 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-thinking and Re-labeling LIDC-IDRI for Robust Pulmonary Cancer Prediction
Jul 28, 2022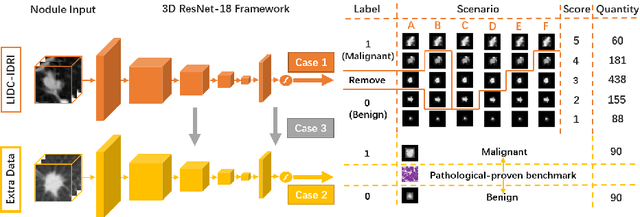
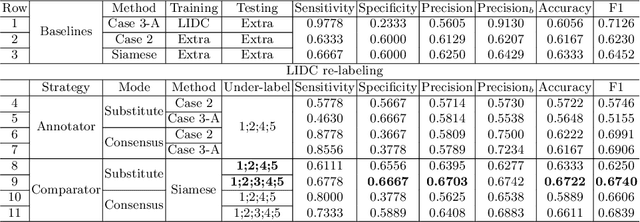
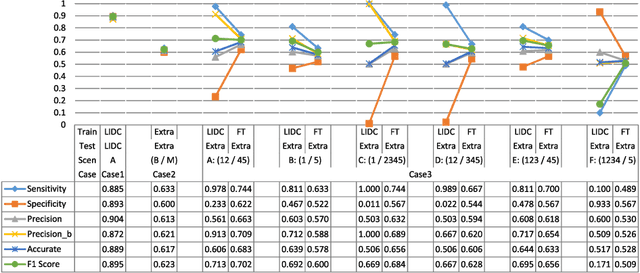
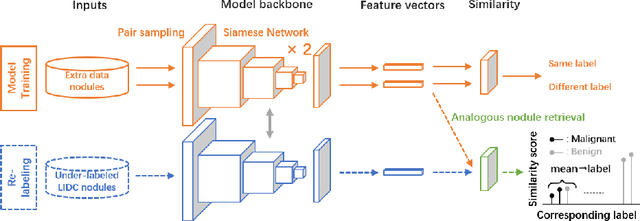
The LIDC-IDRI database is the most popular benchmark for lung cancer prediction. However, with subjective assessment from radiologists, nodules in LIDC may have entirely different malignancy annotations from the pathological ground truth, introducing label assignment errors and subsequent supervision bias during training. The LIDC database thus requires more objective labels for learning-based cancer prediction. Based on an extra small dataset containing 180 nodules diagnosed by pathological examination, we propose to re-label LIDC data to mitigate the effect of original annotation bias verified on this robust benchmark. We demonstrate in this paper that providing new labels by similar nodule retrieval based on metric learning would be an effective re-labeling strategy. Training on these re-labeled LIDC nodules leads to improved model performance, which is enhanced when new labels of uncertain nodules are added. We further infer that re-labeling LIDC is current an expedient way for robust lung cancer prediction while building a large pathological-proven nodule database provides the long-term solution.
