 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-directional Attention with Agreement for Dependency Parsing
Sep 22, 2016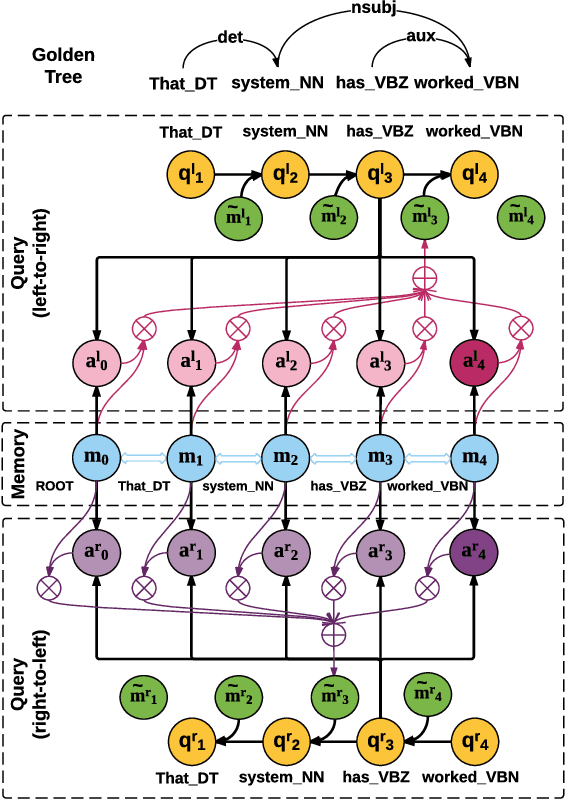
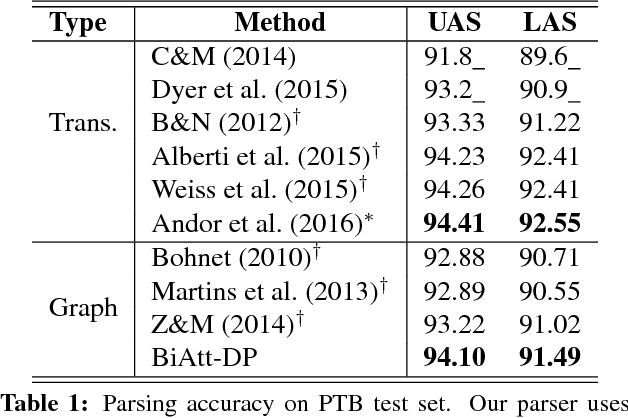
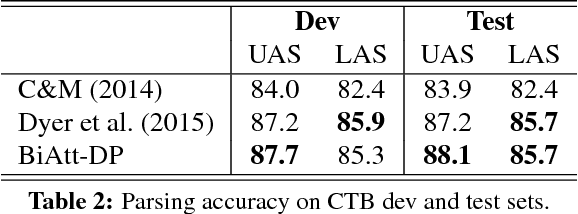
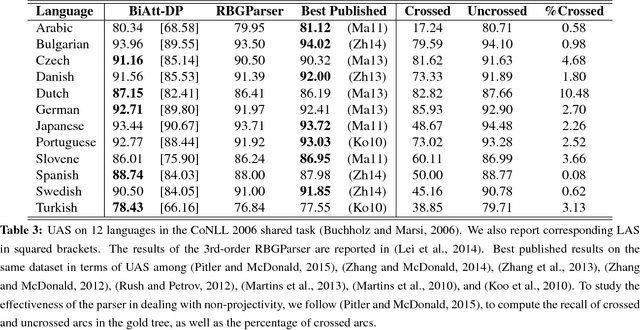
We develop a novel bi-directional attention model for dependency parsing, which learns to agree on headword predictions from the forward and backward parsing directions. The parsing procedure for each direction is formulated as sequentially querying the memory component that stores continuous headword embeddings. The proposed parser makes use of {\it soft} headword embeddings, allowing the model to implicitly capture high-order parsing history without dramatically increasing the computational complexity. We conduct experiments on English, Chinese, and 12 other languages from the CoNLL 2006 shared task, showing that the proposed model achieves state-of-the-art unlabeled attachment scores on 6 languages.
