 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Spectroscope: Improve Interpretability and Controllability through Fourier Analysis
Aug 12, 2022



Universal style transfer (UST) infuses styles from arbitrary reference images into content images. Existing methods, while enjoying many practical successes, are unable of explaining experimental observations, including different performances of UST algorithms in preserving the spatial structure of content images. In addition, methods are limited to cumbersome global controls on stylization, so that they require additional spatial masks for desired stylization. In this work, we provide a systematic Fourier analysis on a general framework for UST. We present an equivalent form of the framework in the frequency domain. The form implies that existing algorithms treat all frequency components and pixels of feature maps equally, except for the zero-frequency component. We connect Fourier amplitude and phase with Gram matrices and a content reconstruction loss in style transfer, respectively. Based on such equivalence and connections, we can thus interpret different structure preservation behaviors between algorithms with Fourier phase. Given the interpretations we have, we propose two manipulations in practice for structure preservation and desired stylization. Both qualitative and quantitative experiments demonstrate the competitive performance of our method against the state-of-the-art methods. We also conduct experiments to demonstrate (1) the abovementioned equivalence, (2) the interpretability based on Fourier amplitude and phase and (3) the controllability associated with frequency components.
RCLane: Relay Chain Prediction for Lane Detection
Jul 19, 2022
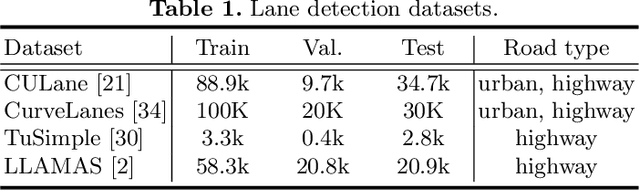
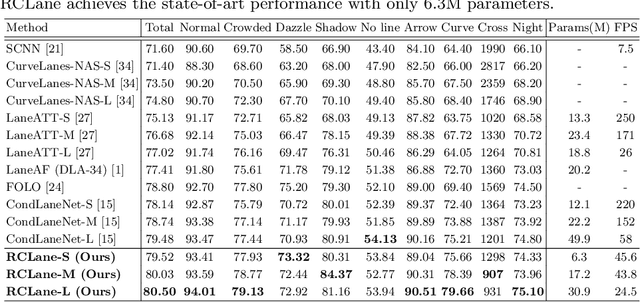
Lane detection is an important component of many real-world autonomous systems. Despite a wide variety of lane detection approaches have been proposed, reporting steady benchmark improvements over time, lane detection remains a largely unsolved problem. This is because most of the existing lane detection methods either treat the lane detection as a dense prediction or a detection task, few of them consider the unique topologies (Y-shape, Fork-shape, nearly horizontal lane) of the lane markers, which leads to sub-optimal solution. In this paper, we present a new method for lane detection based on relay chain prediction. Specifically, our model predicts a segmentation map to classify the foreground and background region. For each pixel point in the foreground region, we go through the forward branch and backward branch to recover the whole lane. Each branch decodes a transfer map and a distance map to produce the direction moving to the next point, and how many steps to progressively predict a relay station (next point). As such, our model is able to capture the keypoints along the lanes. Despite its simplicity, our strategy allows us to establish new state-of-the-art on four major benchmarks including TuSimple, CULane, CurveLanes and LLAMAS.
Cross-domain Federated Object Detection
Jun 30, 2022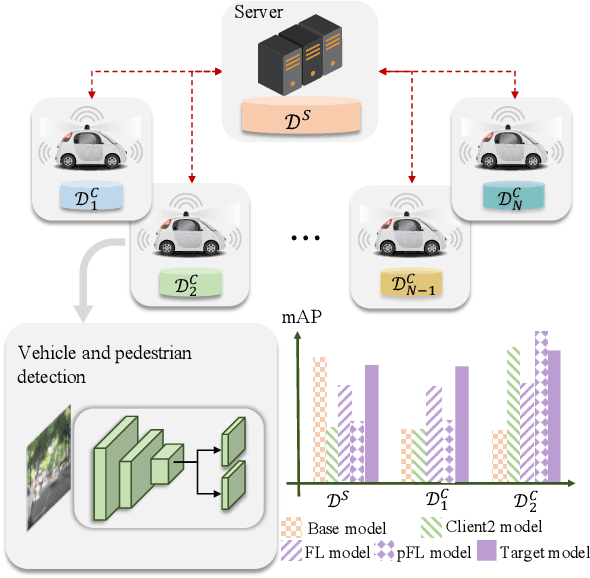
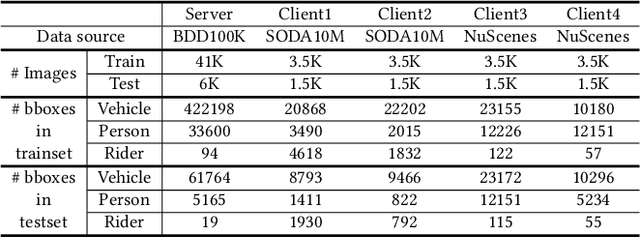
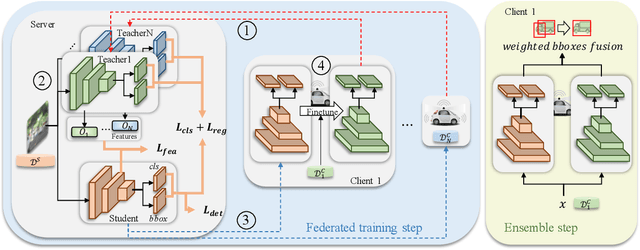
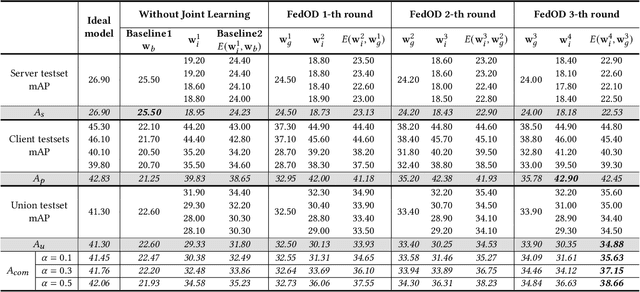