Tackling Long-Tailed Category Distribution Under Domain Shifts
Jul 20, 2022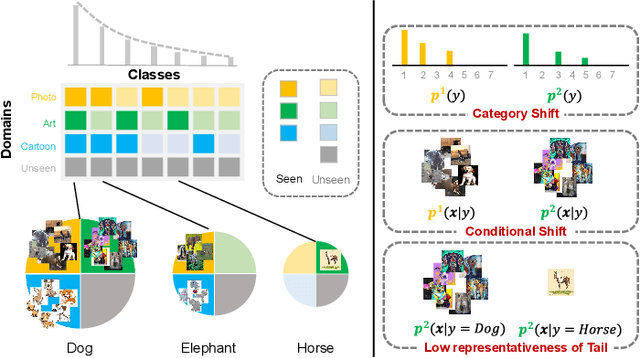
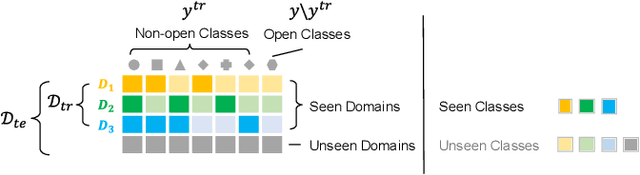
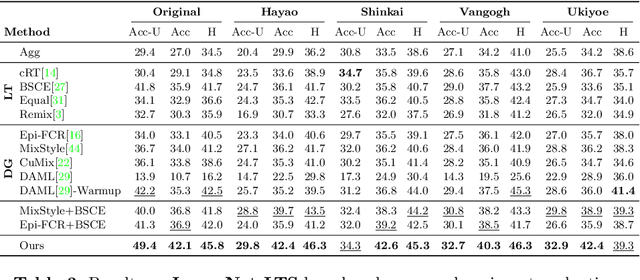
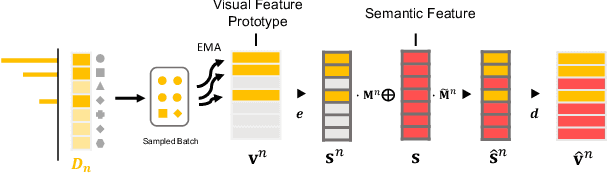
Machine learning models fail to perform well on real-world applications when 1) the category distribution P(Y) of the training dataset suffers from long-tailed distribution and 2) the test data is drawn from different conditional distributions P(X|Y). Existing approaches cannot handle the scenario where both issues exist, which however is common for real-world applications. In this study, we took a step forward and looked into the problem of long-tailed classification under domain shifts. We designed three novel core functional blocks including Distribution Calibrated Classification Loss, Visual-Semantic Mapping and Semantic-Similarity Guided Augmentation. Furthermore, we adopted a meta-learning framework which integrates these three blocks to improve domain generalization on unseen target domains. Two new datasets were proposed for this problem, named AWA2-LTS and ImageNet-LTS. We evaluated our method on the two datasets and extensive experimental results demonstrate that our proposed method can achieve superior performance over state-of-the-art long-tailed/domain generalization approaches and the combinations. Source codes and datasets can be found at our project page https://xiaogu.site/LTDS.
Faithful learning with sure data for lung nodule diagnosis
Feb 25, 2022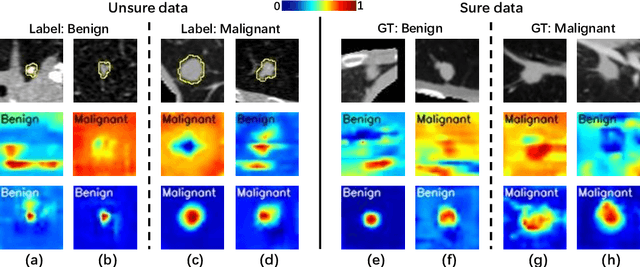
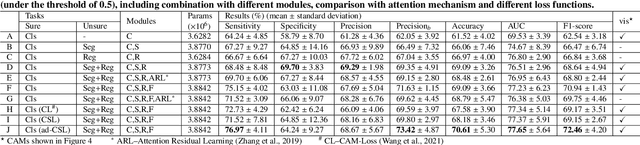
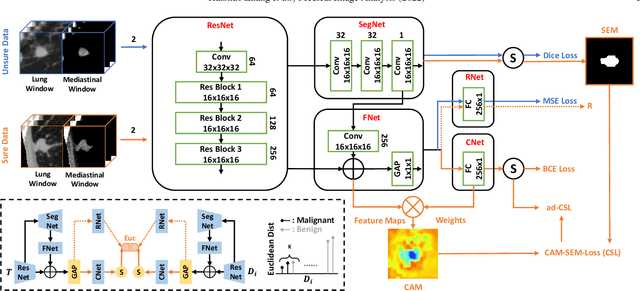

Recent evolution in deep learning has proven its value for CT-based lung nodule classification. Most current techniques are intrinsically black-box systems, suffering from two generalizability issues in clinical practice. First, benign-malignant discrimination is often assessed by human observers without pathologic diagnoses at the nodule level. We termed these data as "unsure data". Second, a classifier does not necessarily acquire reliable nodule features for stable learning and robust prediction with patch-level labels during learning. In this study, we construct a sure dataset with pathologically-confirmed labels and propose a collaborative learning framework to facilitate sure nodule classification by integrating unsure data knowledge through nodule segmentation and malignancy score regression. A loss function is designed to learn reliable features by introducing interpretability constraints regulated with nodule segmentation maps. Furthermore, based on model inference results that reflect the understanding from both machine and experts, we explore a new nodule analysis method for similar historical nodule retrieval and interpretable diagnosis. Detailed experimental results demonstrate that our approach is beneficial for achieving improved performance coupled with faithful model reasoning for lung cancer prediction. Extensive cross-evaluation results further illustrate the effect of unsure data for deep-learning-based methods in lung nodule classification.