Deep Reinforcement Learning with a Combinatorial Action Space for Predicting Popular Reddit Threads
Sep 17, 2016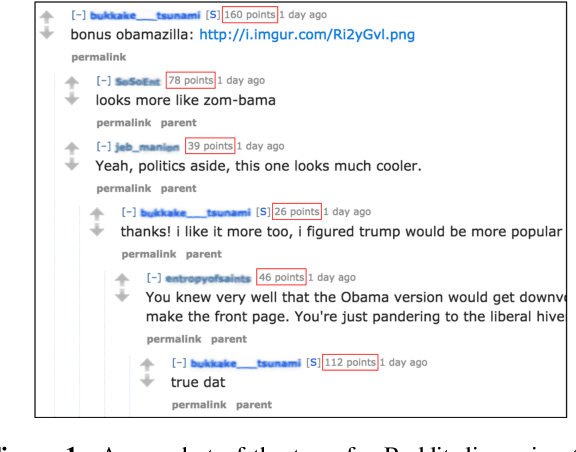
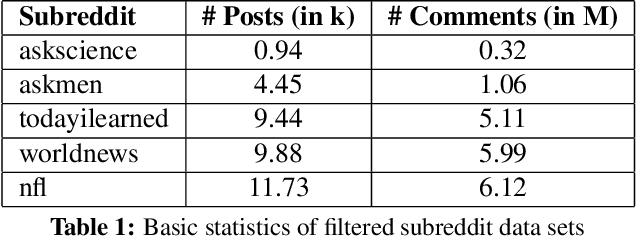
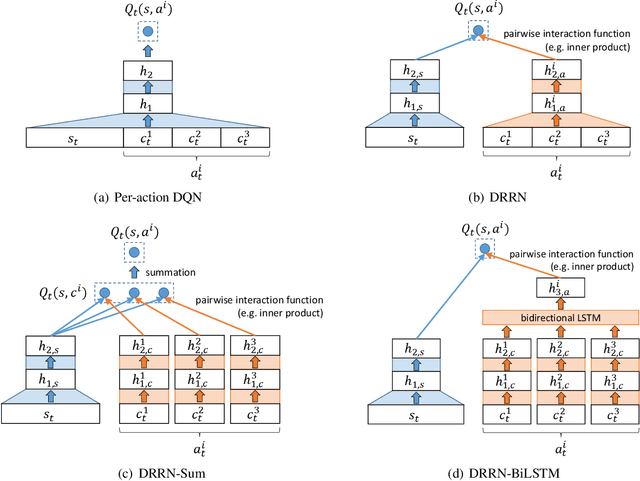
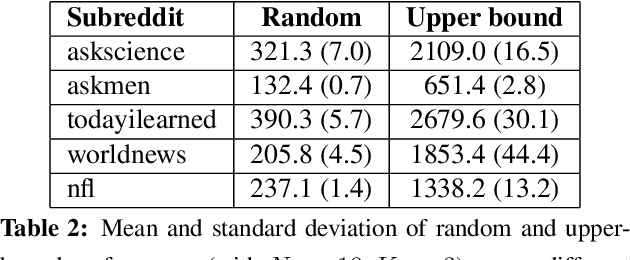
We introduce an online popularity prediction and tracking task as a benchmark task for reinforcement learning with a combinatorial, natural language action space. A specified number of discussion threads predicted to be popular are recommended, chosen from a fixed window of recent comments to track. Novel deep reinforcement learning architectures are studied for effective modeling of the value function associated with actions comprised of interdependent sub-actions. The proposed model, which represents dependence between sub-actions through a bi-directional LSTM, gives the best performance across different experimental configurations and domains, and it also generalizes well with varying numbers of recommendation requests.
MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition
Jul 27, 2016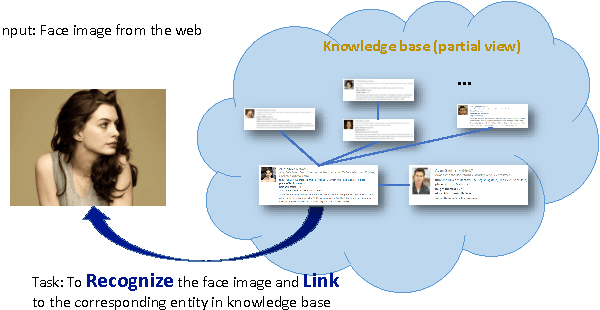
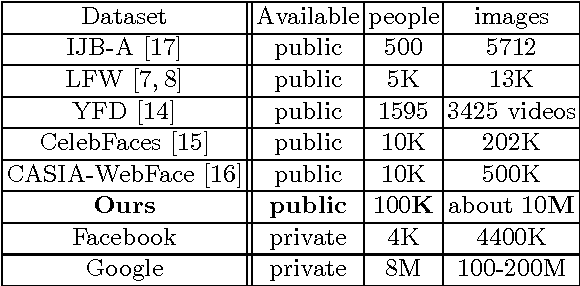
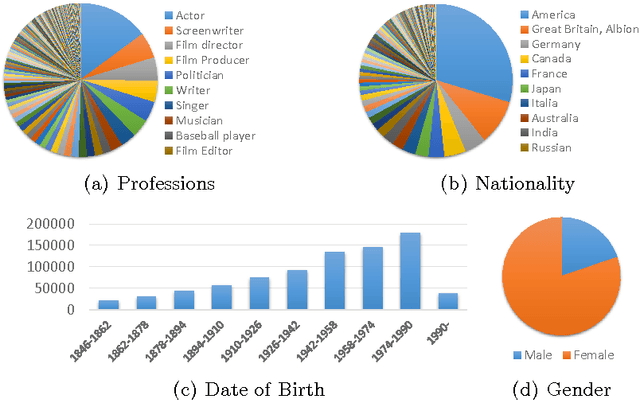
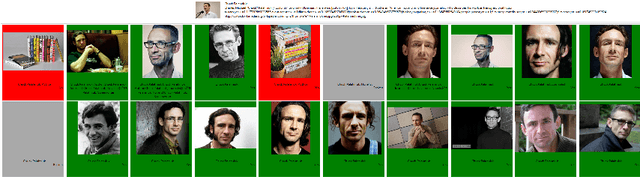
In this paper, we design a benchmark task and provide the associated datasets for recognizing face images and link them to corresponding entity keys in a knowledge base. More specifically, we propose a benchmark task to recognize one million celebrities from their face images, by using all the possibly collected face images of this individual on the web as training data. The rich information provided by the knowledge base helps to conduct disambiguation and improve the recognition accuracy, and contributes to various real-world applications, such as image captioning and news video analysis. Associated with this task, we design and provide concrete measurement set, evaluation protocol, as well as training data. We also present in details our experiment setup and report promising baseline results. Our benchmark task could lead to one of the largest classification problems in computer vision. To the best of our knowledge, our training dataset, which contains 10M images in version 1, is the largest publicly available one in the world.
