 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language to Structured Query Generation via Meta-Learning
Jul 18, 2018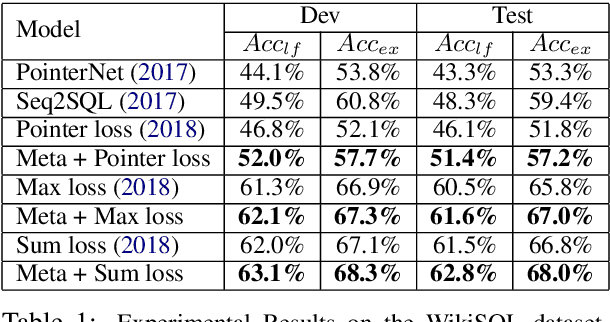
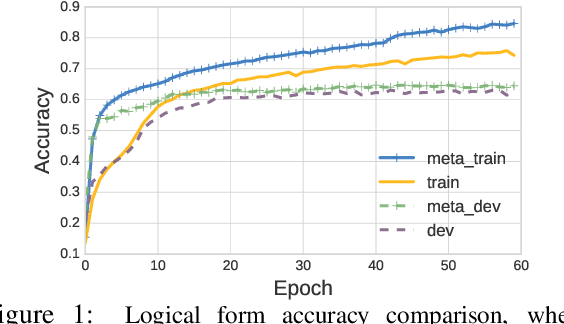
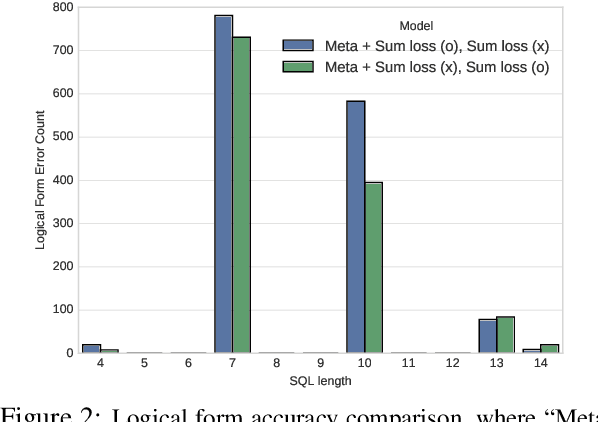
In conventional supervised training, a model is trained to fit all the training examples. However, having a monolithic model may not always be the best strategy, as examples could vary widely. In this work, we explore a different learning protocol that treats each example as a unique pseudo-task, by reducing the original learning problem to a few-shot meta-learning scenario with the help of a domain-dependent relevance function. When evaluated on the WikiSQL dataset, our approach leads to faster convergence and achieves 1.1%-5.4% absolute accuracy gains over the non-meta-learning counterparts.
Discourse-Aware Neural Rewards for Coherent Text Generation
May 10, 2018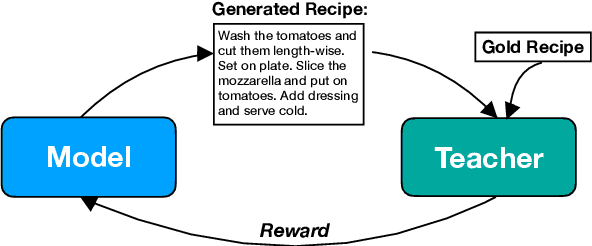
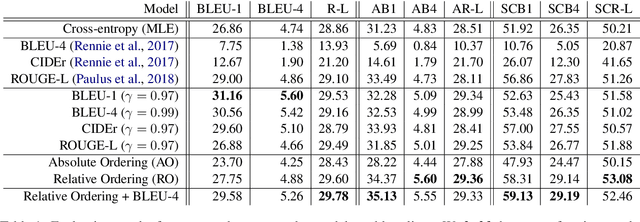
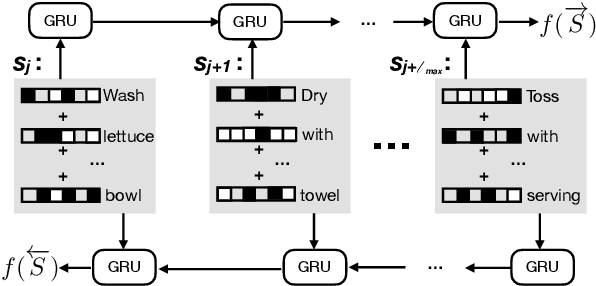
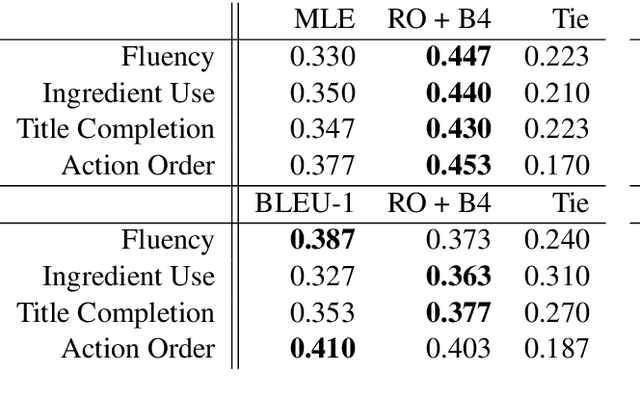
In this paper, we investigate the use of discourse-aware rewards with reinforcement learning to guide a model to generate long, coherent text. In particular, we propose to learn neural rewards to model cross-sentence ordering as a means to approximate desired discourse structure. Empirical results demonstrate that a generator trained with the learned reward produces more coherent and less repetitive text than models trained with cross-entropy or with reinforcement learning with commonly used scores as rewards.