Egocentric Human Trajectory Forecasting with a Wearable Camera and Multi-Modal Fusion
Nov 04, 2021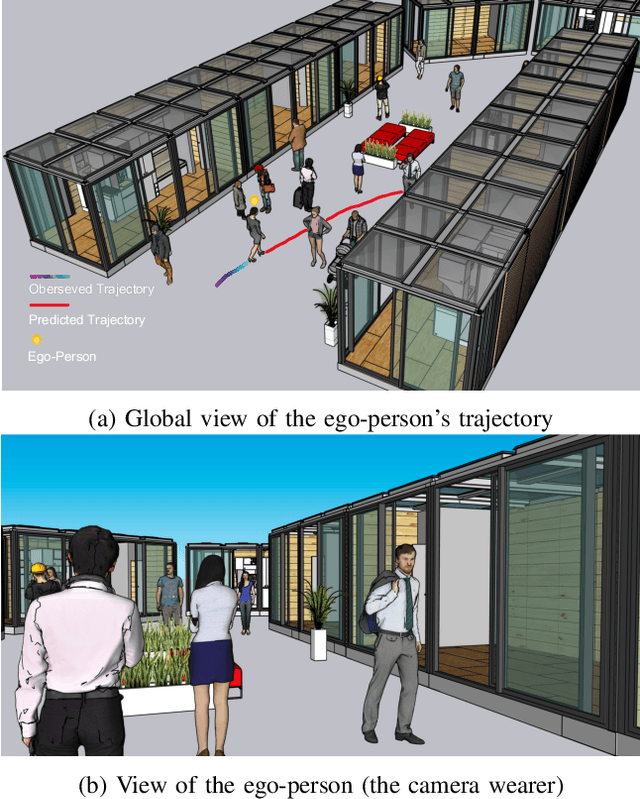

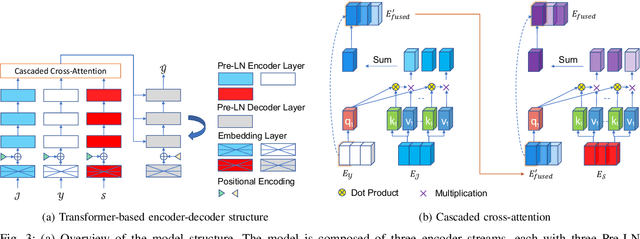

In this paper, we address the problem of forecasting the trajectory of an egocentric camera wearer (ego-person) in crowded spaces. The trajectory forecasting ability learned from the data of different camera wearers walking around in the real world can be transferred to assist visually impaired people in navigation, as well as to instill human navigation behaviours in mobile robots, enabling better human-robot interactions. To this end, a novel egocentric human trajectory forecasting dataset was constructed, containing real trajectories of people navigating in crowded spaces wearing a camera, as well as extracted rich contextual data. We extract and utilize three different modalities to forecast the trajectory of the camera wearer, i.e., his/her past trajectory, the past trajectories of nearby people, and the environment such as the scene semantics or the depth of the scene. A Transformer-based encoder-decoder neural network model, integrated with a novel cascaded cross-attention mechanism that fuses multiple modalities, has been designed to predict the future trajectory of the camera wearer. Extensive experiments have been conducted, and the results have shown that our model outperforms the state-of-the-art methods in egocentric human trajectory forecasting.