Unsupervised Learning of Predictors from Unpaired Input-Output Samples
Jun 15, 2016
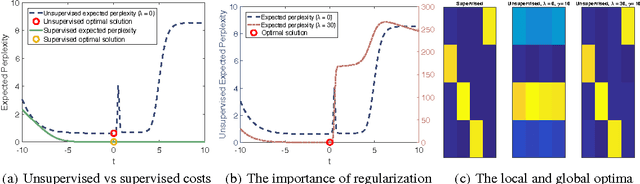
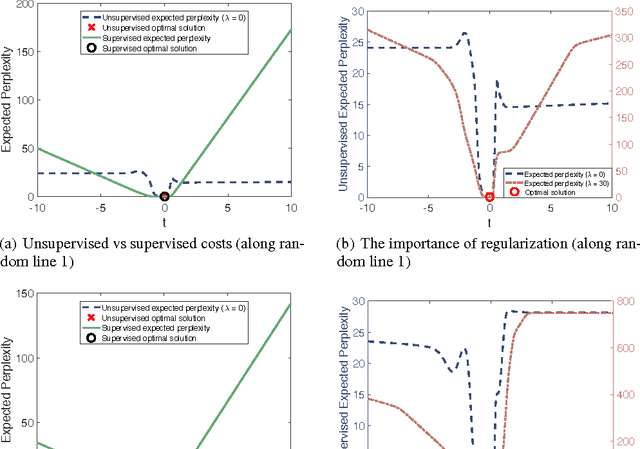
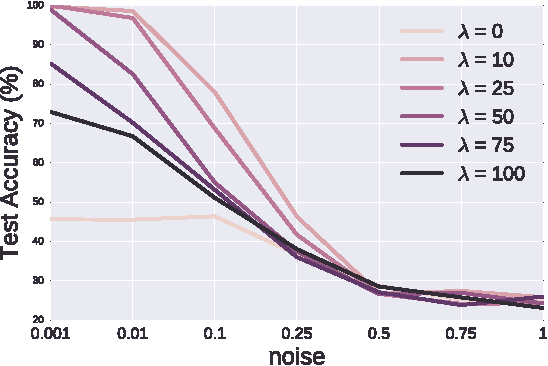
Unsupervised learning is the most challenging problem in machine learning and especially in deep learning. Among many scenarios, we study an unsupervised learning problem of high economic value --- learning to predict without costly pairing of input data and corresponding labels. Part of the difficulty in this problem is a lack of solid evaluation measures. In this paper, we take a practical approach to grounding unsupervised learning by using the same success criterion as for supervised learning in prediction tasks but we do not require the presence of paired input-output training data. In particular, we propose an objective function that aims to make the predicted outputs fit well the structure of the output while preserving the correlation between the input and the predicted output. We experiment with a synthetic structural prediction problem and show that even with simple linear classifiers, the objective function is already highly non-convex. We further demonstrate the nature of this non-convex optimization problem as well as potential solutions. In particular, we show that with regularization via a generative model, learning with the proposed unsupervised objective function converges to an optimal solution.
Generating Natural Questions About an Image
Jun 09, 2016



There has been an explosion of work in the vision & language community during the past few years from image captioning to video transcription, and answering questions about images. These tasks have focused on literal descriptions of the image. To move beyond the literal, we choose to explore how questions about an image are often directed at commonsense inference and the abstract events evoked by objects in the image. In this paper, we introduce the novel task of Visual Question Generation (VQG), where the system is tasked with asking a natural and engaging question when shown an image. We provide three datasets which cover a variety of images from object-centric to event-centric, with considerably more abstract training data than provided to state-of-the-art captioning systems thus far. We train and test several generative and retrieval models to tackle the task of VQG. Evaluation results show that while such models ask reasonable questions for a variety of images, there is still a wide gap with human performance which motivates further work on connecting images with commonsense knowledge and pragmatics. Our proposed task offers a new challenge to the community which we hope furthers interest in exploring deeper connections between vision & language.
