 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Pretrained Image Classifiers for Language-Based Segmentation
Nov 03, 2019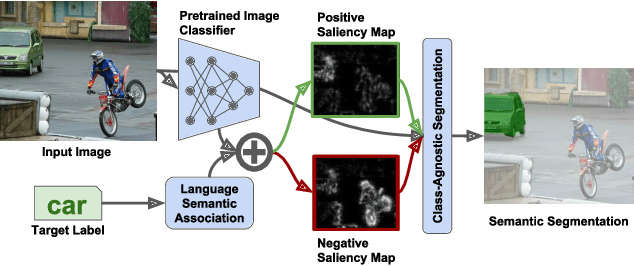
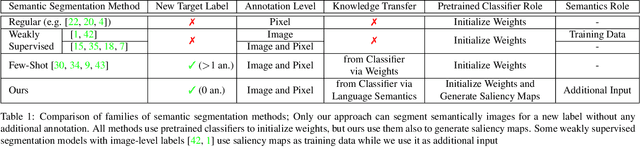
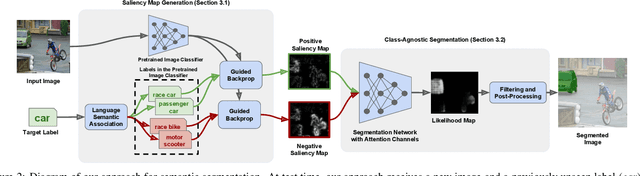
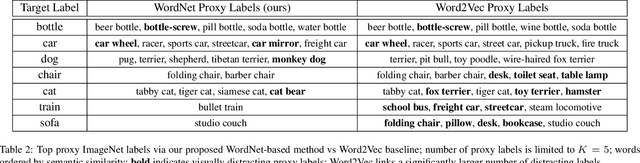
Current semantic segmentation models cannot easily generalize to new object classes unseen during train time: they require additional annotated images and retraining. We propose a novel segmentation model that injects visual priors into semantic segmentation architectures, allowing them to segment out new target labels without retraining. As visual priors, we use the activations of pretrained image classifiers, which provide noisy indications of the spatial location of both the target object and distractor objects in the scene. We leverage language semantics to obtain these activations for a target label unseen by the classifier. Further experiments show that the visual priors obtained via language semantics for both relevant and distracting objects are key to our performance.
Learning to Write with Cooperative Discriminators
May 16, 2018
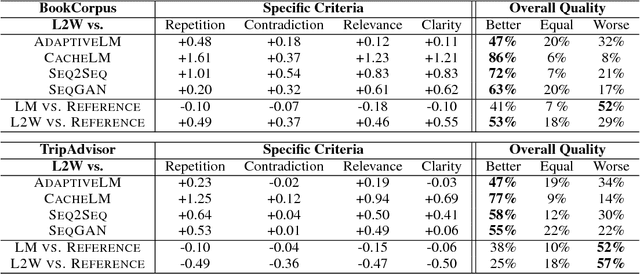


Recurrent Neural Networks (RNNs) are powerful autoregressive sequence models, but when used to generate natural language their output tends to be overly generic, repetitive, and self-contradictory. We postulate that the objective function optimized by RNN language models, which amounts to the overall perplexity of a text, is not expressive enough to capture the notion of communicative goals described by linguistic principles such as Grice's Maxims. We propose learning a mixture of multiple discriminative models that can be used to complement the RNN generator and guide the decoding process. Human evaluation demonstrates that text generated by our system is preferred over that of baselines by a large margin and significantly enhances the overall coherence, style, and information content of the generated text.
Two-Stage Synthesis Networks for Transfer Learning in Machine Comprehension
Sep 23, 2017


