 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
P2P: A Poison-to-Poison Remedy for Reliable Backdoor Defense in LLMs
Oct 06, 2025During fine-tuning, large language models (LLMs) are increasingly vulnerable to data-poisoning backdoor attacks, which compromise their reliability and trustworthiness. However, existing defense strategies suffer from limited generalization: they only work on specific attack types or task settings. In this study, we propose Poison-to-Poison (P2P), a general and effective backdoor defense algorithm. P2P injects benign triggers with safe alternative labels into a subset of training samples and fine-tunes the model on this re-poisoned dataset by leveraging prompt-based learning. This enforces the model to associate trigger-induced representations with safe outputs, thereby overriding the effects of original malicious triggers. Thanks to this robust and generalizable trigger-based fine-tuning, P2P is effective across task settings and attack types. Theoretically and empirically, we show that P2P can neutralize malicious backdoors while preserving task performance. We conduct extensive experiments on classification, mathematical reasoning, and summary generation tasks, involving multiple state-of-the-art LLMs. The results demonstrate that our P2P algorithm significantly reduces the attack success rate compared with baseline models. We hope that the P2P can serve as a guideline for defending against backdoor attacks and foster the development of a secure and trustworthy LLM community.
Graph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning
Jul 29, 2025Retrieval-Augmented Generation (RAG) mitigates hallucination in LLMs by incorporating external knowledge, but relies on chunk-based retrieval that lacks structural semantics. GraphRAG methods improve RAG by modeling knowledge as entity-relation graphs, but still face challenges in high construction cost, fixed one-time retrieval, and reliance on long-context reasoning and prompt design. To address these challenges, we propose Graph-R1, an agentic GraphRAG framework via end-to-end reinforcement learning (RL). It introduces lightweight knowledge hypergraph construction, models retrieval as a multi-turn agent-environment interaction, and optimizes the agent process via an end-to-end reward mechanism. Experiments on standard RAG datasets show that Graph-R1 outperforms traditional GraphRAG and RL-enhanced RAG methods in reasoning accuracy, retrieval efficiency, and generation quality.
Detecting Harmful Memes with Decoupled Understanding and Guided CoT Reasoning
Jun 10, 2025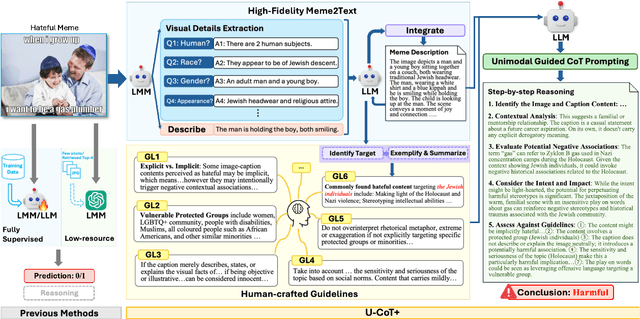
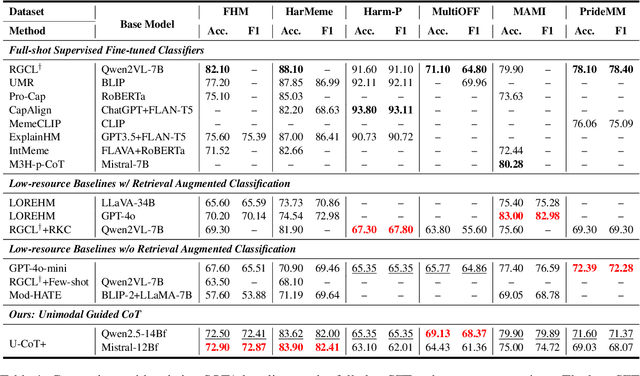
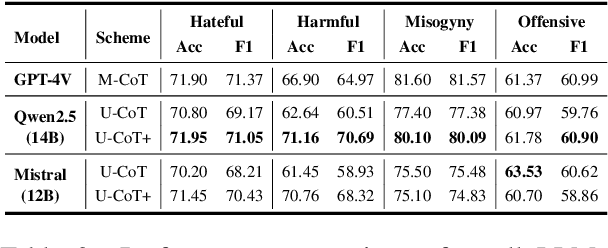