Adversarial Ranking for Language Generation
Apr 16, 2018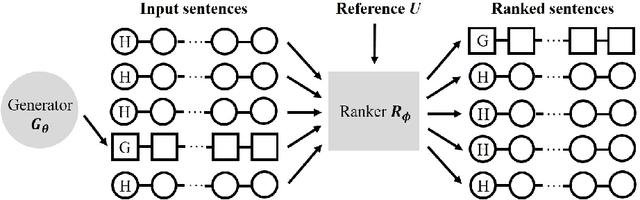
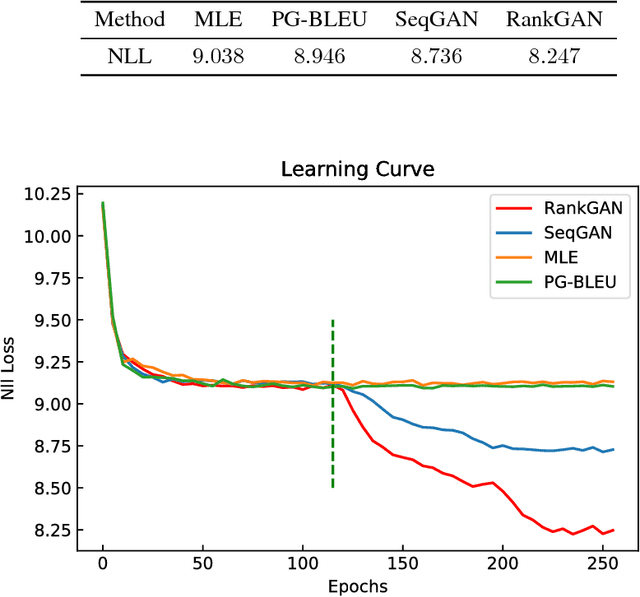


Generative adversarial networks (GANs) have great successes on synthesizing data. However, the existing GANs restrict the discriminator to be a binary classifier, and thus limit their learning capacity for tasks that need to synthesize output with rich structures such as natural language descriptions. In this paper, we propose a novel generative adversarial network, RankGAN, for generating high-quality language descriptions. Rather than training the discriminator to learn and assign absolute binary predicate for individual data sample, the proposed RankGAN is able to analyze and rank a collection of human-written and machine-written sentences by giving a reference group. By viewing a set of data samples collectively and evaluating their quality through relative ranking scores, the discriminator is able to make better assessment which in turn helps to learn a better generator. The proposed RankGAN is optimized through the policy gradient technique. Experimental results on multiple public datasets clearly demonstrate the effectiveness of the proposed approach.