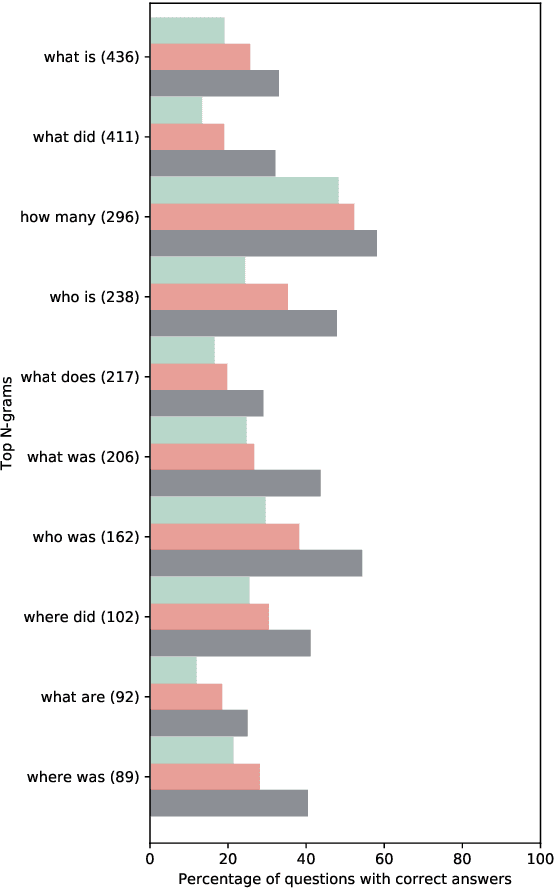
We develop a technique for transfer learning in machine comprehension (MC) using a novel two-stage synthesis network (SynNet). Given a high-performing MC model in one domain, our technique aims to answer questions about documents in another domain, where we use no labeled data of question-answer pairs. Using the proposed SynNet with a pretrained model from the SQuAD dataset on the challenging NewsQA dataset, we achieve an F1 measure of 44.3% with a single model and 46.6% with an ensemble, approaching performance of in-domain models (F1 measure of 50.0%) and outperforming the out-of-domain baseline of 7.6%, without use of provided annotations.
Character-Level Question Answering with Attention
Jun 05, 2016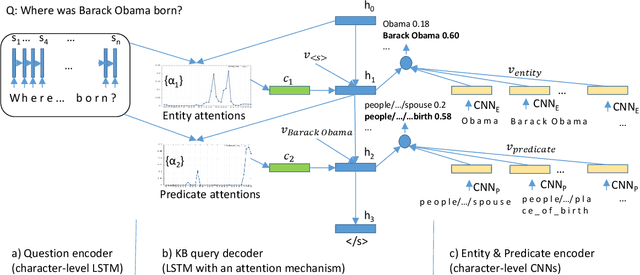
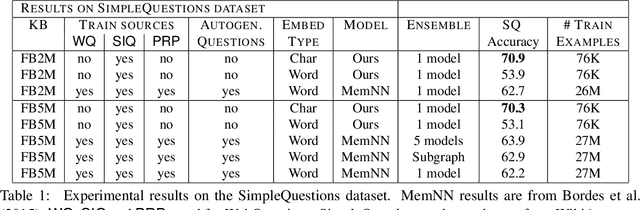

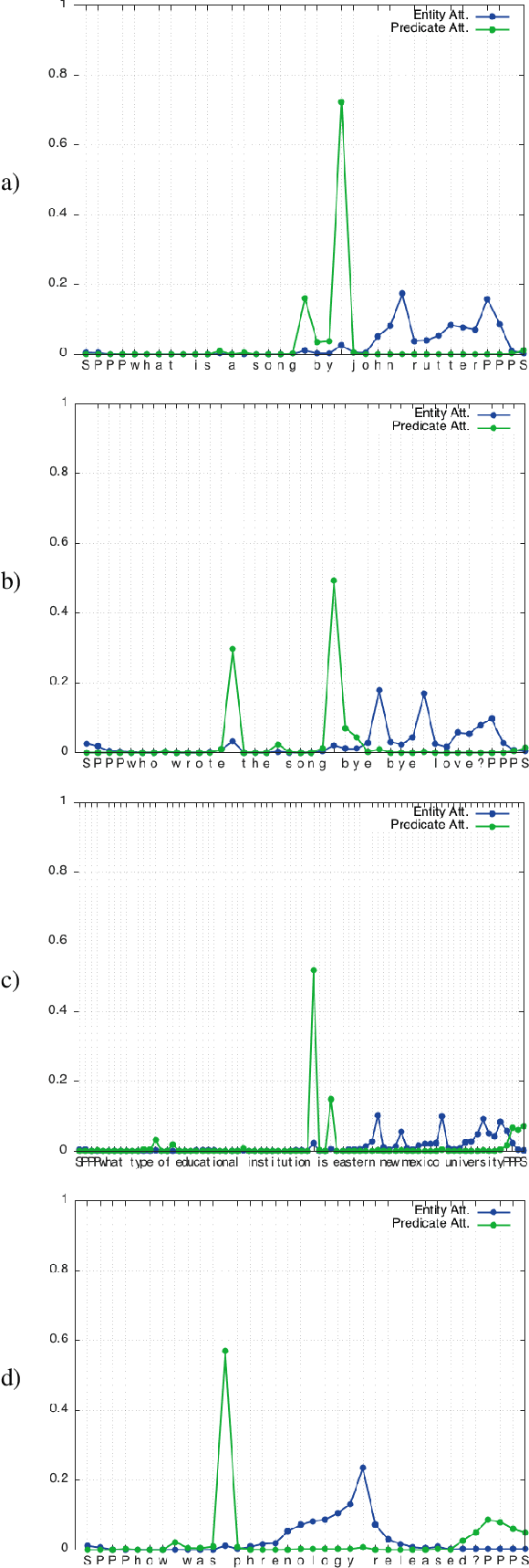
We show that a character-level encoder-decoder framework can be successfully applied to question answering with a structured knowledge base. We use our model for single-relation question answering and demonstrate the effectiveness of our approach on the SimpleQuestions dataset (Bordes et al., 2015), where we improve state-of-the-art accuracy from 63.9% to 70.9%, without use of ensembles. Importantly, our character-level model has 16x fewer parameters than an equivalent word-level model, can be learned with significantly less data compared to previous work, which relies on data augmentation, and is robust to new entities in testing.