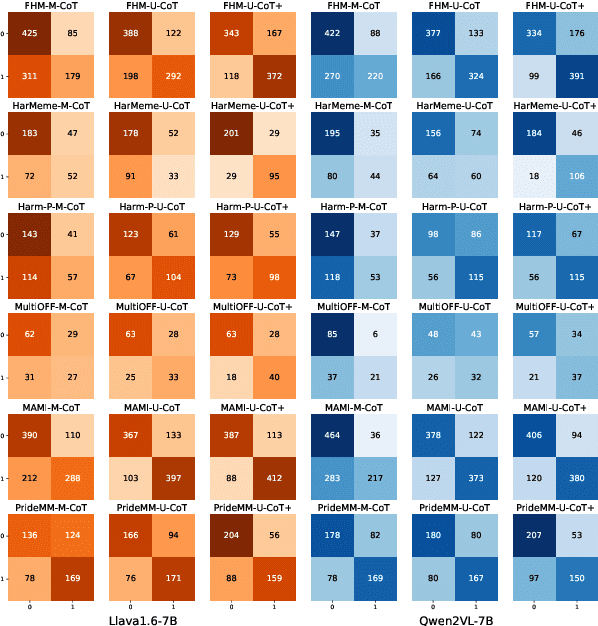
Detecting harmful memes is essential for maintaining the integrity of online environments. However, current approaches often struggle with resource efficiency, flexibility, or explainability, limiting their practical deployment in content moderation systems. To address these challenges, we introduce U-CoT+, a novel framework for harmful meme detection. Instead of relying solely on prompting or fine-tuning multimodal models, we first develop a high-fidelity meme-to-text pipeline that converts visual memes into detail-preserving textual descriptions. This design decouples meme interpretation from meme classification, thus avoiding immediate reasoning over complex raw visual content and enabling resource-efficient harmful meme detection with general large language models (LLMs). Building on these textual descriptions, we further incorporate targeted, interpretable human-crafted guidelines to guide models' reasoning under zero-shot CoT prompting. As such, this framework allows for easy adaptation to different harmfulness detection criteria across platforms, regions, and over time, offering high flexibility and explainability. Extensive experiments on seven benchmark datasets validate the effectiveness of our framework, highlighting its potential for explainable and low-resource harmful meme detection using small-scale LLMs. Codes and data are available at: https://anonymous.4open.science/r/HMC-AF2B/README.md.
Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings
Jun 05, 2025Despite the strong performance of ColPali/ColQwen2 in Visualized Document Retrieval (VDR), it encodes each page into multiple patch-level embeddings and leads to excessive memory usage. This empirical study investigates methods to reduce patch embeddings per page at minimum performance degradation. We evaluate two token-reduction strategies: token pruning and token merging. Regarding token pruning, we surprisingly observe that a simple random strategy outperforms other sophisticated pruning methods, though still far from satisfactory. Further analysis reveals that pruning is inherently unsuitable for VDR as it requires removing certain page embeddings without query-specific information. Turning to token merging (more suitable for VDR), we search for the optimal combinations of merging strategy across three dimensions and develop Light-ColPali/ColQwen2. It maintains 98.2% of retrieval performance with only 11.8% of original memory usage, and preserves 94.6% effectiveness at 2.8% memory footprint. We expect our empirical findings and resulting Light-ColPali/ColQwen2 offer valuable insights and establish a competitive baseline for future research towards efficient VDR.
