 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Harmful Memes with Decoupled Understanding and Guided CoT Reasoning
Paper and Code
Jun 10, 2025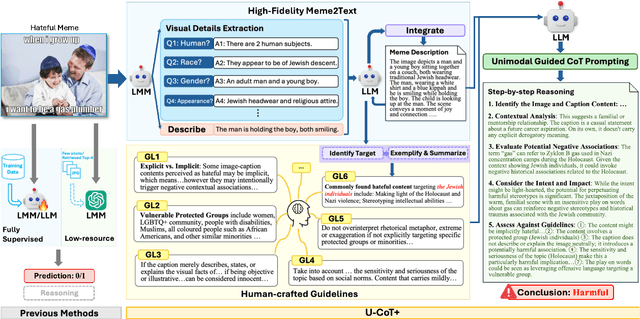
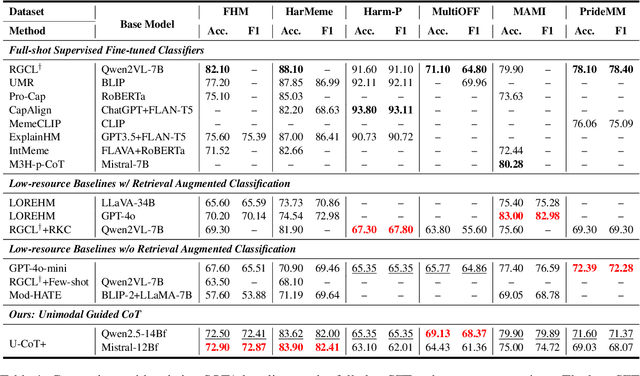
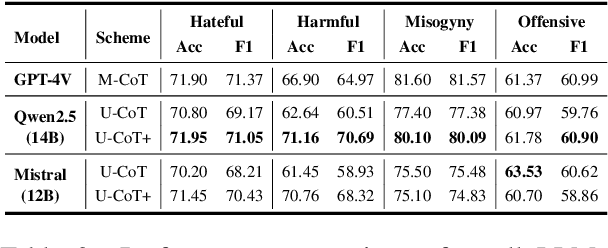
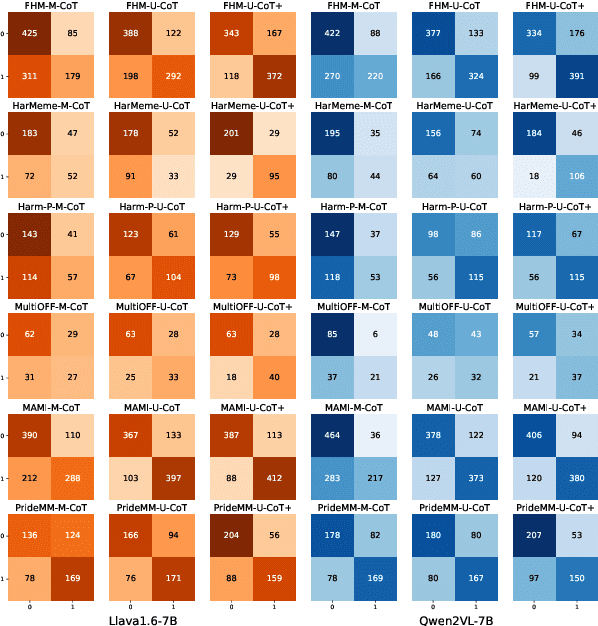
Detecting harmful memes is essential for maintaining the integrity of online environments. However, current approaches often struggle with resource efficiency, flexibility, or explainability, limiting their practical deployment in content moderation systems. To address these challenges, we introduce U-CoT+, a novel framework for harmful meme detection. Instead of relying solely on prompting or fine-tuning multimodal models, we first develop a high-fidelity meme-to-text pipeline that converts visual memes into detail-preserving textual descriptions. This design decouples meme interpretation from meme classification, thus avoiding immediate reasoning over complex raw visual content and enabling resource-efficient harmful meme detection with general large language models (LLMs). Building on these textual descriptions, we further incorporate targeted, interpretable human-crafted guidelines to guide models' reasoning under zero-shot CoT prompting. As such, this framework allows for easy adaptation to different harmfulness detection criteria across platforms, regions, and over time, offering high flexibility and explainability. Extensive experiments on seven benchmark datasets validate the effectiveness of our framework, highlighting its potential for explainable and low-resource harmful meme detection using small-scale LLMs. Codes and data are available at: https://anonymous.4open.science/r/HMC-AF2B/README.md.