 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Reinforced Instruction Attacker for Robust Vision-Language Navigation
Jul 23, 2021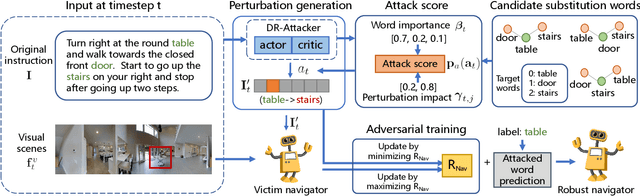
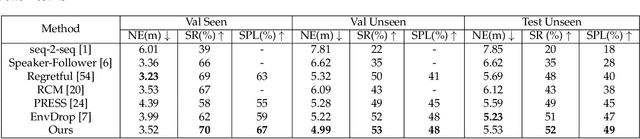
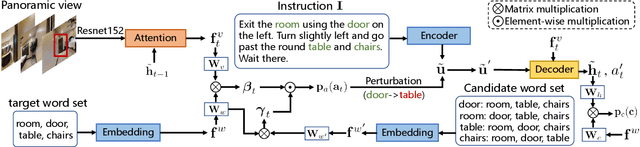

Language instruction plays an essential role in the natural language grounded navigation tasks. However, navigators trained with limited human-annotated instructions may have difficulties in accurately capturing key information from the complicated instruction at different timesteps, leading to poor navigation performance. In this paper, we exploit to train a more robust navigator which is capable of dynamically extracting crucial factors from the long instruction, by using an adversarial attacking paradigm. Specifically, we propose a Dynamic Reinforced Instruction Attacker (DR-Attacker), which learns to mislead the navigator to move to the wrong target by destroying the most instructive information in instructions at different timesteps. By formulating the perturbation generation as a Markov Decision Process, DR-Attacker is optimized by the reinforcement learning algorithm to generate perturbed instructions sequentially during the navigation, according to a learnable attack score. Then, the perturbed instructions, which serve as hard samples, are used for improving the robustness of the navigator with an effective adversarial training strategy and an auxiliary self-supervised reasoning task. Experimental results on both Vision-and-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks show the superiority of our proposed method over state-of-the-art methods. Moreover, the visualization analysis shows the effectiveness of the proposed DR-Attacker, which can successfully attack crucial information in the instructions at different timesteps. Code is available at https://github.com/expectorlin/DR-Attacker.
* Accepted by TPAMI 2021
Don't Take It Literally: An Edit-Invariant Sequence Loss for Text Generation
Jul 23, 2021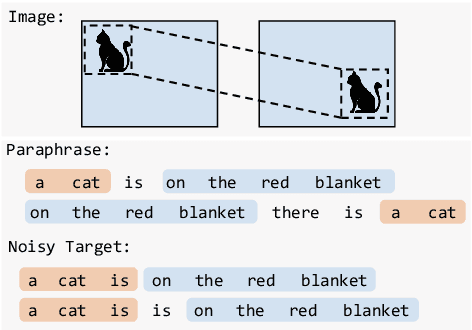
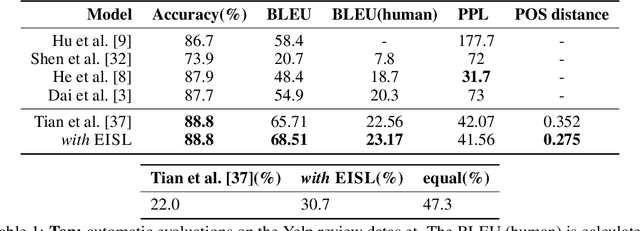
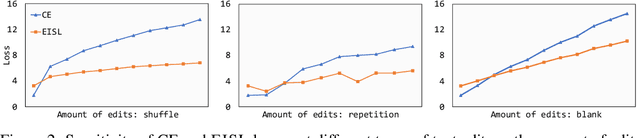
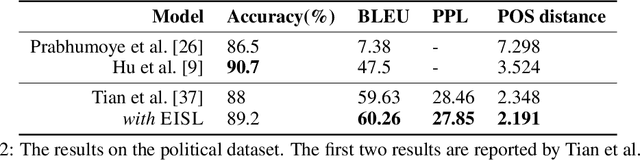
Neural text generation models are typically trained by maximizing log-likelihood with the sequence cross entropy loss, which encourages an exact token-by-token match between a target sequence with a generated sequence. Such training objective is sub-optimal when the target sequence not perfect, e.g., when the target sequence is corrupted with noises, or when only weak sequence supervision is available. To address this challenge, we propose a novel Edit-Invariant Sequence Loss (EISL), which computes the matching loss of a target n-gram with all n-grams in the generated sequence. EISL draws inspirations from convolutional networks (ConvNets) which are shift-invariant to images, hence is robust to the shift of n-grams to tolerate edits in the target sequences. Moreover, the computation of EISL is essentially a convolution operation with target n-grams as kernels, which is easy to implement with existing libraries. To demonstrate the effectiveness of EISL, we conduct experiments on three tasks: machine translation with noisy target sequences, unsupervised text style transfer, and non-autoregressive machine translation. Experimental results show our method significantly outperforms cross entropy loss on these three tasks.