Occlusion-Invariant Rotation-Equivariant Semi-Supervised Depth Based Cross-View Gait Pose Estimation
Sep 03, 2021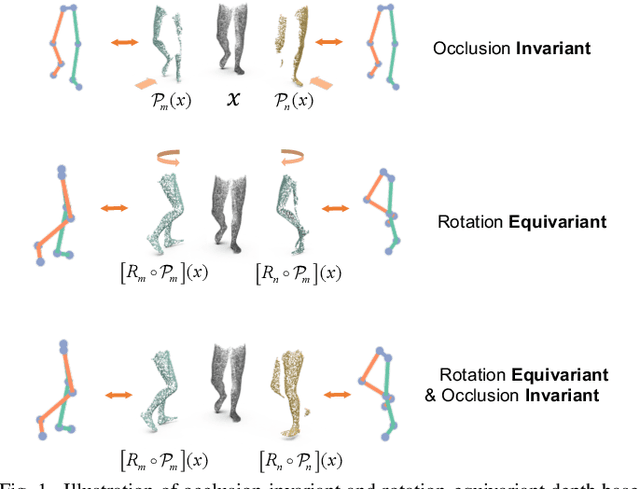
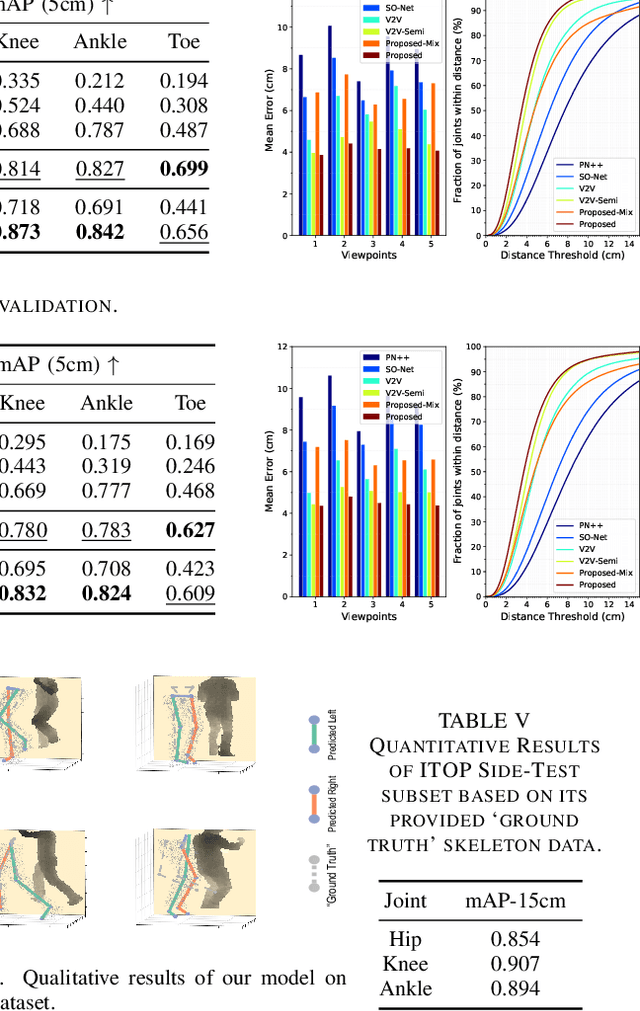
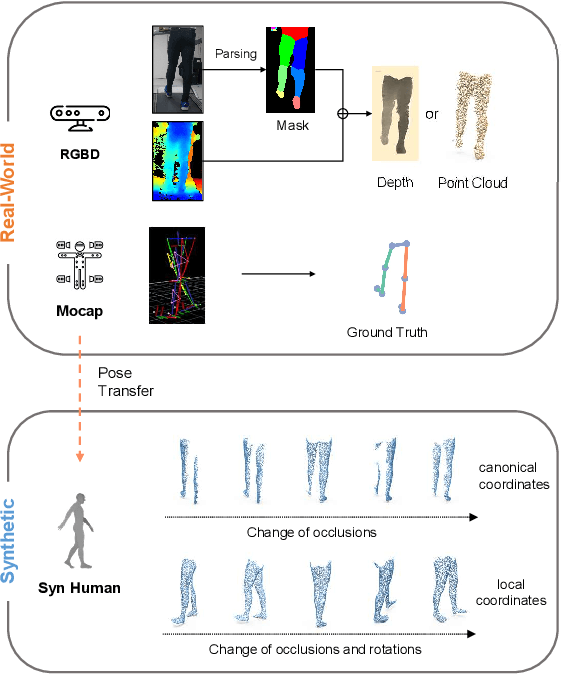
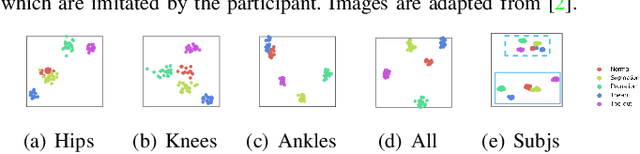
Accurate estimation of three-dimensional human skeletons from depth images can provide important metrics for healthcare applications, especially for biomechanical gait analysis. However, there exist inherent problems associated with depth images captured from a single view. The collected data is greatly affected by occlusions where only partial surface data can be recorded. Furthermore, depth images of human body exhibit heterogeneous characteristics with viewpoint changes, and the estimated poses under local coordinate systems are expected to go through equivariant rotations. Most existing pose estimation models are sensitive to both issues. To address this, we propose a novel approach for cross-view generalization with an occlusion-invariant semi-supervised learning framework built upon a novel rotation-equivariant backbone. Our model was trained with real-world data from a single view and