SCOPE: Compress Mathematical Reasoning Steps for Efficient Automated Process Annotation
May 20, 2025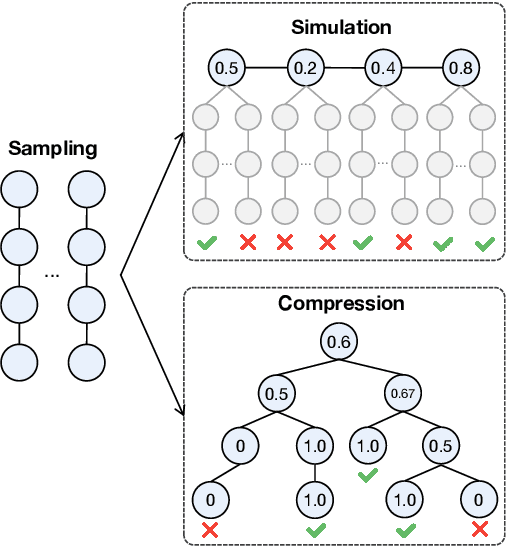
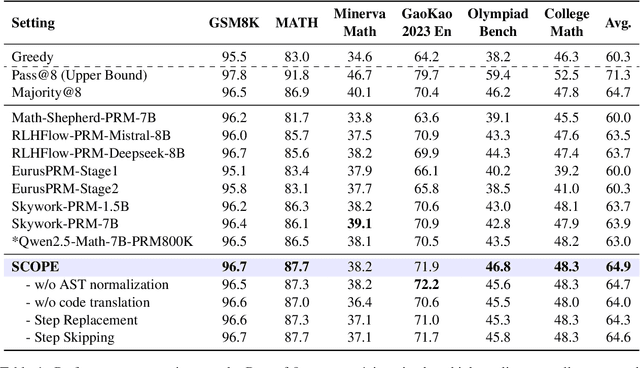
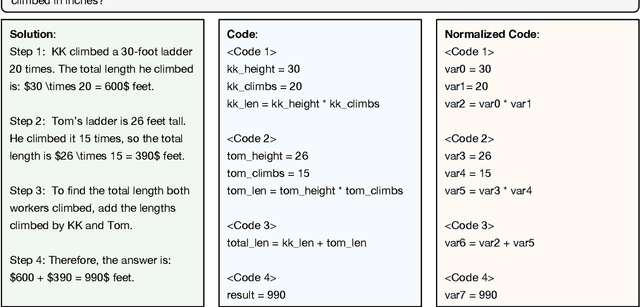
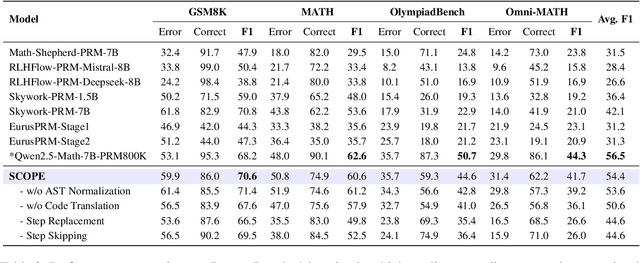
Process Reward Models (PRMs) have demonstrated promising results in mathematical reasoning, but existing process annotation approaches, whether through human annotations or Monte Carlo simulations, remain computationally expensive. In this paper, we introduce Step COmpression for Process Estimation (SCOPE), a novel compression-based approach that significantly reduces annotation costs. We first translate natural language reasoning steps into code and normalize them through Abstract Syntax Tree, then merge equivalent steps to construct a prefix tree. Unlike simulation-based methods that waste numerous samples on estimation, SCOPE leverages a compression-based prefix tree where each root-to-leaf path serves as a training sample, reducing the complexity from $O(NMK)$ to $O(N)$. We construct a large-scale dataset containing 196K samples with only 5% of the computational resources required by previous methods. Empirical results demonstrate that PRMs trained on our dataset consistently outperform existing automated annotation approaches on both Best-of-N strategy and ProcessBench.