AutoBERT-Zero: Evolving BERT Backbone from Scratch
Jul 15, 2021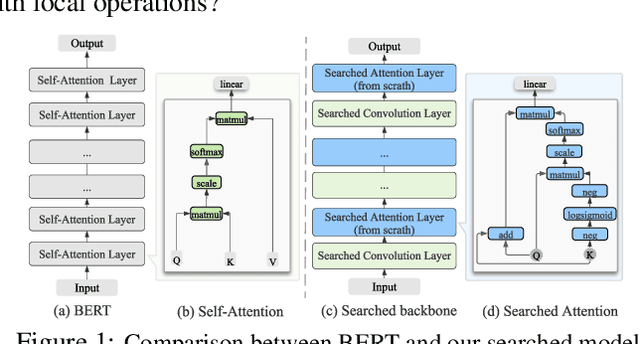

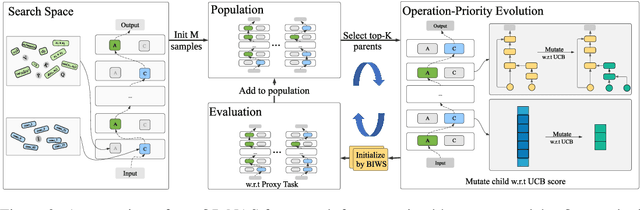
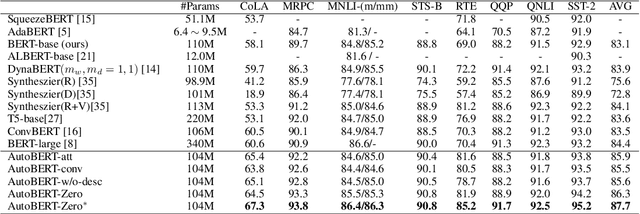
Transformer-based pre-trained language models like BERT and its variants have recently achieved promising performance in various natural language processing (NLP) tasks. However, the conventional paradigm constructs the backbone by purely stacking the manually designed global self-attention layers, introducing inductive bias and thus leading to sub-optimal. In this work, we propose an Operation-Priority Neural Architecture Search (OP-NAS) algorithm to automatically search for promising hybrid backbone architectures. Our well-designed search space (i) contains primitive math operations in the intra-layer level to explore novel attention structures, and (ii) leverages convolution blocks to be the supplementary for attention structure in the inter-layer level to better learn local dependency. We optimize both the search algorithm and evaluation of candidate models to boost the efficiency of our proposed OP-NAS. Specifically, we propose Operation-Priority (OP) evolution strategy to facilitate model search via balancing exploration and exploitation. Furthermore, we design a Bi-branch Weight-Sharing (BIWS) training strategy for fast model evaluation. Extensive experiments show that the searched architecture (named AutoBERT-Zero) significantly outperforms BERT and its variants of different model capacities in various downstream tasks, proving the architecture's transfer and generalization abilities. Remarkably, AutoBERT-Zero-base outperforms RoBERTa-base (using much more data) and BERT-large (with much larger model size) by 2.4 and 1.4 higher score on GLUE test set. Code and pre-trained models will be made publicly available.