unlabelled synthetic data from multiple views. It can generalize well on the real-world data from all the other unseen views. Our approach has shown superior performance on gait analysis on our ICL-Gait dataset compared to other state-of-the-arts and it can produce more convincing keypoints on ITOP dataset, than its provided "ground truth".
TransAction: ICL-SJTU Submission to EPIC-Kitchens Action Anticipation Challenge 2021
Jul 28, 2021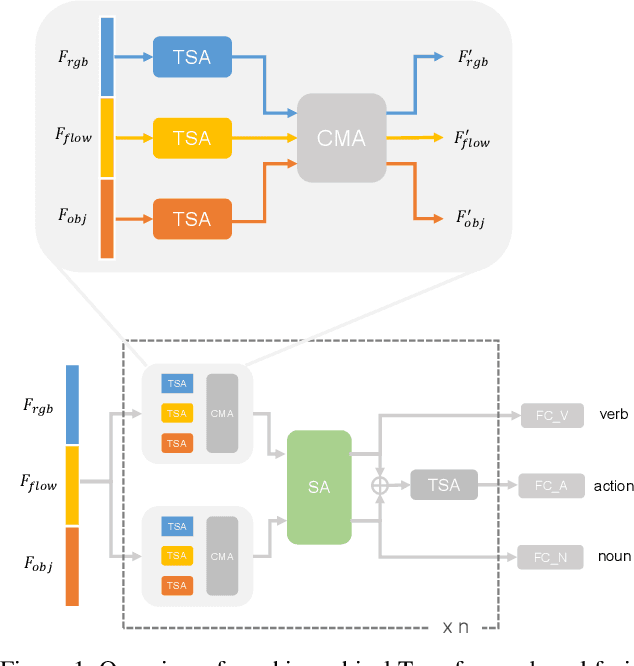
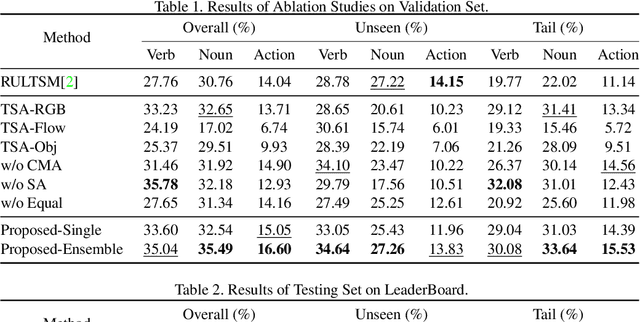
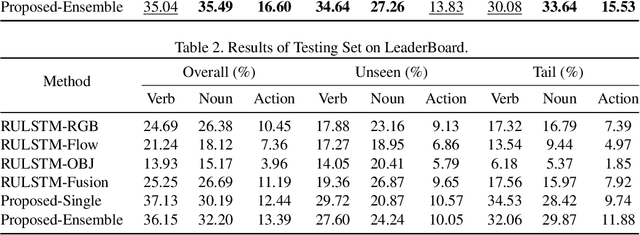
In this report, the technical details of our submission to the EPIC-Kitchens Action Anticipation Challenge 2021 are given. We developed a hierarchical attention model for action anticipation, which leverages Transformer-based attention mechanism to aggregate features across temporal dimension, modalities, symbiotic branches respectively. In terms of Mean Top-5 Recall of action, our submission with team name ICL-SJTU achieved 13.39% for overall testing set, 10.05% for unseen subsets and 11.88% for tailed subsets. Additionally, it is noteworthy that our submission ranked 1st in terms of verb class in all three (sub)sets.