Generating Diverse and Accurate Visual Captions by Comparative Adversarial Learning
Apr 11, 2018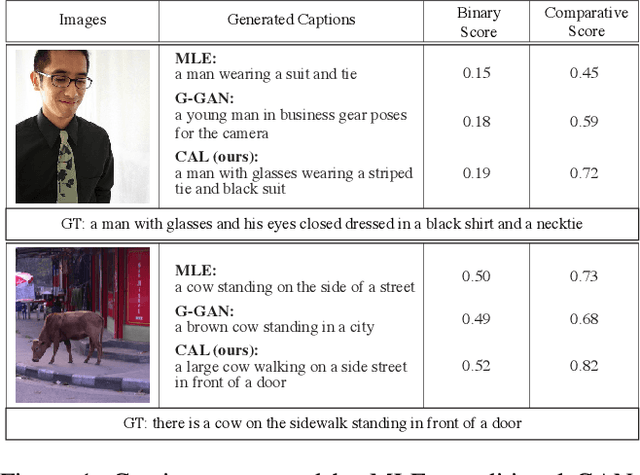
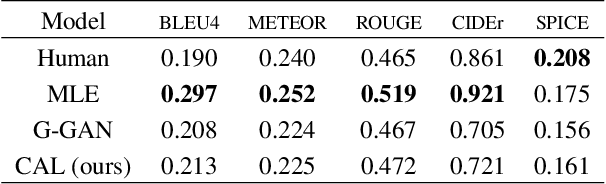
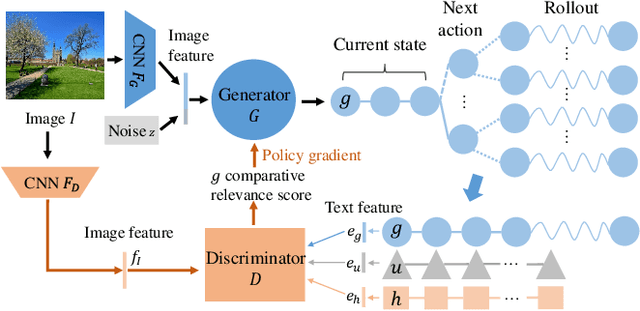
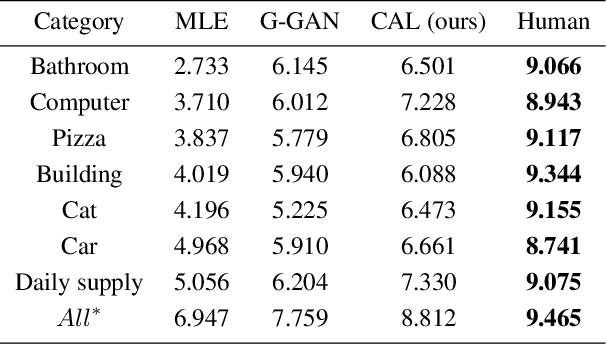
We study how to generate captions that are not only accurate in describing an image but also discriminative across different images. The problem is both fundamental and interesting, as most machine-generated captions, despite phenomenal research progresses in the past several years, are expressed in a very monotonic and featureless format. While such captions are normally accurate, they often lack important characteristics in human languages - distinctiveness for each caption and diversity for different images. To address this problem, we propose a novel conditional generative adversarial network for generating diverse captions across images. Instead of estimating the quality of a caption solely on one image, the proposed comparative adversarial learning framework better assesses the quality of captions by comparing a set of captions within the image-caption joint space. By contrasting with human-written captions and image-mismatched captions, the caption generator effectively exploits the inherent characteristics of human languages, and generates more discriminative captions. We show that our proposed network is capable of producing accurate and diverse captions across images.
CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise
Mar 25, 2018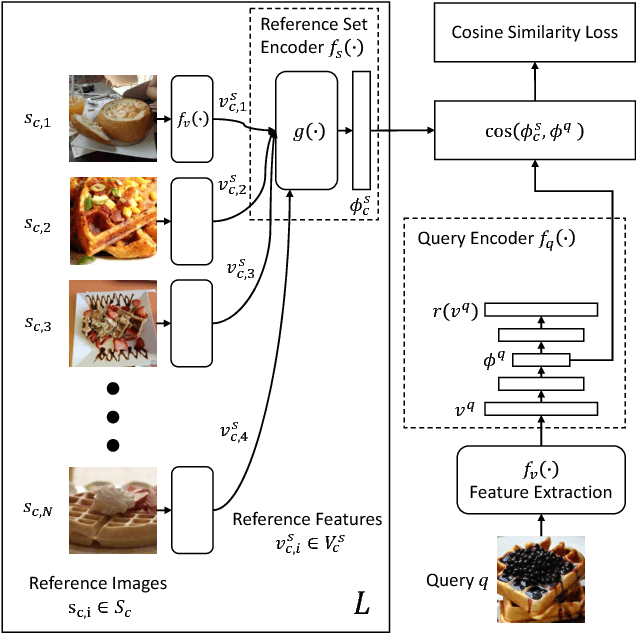
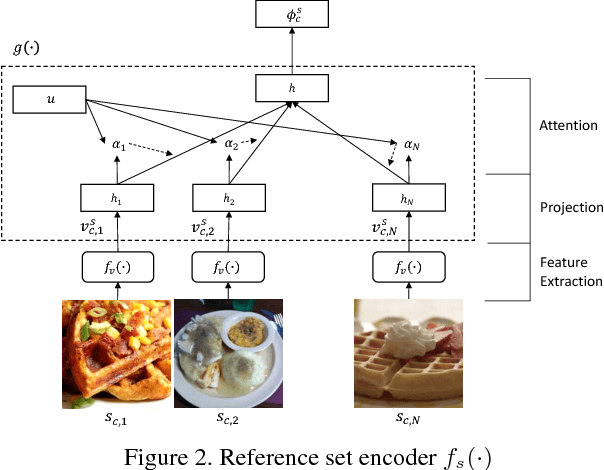
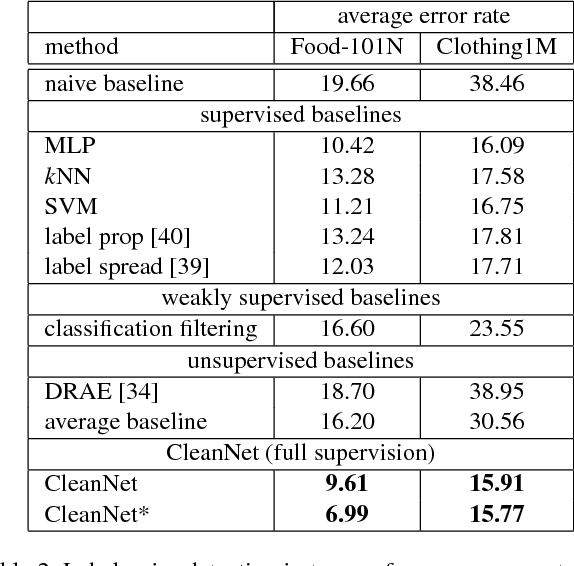
In this paper, we study the problem of learning image classification models with label noise. Existing approaches depending on human supervision are generally not scalable as manually identifying correct or incorrect labels is time-consuming, whereas approaches not relying on human supervision are scalable but less effective. To reduce the amount of human supervision for label noise cleaning, we introduce CleanNet, a joint neural embedding network, which only requires a fraction of the classes being manually verified to provide the knowledge of label noise that can be transferred to other classes. We further integrate CleanNet and conventional convolutional neural network classifier into one framework for image classification learning. We demonstrate the effectiveness of the proposed algorithm on both of the label noise detection task and the image classification on noisy data task on several large-scale datasets. Experimental results show that CleanNet can reduce label noise detection error rate on held-out classes where no human supervision available by 41.5% compared to current weakly supervised methods. It also achieves 47% of the performance gain of verifying all images with only 3.2% images verified on an image classification task. Source code and dataset will be available at kuanghuei.github.io/CleanNetProject.