Deep Learning for Embodied Vision Navigation: A Survey
Jul 07, 2021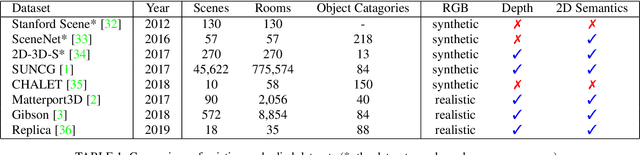

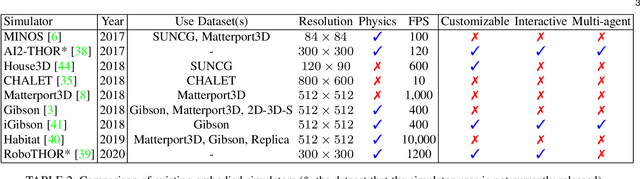
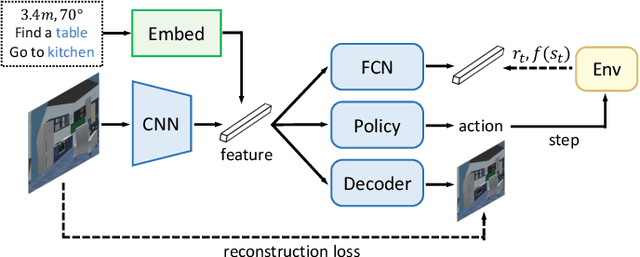
Navigation is one of the fundamental features of a autonomous robot. And the ability of long-term navigation with semantic instruction is a `holy grail` goals of intelligent robots. The development of 3D simulation technology provide a large scale of data to simulate the real-world environment. The deep learning proves its ability to robustly learn various embodied navigation tasks. However, deep learning on embodied navigation is still in its infancy due to the unique challenges faced by the navigation exploration and learning from partial observed visual input. Recently, deep learning in embodied navigation has become even thriving, with numerous methods have been proposed to tackle different challenges in this area. To give a promising direction for future research, in this paper, we present a comprehensive review of embodied navigation tasks and the recent progress in deep learning based methods. It includes two major tasks: target-oriented navigation and the instruction-oriented navigation.
Neural-Symbolic Solver for Math Word Problems with Auxiliary Tasks
Jul 03, 2021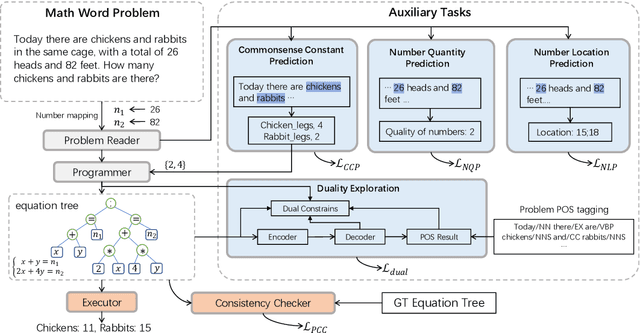
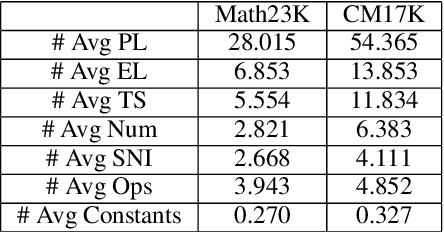
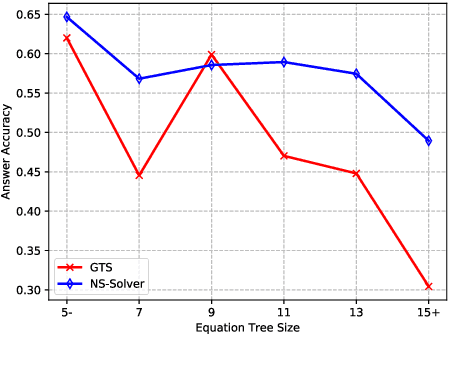
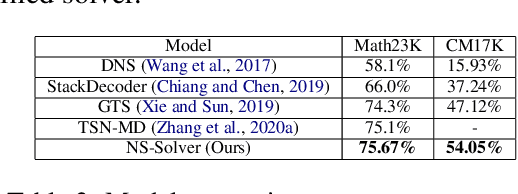
Previous math word problem solvers following the encoder-decoder paradigm fail to explicitly incorporate essential math symbolic constraints, leading to unexplainable and unreasonable predictions. Herein, we propose Neural-Symbolic Solver (NS-Solver) to explicitly and seamlessly incorporate different levels of symbolic constraints by auxiliary tasks. Our NS-Solver consists of a problem reader to encode problems, a programmer to generate symbolic equations, and a symbolic executor to obtain answers. Along with target expression supervision, our solver is also optimized via 4 new auxiliary objectives to enforce different symbolic reasoning: a) self-supervised number prediction task predicting both number quantity and number locations; b) commonsense constant prediction task predicting what prior knowledge (e.g. how many legs a chicken has) is required; c) program consistency checker computing the semantic loss between predicted equation and target equation to ensure reasonable equation mapping; d) duality exploiting task exploiting the quasi duality between symbolic equation generation and problem's part-of-speech generation to enhance the understanding ability of a solver. Besides, to provide a more realistic and challenging benchmark for developing a universal and scalable solver, we also construct a new large-scale MWP benchmark CM17K consisting of 4 kinds of MWPs (arithmetic, one-unknown linear, one-unknown non-linear, equation set) with more than 17K samples. Extensive experiments on Math23K and our CM17k demonstrate the superiority of our NS-Solver compared to state-of-the-art methods.