Deep Reinforcement Learning with a Natural Language Action Space
Jun 08, 2016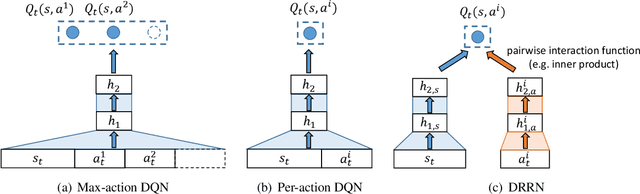
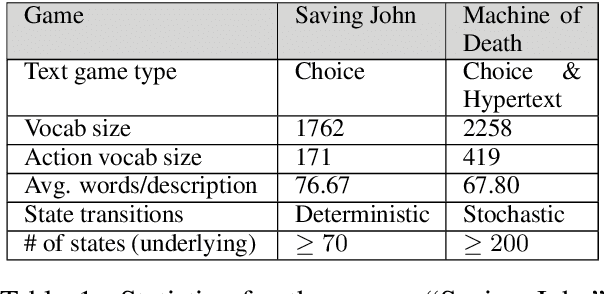
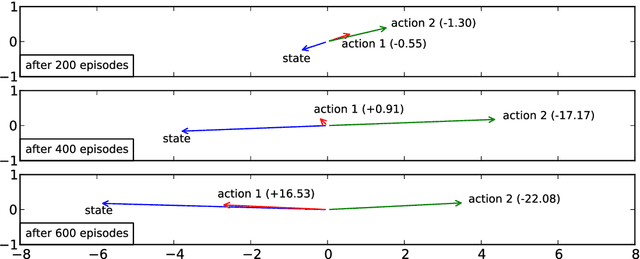
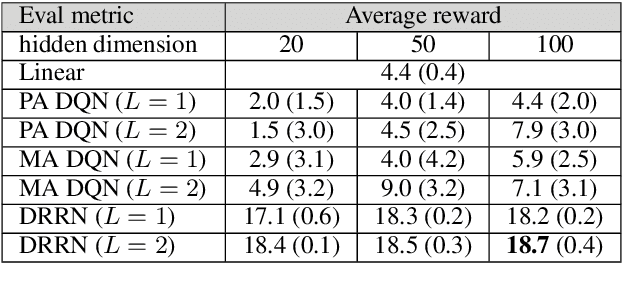
This paper introduces a novel architecture for reinforcement learning with deep neural networks designed to handle state and action spaces characterized by natural language, as found in text-based games. Termed a deep reinforcement relevance network (DRRN), the architecture represents action and state spaces with separate embedding vectors, which are combined with an interaction function to approximate the Q-function in reinforcement learning. We evaluate the DRRN on two popular text games, showing superior performance over other deep Q-learning architectures. Experiments with paraphrased action descriptions show that the model is extracting meaning rather than simply memorizing strings of text.
Character-Level Question Answering with Attention
Jun 05, 2016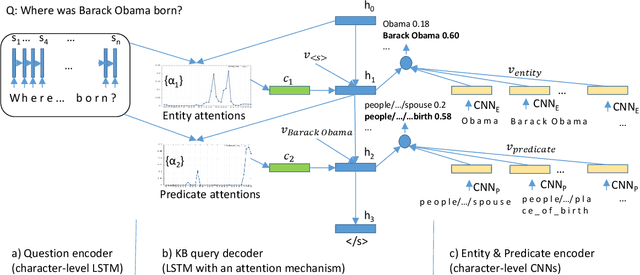
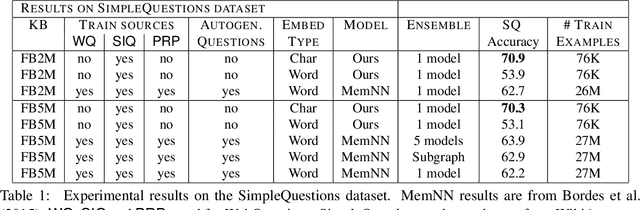

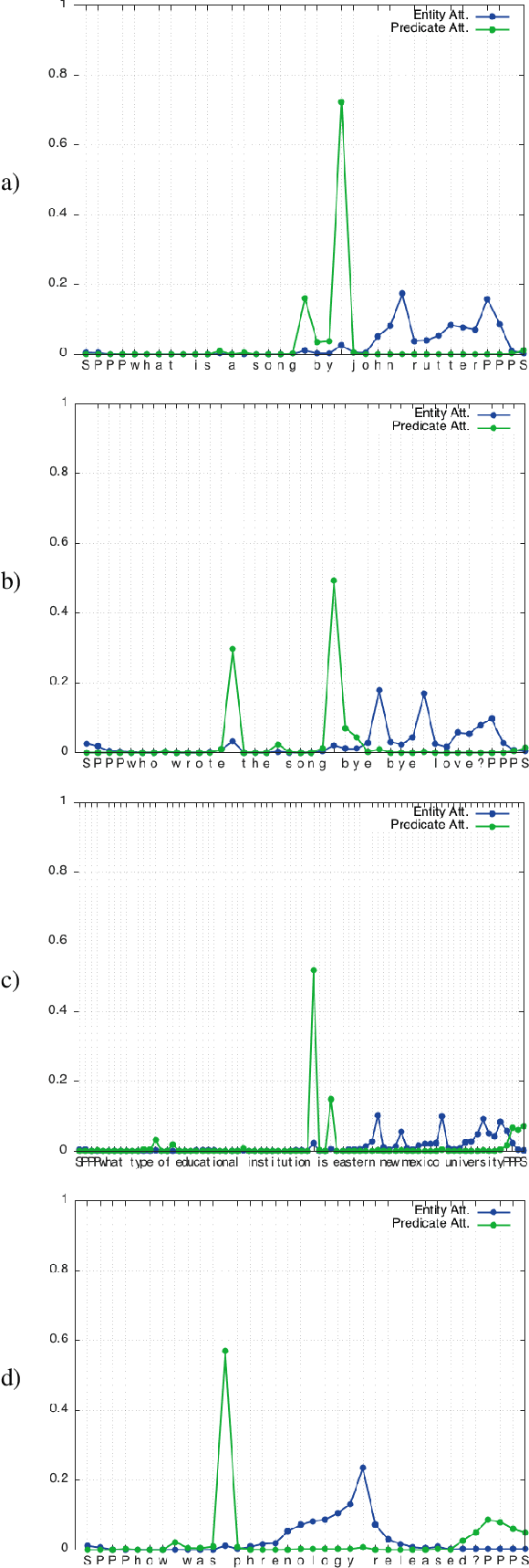