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
Mar 14, 2018



Top-down visual attention mechanisms have been used extensively in image captioning and visual question answering (VQA) to enable deeper image understanding through fine-grained analysis and even multiple steps of reasoning. In this work, we propose a combined bottom-up and top-down attention mechanism that enables attention to be calculated at the level of objects and other salient image regions. This is the natural basis for attention to be considered. Within our approach, the bottom-up mechanism (based on Faster R-CNN) proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings. Applying this approach to image captioning, our results on the MSCOCO test server establish a new state-of-the-art for the task, achieving CIDEr / SPICE / BLEU-4 scores of 117.9, 21.5 and 36.9, respectively. Demonstrating the broad applicability of the method, applying the same approach to VQA we obtain first place in the 2017 VQA Challenge.
On the Discrimination-Generalization Tradeoff in GANs
Feb 23, 2018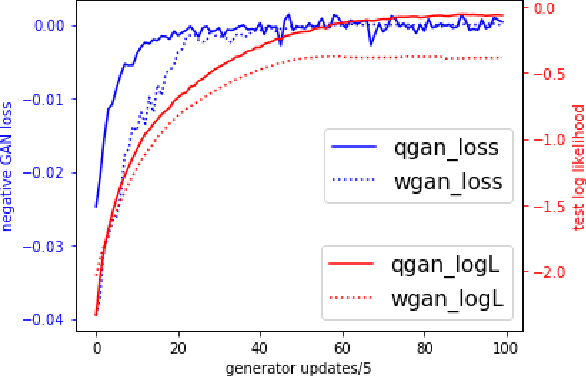
Generative adversarial training can be generally understood as minimizing certain moment matching loss defined by a set of discriminator functions, typically neural networks. The discriminator set should be large enough to be able to uniquely identify the true distribution (discriminative), and also be small enough to go beyond memorizing samples (generalizable). In this paper, we show that a discriminator set is guaranteed to be discriminative whenever its linear span is dense in the set of bounded continuous functions. This is a very mild condition satisfied even by neural networks with a single neuron. Further, we develop generalization bounds between the learned distribution and true distribution under different evaluation metrics. When evaluated with neural distance, our bounds show that generalization is guaranteed as long as the discriminator set is small enough, regardless of the size of the generator or hypothesis set. When evaluated with KL divergence, our bound provides an explanation on the counter-intuitive behaviors of testing likelihood in GAN training. Our analysis sheds lights on understanding the practical performance of GANs.
Constrained Convolutional-Recurrent Networks to Improve Speech Quality with Low Impact on Recognition Accuracy
Feb 16, 2018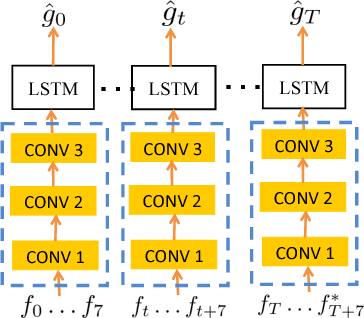
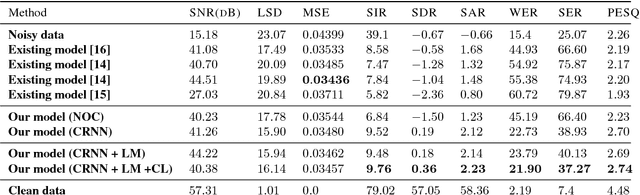
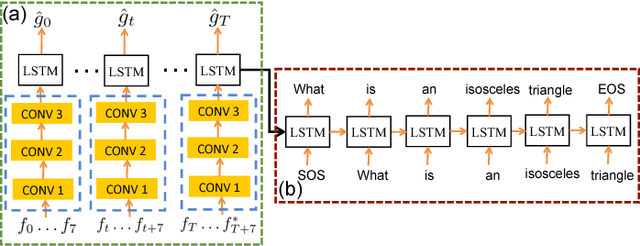

For a speech-enhancement algorithm, it is highly desirable to simultaneously improve perceptual quality and recognition rate. Thanks to computational costs and model complexities, it is challenging to train a model that effectively optimizes both metrics at the same time. In this paper, we propose a method for speech enhancement that combines local and global contextual structures information through convolutional-recurrent neural networks that improves perceptual quality. At the same time, we introduce a new constraint on the objective function using a language model/decoder that limits the impact on recognition rate. Based on experiments conducted with real user data, we demonstrate that our new context-augmented machine-learning approach for speech enhancement improves PESQ and WER by an additional 24.5% and 51.3%, respectively, when compared to the best-performing methods in the literature.