SODA10M: Towards Large-Scale Object Detection Benchmark for Autonomous Driving
Jun 22, 2021

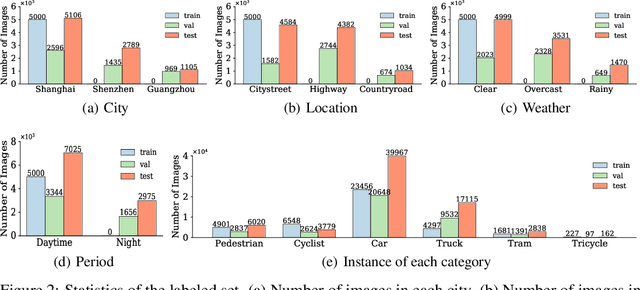
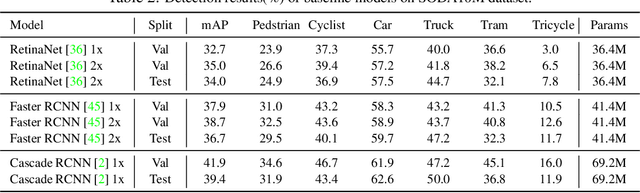
Aiming at facilitating a real-world, ever-evolving and scalable autonomous driving system, we present a large-scale benchmark for standardizing the evaluation of different self-supervised and semi-supervised approaches by learning from raw data, which is the first and largest benchmark to date. Existing autonomous driving systems heavily rely on `perfect' visual perception models (e.g., detection) trained using extensive annotated data to ensure the safety. However, it is unrealistic to elaborately label instances of all scenarios and circumstances (e.g., night, extreme weather, cities) when deploying a robust autonomous driving system. Motivated by recent powerful advances of self-supervised and semi-supervised learning, a promising direction is to learn a robust detection model by collaboratively exploiting large-scale unlabeled data and few labeled data. Existing dataset (e.g., KITTI, Waymo) either provides only a small amount of data or covers limited domains with full annotation, hindering the exploration of large-scale pre-trained models. Here, we release a Large-Scale Object Detection benchmark for Autonomous driving, named as SODA10M, containing 10 million unlabeled images and 20K images labeled with 6 representative object categories. To improve diversity, the images are collected every ten seconds per frame within 32 different cities under different weather conditions, periods and location scenes. We provide extensive experiments and deep analyses of existing supervised state-of-the-art detection models, popular self-supervised and semi-supervised approaches, and some insights about how to develop future models. The data and more up-to-date information have been released at https://soda-2d.github.io.
