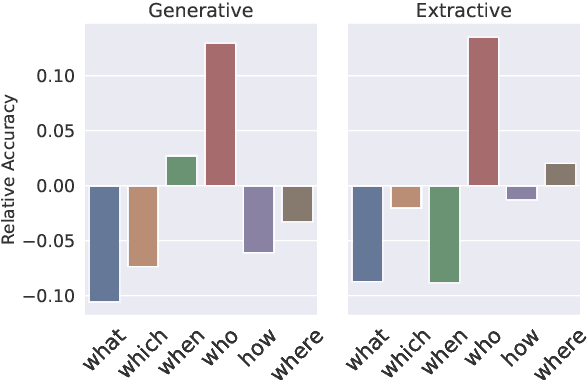
To date, most of recent work under the retrieval-reader framework for open-domain QA focuses on either extractive or generative reader exclusively. In this paper, we study a hybrid approach for leveraging the strengths of both models. We apply novel techniques to enhance both extractive and generative readers built upon recent pretrained neural language models, and find that proper training methods can provide large improvement over previous state-of-the-art models. We demonstrate that a simple hybrid approach by combining answers from both readers can efficiently take advantages of extractive and generative answer inference strategies and outperforms single models as well as homogeneous ensembles. Our approach outperforms previous state-of-the-art models by 3.3 and 2.7 points in exact match on NaturalQuestions and TriviaQA respectively.