 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Compress Mathematical Reasoning Steps for Efficient Automated Process Annotation
Paper and Code
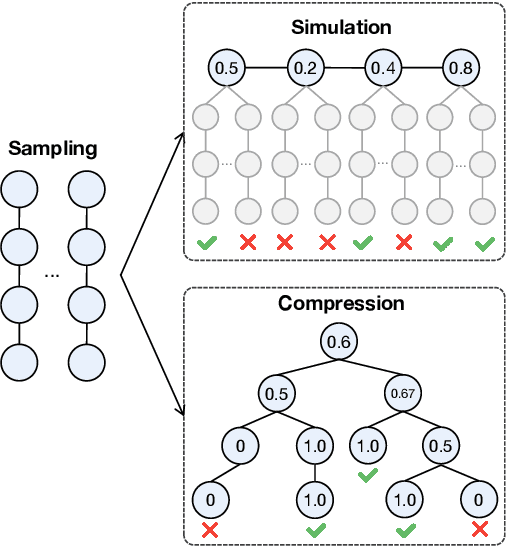
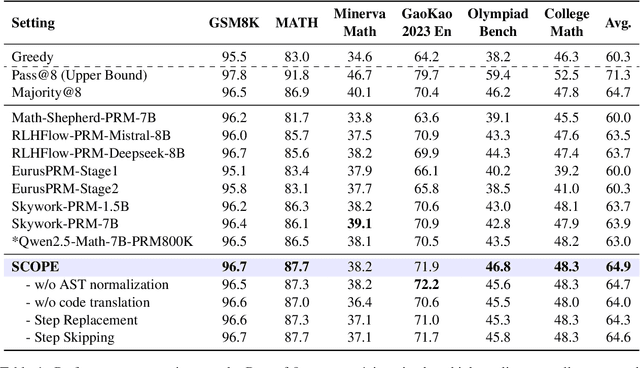
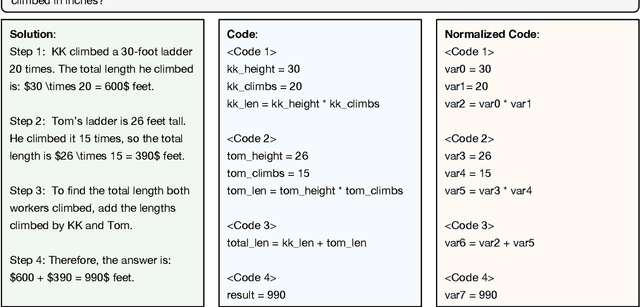
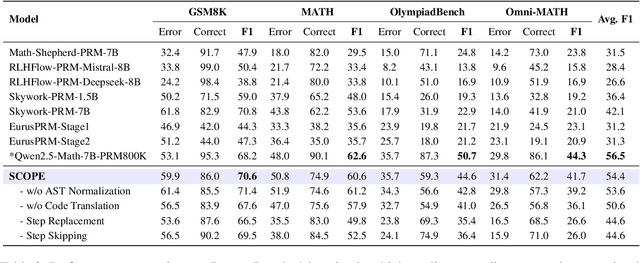
Process Reward Models (PRMs) have demonstrated promising results in mathematical reasoning, but existing process annotation approaches, whether through human annotations or Monte Carlo simulations, remain computationally expensive. In this paper, we introduce Step COmpression for Process Estimation (SCOPE), a novel compression-based approach that significantly reduces annotation costs. We first translate natural language reasoning steps into code and normalize them through Abstract Syntax Tree, then merge equivalent steps to construct a prefix tree. Unlike simulation-based methods that waste numerous samples on estimation, SCOPE leverages a compression-based prefix tree where each root-to-leaf path serves as a training sample, reducing the complexity from $O(NMK)$ to $O(N)$. We construct a large-scale dataset containing 196K samples with only 5% of the computational resources required by previous methods. Empirical results demonstrate that PRMs trained on our dataset consistently outperform existing automated annotation approaches on both Best-of-N strategy and ProcessBench.