One Million Scenes for Autonomous Driving: ONCE Dataset
Jun 21, 2021
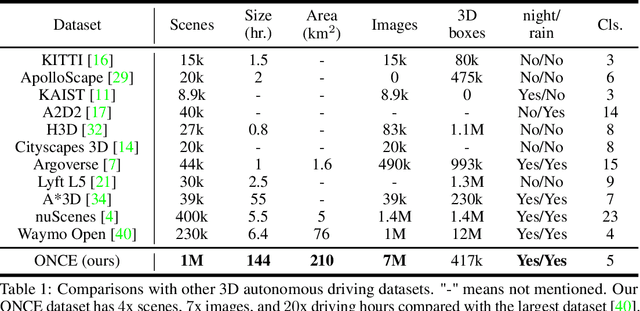
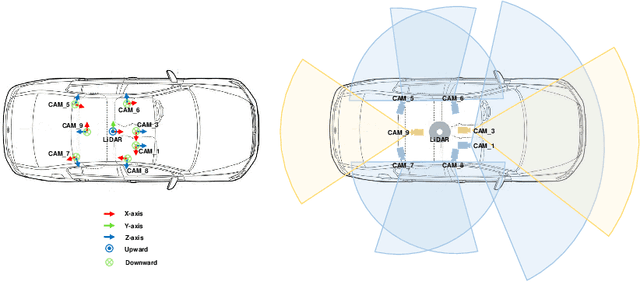

Current perception models in autonomous driving have become notorious for greatly relying on a mass of annotated data to cover unseen cases and address the long-tail problem. On the other hand, learning from unlabeled large-scale collected data and incrementally self-training powerful recognition models have received increasing attention and may become the solutions of next-generation industry-level powerful and robust perception models in autonomous driving. However, the research community generally suffered from data inadequacy of those essential real-world scene data, which hampers the future exploration of fully/semi/self-supervised methods for 3D perception. In this paper, we introduce the ONCE (One millioN sCenEs) dataset for 3D object detection in the autonomous driving scenario. The ONCE dataset consists of 1 million LiDAR scenes and 7 million corresponding camera images. The data is selected from 144 driving hours, which is 20x longer than the largest 3D autonomous driving dataset available (e.g. nuScenes and Waymo), and it is collected across a range of different areas, periods and weather conditions. To facilitate future research on exploiting unlabeled data for 3D detection, we additionally provide a benchmark in which we reproduce and evaluate a variety of self-supervised and semi-supervised methods on the ONCE dataset. We conduct extensive analyses on those methods and provide valuable observations on their performance related to the scale of used data. Data, code, and more information are available at https://once-for-auto-driving.github.io/index.html.
Prototypical Graph Contrastive Learning
Jun 17, 2021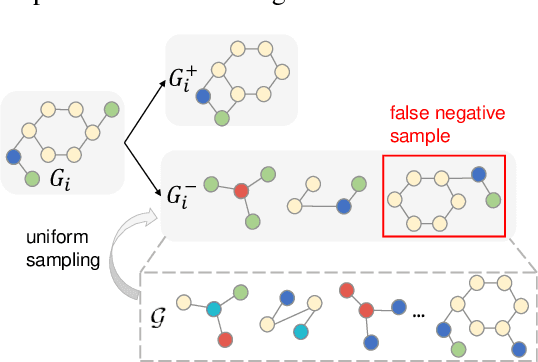
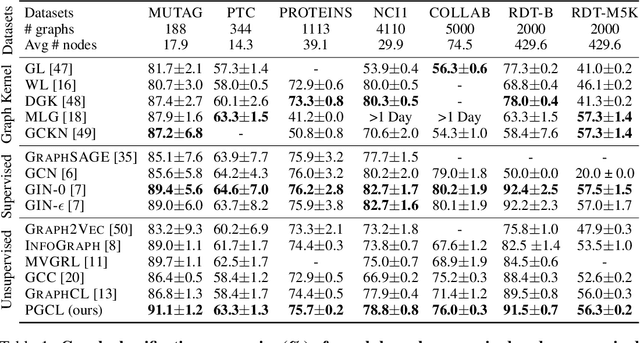
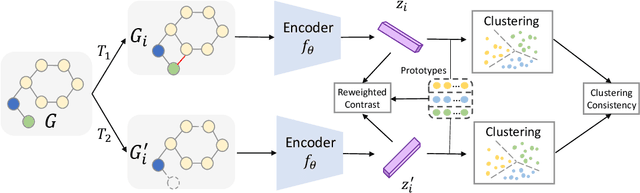
Graph-level representations are critical in various real-world applications, such as predicting the properties of molecules. But in practice, precise graph annotations are generally very expensive and time-consuming. To address this issue, graph contrastive learning constructs instance discrimination task which pulls together positive pairs (augmentation pairs of the same graph) and pushes away negative pairs (augmentation pairs of different graphs) for unsupervised representation learning. However, since for a query, its negatives are uniformly sampled from all graphs, existing methods suffer from the critical sampling bias issue, i.e., the negatives likely having the same semantic structure with the query, leading to performance degradation. To mitigate this sampling bias issue, in this paper, we propose a Prototypical Graph Contrastive Learning (PGCL) approach. Specifically, PGCL models the underlying semantic structure of the graph data via clustering semantically similar graphs into the same group, and simultaneously encourages the clustering consistency for different augmentations of the same graph. Then given a query, it performs negative sampling via drawing the graphs from those clusters that differ from the cluster of query, which ensures the semantic difference between query and its negative samples. Moreover, for a query, PGCL further reweights its negative samples based on the distance between their prototypes (cluster centroids) and the query prototype such that those negatives having moderate prototype distance enjoy relatively large weights. This reweighting strategy is proved to be more effective than uniform sampling. Experimental results on various graph benchmarks testify the advantages of our PGCL over state-of-the-art methods.