From Eliza to XiaoIce: Challenges and Opportunities with Social Chatbots
Feb 09, 2018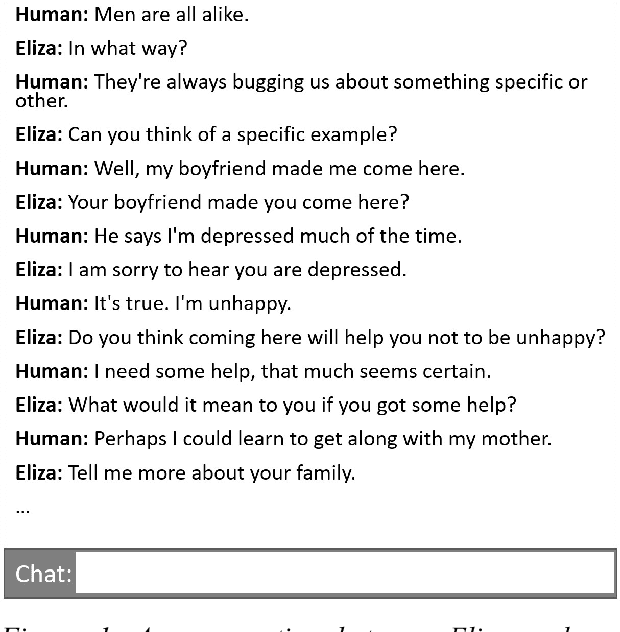
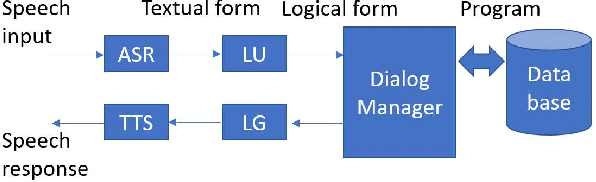

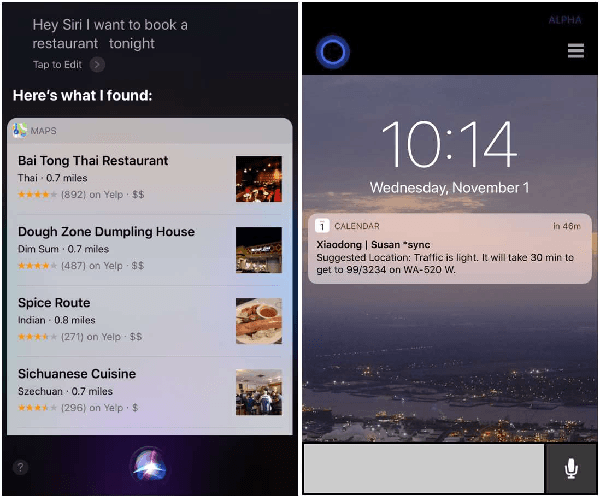
Conversational systems have come a long way since their inception in the 1960s. After decades of research and development, we've seen progress from Eliza and Parry in the 60's and 70's, to task-completion systems as in the DARPA Communicator program in the 2000s, to intelligent personal assistants such as Siri in the 2010s, to today's social chatbots like XiaoIce. Social chatbots' appeal lies not only in their ability to respond to users' diverse requests, but also in being able to establish an emotional connection with users. The latter is done by satisfying users' need for communication, affection, as well as social belonging. To further the advancement and adoption of social chatbots, their design must focus on user engagement and take both intellectual quotient (IQ) and emotional quotient (EQ) into account. Users should want to engage with a social chatbot; as such, we define the success metric for social chatbots as conversation-turns per session (CPS). Using XiaoIce as an illustrative example, we discuss key technologies in building social chatbots from core chat to visual awareness to skills. We also show how XiaoIce can dynamically recognize emotion and engage the user throughout long conversations with appropriate interpersonal responses. As we become the first generation of humans ever living with AI, we have a responsibility to design social chatbots to be both useful and empathetic, so they will become ubiquitous and help society as a whole.