We show that a character-level encoder-decoder framework can be successfully applied to question answering with a structured knowledge base. We use our model for single-relation question answering and demonstrate the effectiveness of our approach on the SimpleQuestions dataset (Bordes et al., 2015), where we improve state-of-the-art accuracy from 63.9% to 70.9%, without use of ensembles. Importantly, our character-level model has 16x fewer parameters than an equivalent word-level model, can be learned with significantly less data compared to previous work, which relies on data augmentation, and is robust to new entities in testing.
Visual Storytelling
Apr 13, 2016

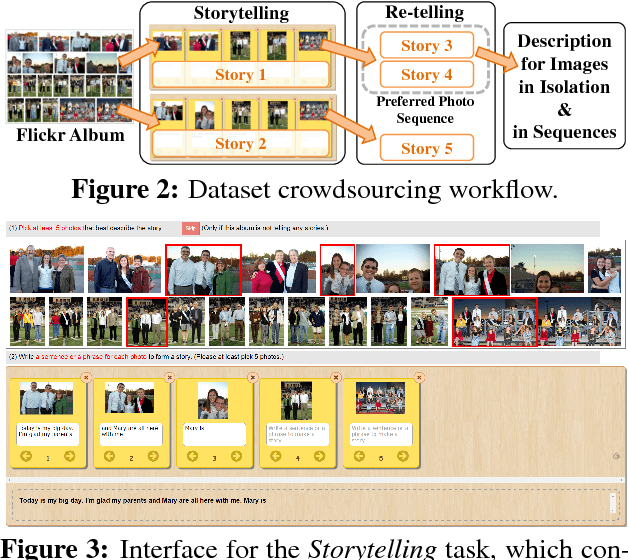
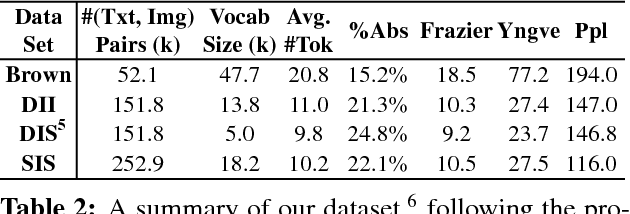
We introduce the first dataset for sequential vision-to-language, and explore how this data may be used for the task of visual storytelling. The first release of this dataset, SIND v.1, includes 81,743 unique photos in 20,211 sequences, aligned to both descriptive (caption) and story language. We establish several strong baselines for the storytelling task, and motivate an automatic metric to benchmark progress. Modelling concrete description as well as figurative and social language, as provided in this dataset and the storytelling task, has the potential to move artificial intelligence from basic understandings of typical visual scenes towards more and more human-like understanding of grounded event structure and subjective expression.