Vision-Language Navigation with Random Environmental Mixup
Jun 15, 2021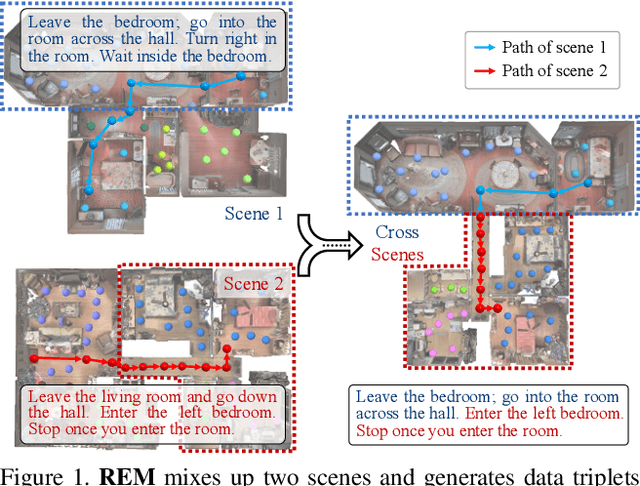
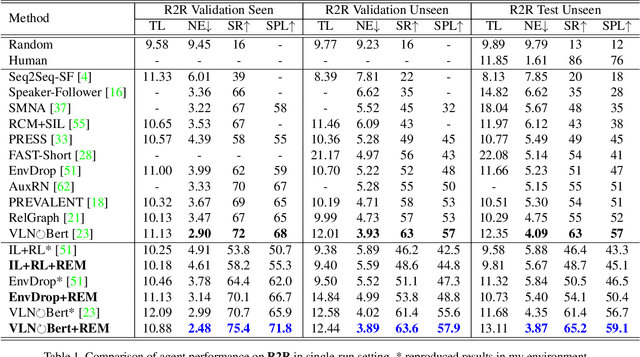
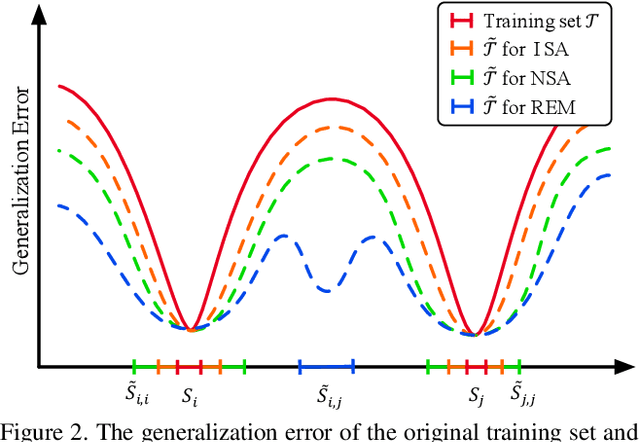
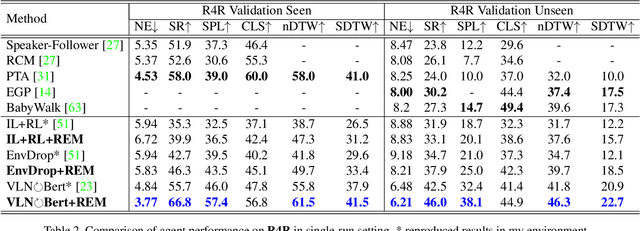
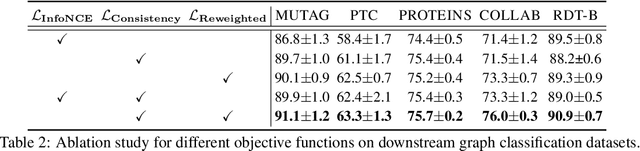
Vision-language Navigation (VLN) tasks require an agent to navigate step-by-step while perceiving the visual observations and comprehending a natural language instruction. Large data bias, which is caused by the disparity ratio between the small data scale and large navigation space, makes the VLN task challenging. Previous works have proposed various data augmentation methods to reduce data bias. However, these works do not explicitly reduce the data bias across different house scenes. Therefore, the agent would overfit to the seen scenes and achieve poor navigation performance in the unseen scenes. To tackle this problem, we propose the Random Environmental Mixup (REM) method, which generates cross-connected house scenes as augmented data via mixuping environment. Specifically, we first select key viewpoints according to the room connection graph for each scene. Then, we cross-connect the key views of different scenes to construct augmented scenes. Finally, we generate augmented instruction-path pairs in the cross-connected scenes. The experimental results on benchmark datasets demonstrate that our augmentation data via REM help the agent reduce its performance gap between the seen and unseen environment and improve the overall performance, making our model the best existing approach on the standard VLN benchmark.