Sailing AI by the Stars: A Survey of Learning from Rewards in Post-Training and Test-Time Scaling of Large Language Models
May 05, 2025



Recent developments in Large Language Models (LLMs) have shifted from pre-training scaling to post-training and test-time scaling. Across these developments, a key unified paradigm has arisen: Learning from Rewards, where reward signals act as the guiding stars to steer LLM behavior. It has underpinned a wide range of prevalent techniques, such as reinforcement learning (in RLHF, DPO, and GRPO), reward-guided decoding, and post-hoc correction. Crucially, this paradigm enables the transition from passive learning from static data to active learning from dynamic feedback. This endows LLMs with aligned preferences and deep reasoning capabilities. In this survey, we present a comprehensive overview of the paradigm of learning from rewards. We categorize and analyze the strategies under this paradigm across training, inference, and post-inference stages. We further discuss the benchmarks for reward models and the primary applications. Finally we highlight the challenges and future directions. We maintain a paper collection at https://github.com/bobxwu/learning-from-rewards-llm-papers.
Aspect-Based Summarization with Self-Aspect Retrieval Enhanced Generation
Apr 17, 2025Aspect-based summarization aims to generate summaries tailored to specific aspects, addressing the resource constraints and limited generalizability of traditional summarization approaches. Recently, large language models have shown promise in this task without the need for training. However, they rely excessively on prompt engineering and face token limits and hallucination challenges, especially with in-context learning. To address these challenges, in this paper, we propose a novel framework for aspect-based summarization: Self-Aspect Retrieval Enhanced Summary Generation. Rather than relying solely on in-context learning, given an aspect, we employ an embedding-driven retrieval mechanism to identify its relevant text segments. This approach extracts the pertinent content while avoiding unnecessary details, thereby mitigating the challenge of token limits. Moreover, our framework optimizes token usage by deleting unrelated parts of the text and ensuring that the model generates output strictly based on the given aspect. With extensive experiments on benchmark datasets, we demonstrate that our framework not only achieves superior performance but also effectively mitigates the token limitation problem.
HyperGraphRAG: Retrieval-Augmented Generation with Hypergraph-Structured Knowledge Representation
Mar 27, 2025While standard Retrieval-Augmented Generation (RAG) based on chunks, GraphRAG structures knowledge as graphs to leverage the relations among entities. However, previous GraphRAG methods are limited by binary relations: one edge in the graph only connects two entities, which cannot well model the n-ary relations among more than two entities that widely exist in reality. To address this limitation, we propose HyperGraphRAG, a novel hypergraph-based RAG method that represents n-ary relational facts via hyperedges, modeling the complicated n-ary relations in the real world. To retrieve and generate over hypergraphs, we introduce a complete pipeline with a hypergraph construction method, a hypergraph retrieval strategy, and a hypergraph-guided generation mechanism. Experiments across medicine, agriculture, computer science, and law demonstrate that HyperGraphRAG outperforms standard RAG and GraphRAG in accuracy and generation quality.
Full-Step-DPO: Self-Supervised Preference Optimization with Step-wise Rewards for Mathematical Reasoning
Feb 20, 2025Direct Preference Optimization (DPO) often struggles with long-chain mathematical reasoning. Existing approaches, such as Step-DPO, typically improve this by focusing on the first erroneous step in the reasoning chain. However, they overlook all other steps and rely heavily on humans or GPT-4 to identify erroneous steps. To address these issues, we propose Full-Step-DPO, a novel DPO framework tailored for mathematical reasoning. Instead of optimizing only the first erroneous step, it leverages step-wise rewards from the entire reasoning chain. This is achieved by training a self-supervised process reward model, which automatically scores each step, providing rewards while avoiding reliance on external signals. Furthermore, we introduce a novel step-wise DPO loss, which dynamically updates gradients based on these step-wise rewards. This endows stronger reasoning capabilities to language models. Extensive evaluations on both in-domain and out-of-domain mathematical reasoning benchmarks across various base language models, demonstrate that Full-Step-DPO achieves superior performance compared to state-of-the-art baselines.