Tensor Product Generation Networks for Deep NLP Modeling
Dec 16, 2017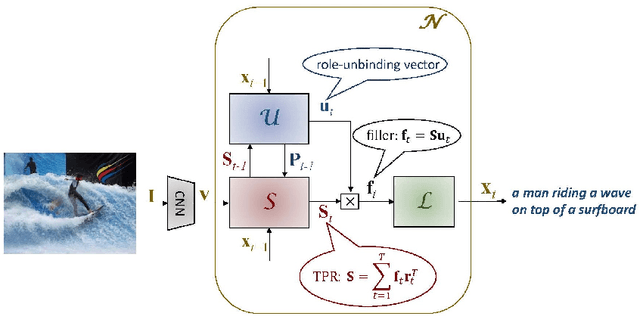

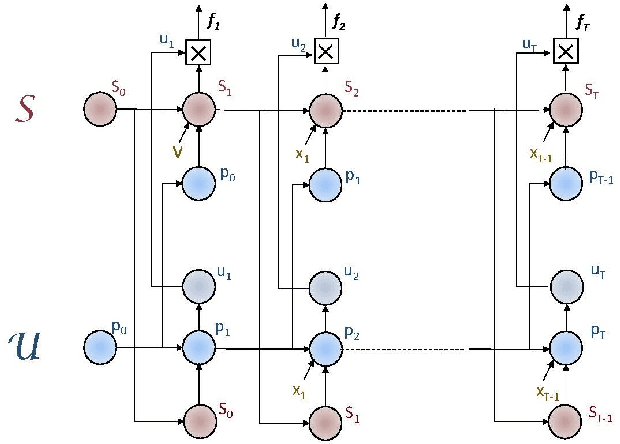
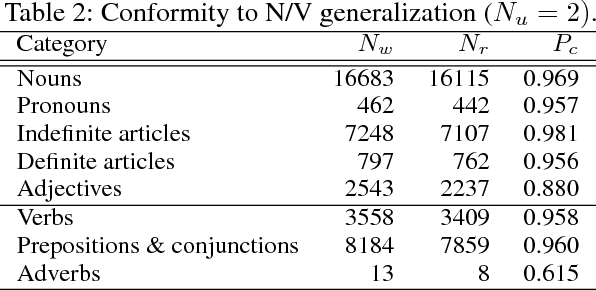
We present a new approach to the design of deep networks for natural language processing (NLP), based on the general technique of Tensor Product Representations (TPRs) for encoding and processing symbol structures in distributed neural networks. A network architecture --- the Tensor Product Generation Network (TPGN) --- is proposed which is capable in principle of carrying out TPR computation, but which uses unconstrained deep learning to design its internal representations. Instantiated in a model for image-caption generation, TPGN outperforms LSTM baselines when evaluated on the COCO dataset. The TPR-capable structure enables interpretation of internal representations and operations, which prove to contain considerable grammatical content. Our caption-generation model can be interpreted as generating sequences of grammatical categories and retrieving words by their categories from a plan encoded as a distributed representation.