GeoQA: A Geometric Question Answering Benchmark Towards Multimodal Numerical Reasoning
Jun 08, 2021
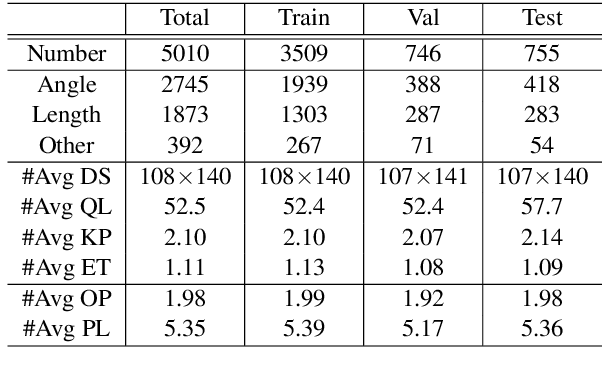

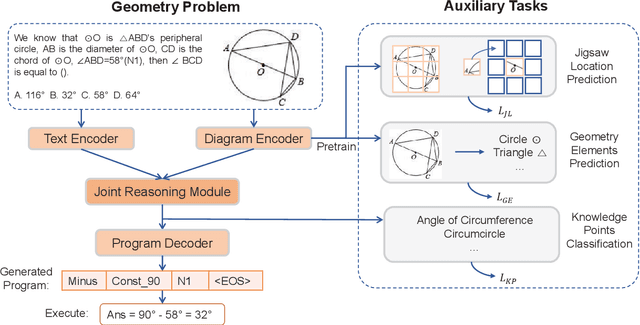
Automatic math problem solving has recently attracted increasing attention as a long-standing AI benchmark. In this paper, we focus on solving geometric problems, which requires a comprehensive understanding of textual descriptions, visual diagrams, and theorem knowledge. However, the existing methods were highly dependent on handcraft rules and were merely evaluated on small-scale datasets. Therefore, we propose a Geometric Question Answering dataset GeoQA, containing 5,010 geometric problems with corresponding annotated programs, which illustrate the solving process of the given problems. Compared with another publicly available dataset GeoS, GeoQA is 25 times larger, in which the program annotations can provide a practical testbed for future research on explicit and explainable numerical reasoning. Moreover, we introduce a Neural Geometric Solver (NGS) to address geometric problems by comprehensively parsing multimodal information and generating interpretable programs. We further add multiple self-supervised auxiliary tasks on NGS to enhance cross-modal semantic representation. Extensive experiments on GeoQA validate the effectiveness of our proposed NGS and auxiliary tasks. However, the results are still significantly lower than human performance, which leaves large room for future research. Our benchmark and code are released at https://github.com/chen-judge/GeoQA .