Egocentric Image Captioning for Privacy-Preserved Passive Dietary Intake Monitoring
Jul 01, 2021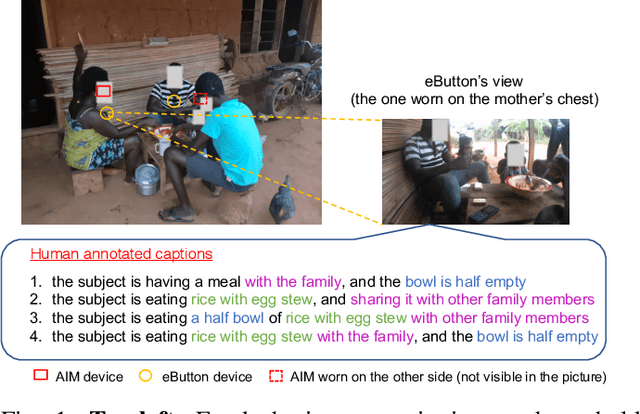
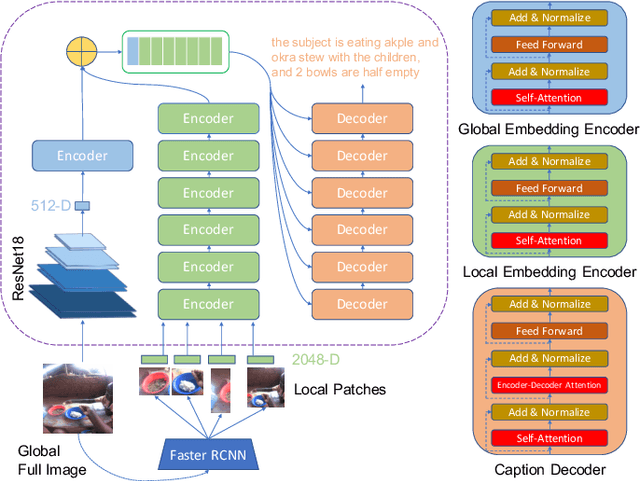
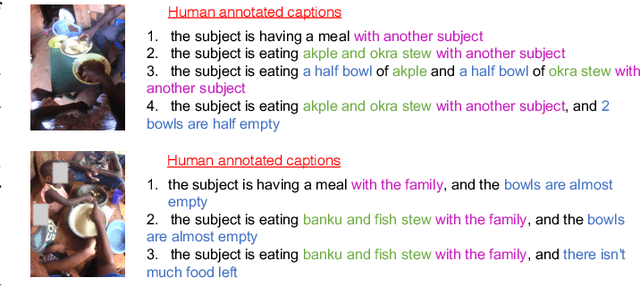
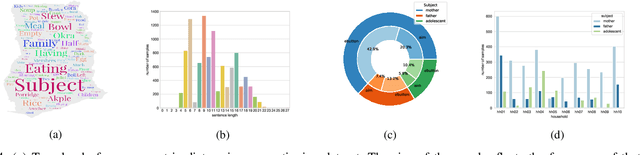
Camera-based passive dietary intake monitoring is able to continuously capture the eating episodes of a subject, recording rich visual information, such as the type and volume of food being consumed, as well as the eating behaviours of the subject. However, there currently is no method that is able to incorporate these visual clues and provide a comprehensive context of dietary intake from passive recording (e.g., is the subject sharing food with others, what food the subject is eating, and how much food is left in the bowl). On the other hand, privacy is a major concern while egocentric wearable cameras are used for capturing. In this paper, we propose a privacy-preserved secure solution (i.e., egocentric image captioning) for dietary assessment with passive monitoring, which unifies food recognition, volume estimation, and scene understanding. By converting images into rich text descriptions, nutritionists can assess individual dietary intake based on the captions instead of the original images, reducing the risk of privacy leakage from images. To this end, an egocentric dietary image captioning dataset has been built, which consists of in-the-wild images captured by head-worn and chest-worn cameras in field studies in Ghana. A novel transformer-based architecture is designed to caption egocentric dietary images. Comprehensive experiments have been conducted to evaluate the effectiveness and to justify the design of the proposed architecture for egocentric dietary image captioning. To the best of our knowledge, this is the first work that applies image captioning to dietary intake assessment in real life settings.