A Corpus and Evaluation Framework for Deeper Understanding of Commonsense Stories
Apr 06, 2016
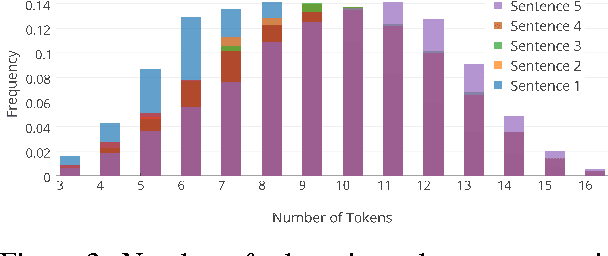

Representation and learning of commonsense knowledge is one of the foundational problems in the quest to enable deep language understanding. This issue is particularly challenging for understanding casual and correlational relationships between events. While this topic has received a lot of interest in the NLP community, research has been hindered by the lack of a proper evaluation framework. This paper attempts to address this problem with a new framework for evaluating story understanding and script learning: the 'Story Cloze Test'. This test requires a system to choose the correct ending to a four-sentence story. We created a new corpus of ~50k five-sentence commonsense stories, ROCStories, to enable this evaluation. This corpus is unique in two ways: (1) it captures a rich set of causal and temporal commonsense relations between daily events, and (2) it is a high quality collection of everyday life stories that can also be used for story generation. Experimental evaluation shows that a host of baselines and state-of-the-art models based on shallow language understanding struggle to achieve a high score on the Story Cloze Test. We discuss these implications for script and story learning, and offer suggestions for deeper language understanding.
Rich Image Captioning in the Wild
Mar 31, 2016
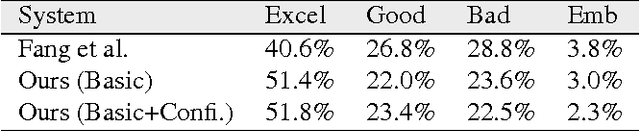
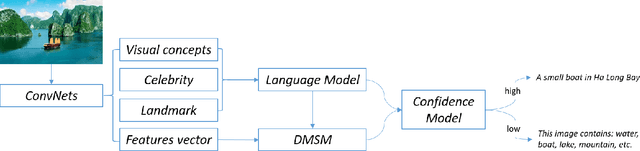
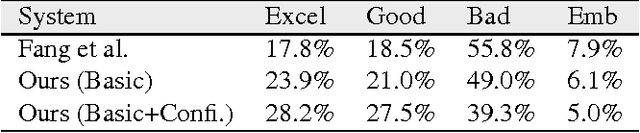
We present an image caption system that addresses new challenges of automatically describing images in the wild. The challenges include high quality caption quality with respect to human judgments, out-of-domain data handling, and low latency required in many applications. Built on top of a state-of-the-art framework, we developed a deep vision model that detects a broad range of visual concepts, an entity recognition model that identifies celebrities and landmarks, and a confidence model for the caption output. Experimental results show that our caption engine outperforms previous state-of-the-art systems significantly on both in-domain dataset (i.e. MS COCO) and out of-domain datasets.