Region-aware Adaptive Instance Normalization for Image Harmonization
Jun 05, 2021
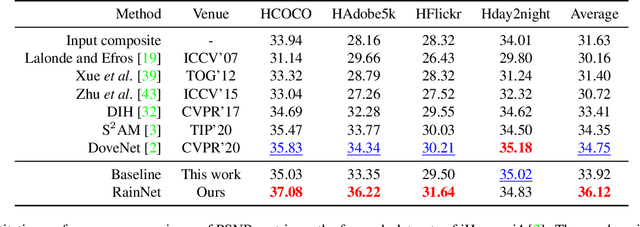
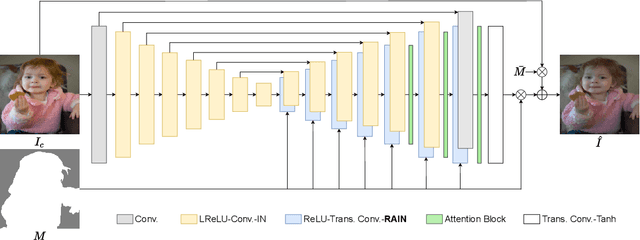
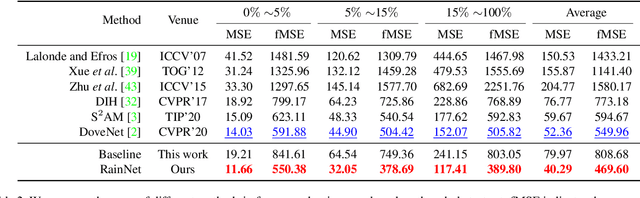
Image composition plays a common but important role in photo editing. To acquire photo-realistic composite images, one must adjust the appearance and visual style of the foreground to be compatible with the background. Existing deep learning methods for harmonizing composite images directly learn an image mapping network from the composite to the real one, without explicit exploration on visual style consistency between the background and the foreground images. To ensure the visual style consistency between the foreground and the background, in this paper, we treat image harmonization as a style transfer problem. In particular, we propose a simple yet effective Region-aware Adaptive Instance Normalization (RAIN) module, which explicitly formulates the visual style from the background and adaptively applies them to the foreground. With our settings, our RAIN module can be used as a drop-in module for existing image harmonization networks and is able to bring significant improvements. Extensive experiments on the existing image harmonization benchmark datasets show the superior capability of the proposed method. Code is available at {https://github.com/junleen/RainNet}.
Indoor Future Person Localization from an Egocentric Wearable Camera
Mar 06, 2021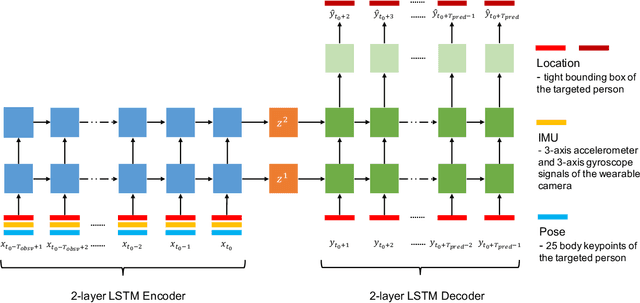

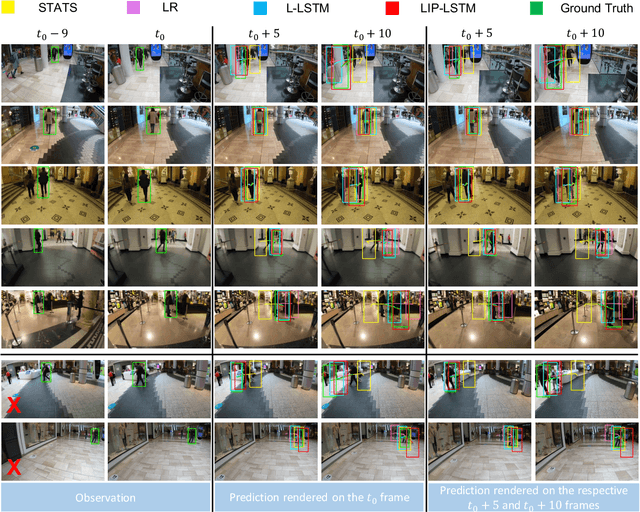

Accurate prediction of future person location and movement trajectory from an egocentric wearable camera can benefit a wide range of applications, such as assisting visually impaired people in navigation, and the development of mobility assistance for people with disability. In this work, a new egocentric dataset was constructed using a wearable camera, with 8,250 short clips of a targeted person either walking 1) toward, 2) away, or 3) across the camera wearer in indoor environments, or 4) staying still in the scene, and 13,817 person bounding boxes were manually labelled. Apart from the bounding boxes, the dataset also contains the estimated pose of the targeted person as well as the IMU signal of the wearable camera at each time point. An LSTM-based encoder-decoder framework was designed to predict the future location and movement trajectory of the targeted person in this egocentric setting. Extensive experiments have been conducted on the new dataset, and have shown that the proposed method is able to reliably and better predict future person location and trajectory in egocentric videos captured by the wearable camera compared to three baselines.
Toward Fine-grained Facial Expression Manipulation
Apr 07, 2020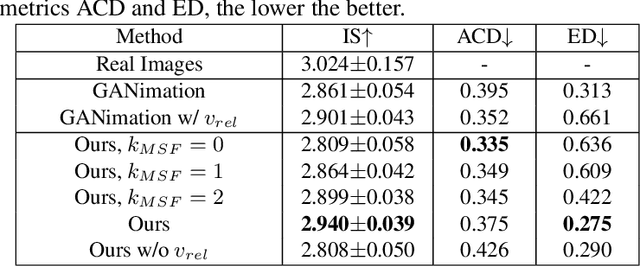
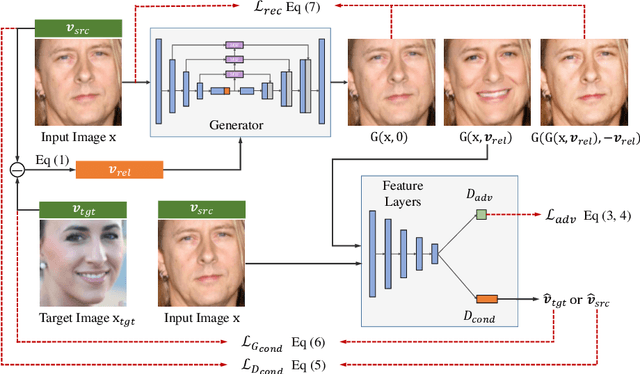
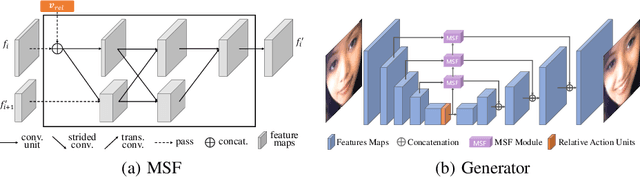

Facial expression manipulation, as an image-to-image translation problem, aims at editing facial expression with a given condition. Previous methods edit an input image under the guidance of a discrete emotion label or absolute condition (e.g., facial action units) to possess the desired expression. However, these methods either suffer from changing condition-irrelevant regions or are inefficient to preserve image quality. In this study, we take these two objectives into consideration and propose a novel conditional GAN model. First, we replace continuous absolute condition with relative condition, specifically, relative action units. With relative action units, the generator learns to only transform regions of interest which are specified by non-zero-valued relative AUs, avoiding estimating the current AUs of input image. Second, our generator is built on U-Net architecture and strengthened by multi-scale feature fusion (MSF) mechanism for high-quality expression editing purpose. Extensive experiments on both quantitative and qualitative evaluation demonstrate the improvements of our proposed approach compared with the state-of-the-art expression editing methods.