Detection models trained by one party (server) may face severe performance degradation when distributed to other users (clients). For example, in autonomous driving scenarios, different driving environments may bring obvious domain shifts, which lead to biases in model predictions. Federated learning that has emerged in recent years can enable multi-party collaborative training without leaking client data. In this paper, we focus on a special cross-domain scenario where the server contains large-scale data and multiple clients only contain a small amount of data; meanwhile, there exist differences in data distributions among the clients. In this case, traditional federated learning techniques cannot take into account the learning of both the global knowledge of all participants and the personalized knowledge of a specific client. To make up for this limitation, we propose a cross-domain federated object detection framework, named FedOD. In order to learn both the global knowledge and the personalized knowledge in different domains, the proposed framework first performs the federated training to obtain a public global aggregated model through multi-teacher distillation, and sends the aggregated model back to each client for finetuning its personalized local model. After very few rounds of communication, on each client we can perform weighted ensemble inference on the public global model and the personalized local model. With the ensemble, the generalization performance of the client-side model can outperform a single model with the same parameter scale. We establish a federated object detection dataset which has significant background differences and instance differences based on multiple public autonomous driving datasets, and then conduct extensive experiments on the dataset. The experimental results validate the effectiveness of the proposed method.
Local Slot Attention for Vision-and-Language Navigation
Jun 22, 2022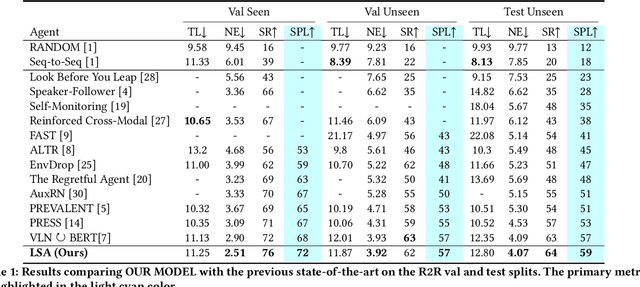
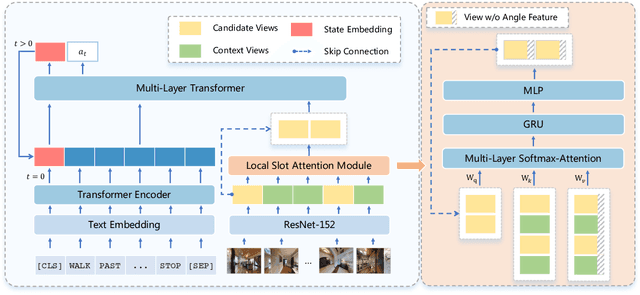
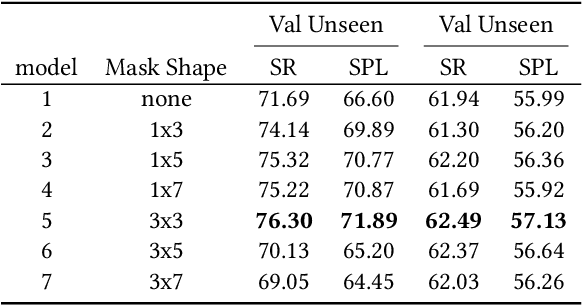

Vision-and-language navigation (VLN), a frontier study aiming to pave the way for general-purpose robots, has been a hot topic in the computer vision and natural language processing community. The VLN task requires an agent to navigate to a goal location following natural language instructions in unfamiliar environments. Recently, transformer-based models have gained significant improvements on the VLN task. Since the attention mechanism in the transformer architecture can better integrate inter- and intra-modal information of vision and language. However, there exist two problems in current transformer-based models. 1) The models process each view independently without taking the integrity of the objects into account. 2) During the self-attention operation in the visual modality, the views that are spatially distant can be inter-weaved with each other without explicit restriction. This kind of mixing may introduce extra noise instead of useful information. To address these issues, we propose 1) A slot-attention based module to incorporate information from segmentation of the same object. 2) A local attention mask mechanism to limit the visual attention span. The proposed modules can be easily plugged into any VLN architecture and we use the Recurrent VLN-Bert as our base model. Experiments on the R2R dataset show that our model has achieved the state-of-the-art results.
Learning 6-DoF Object Poses to Grasp Category-level Objects by Language Instructions
May 09, 2022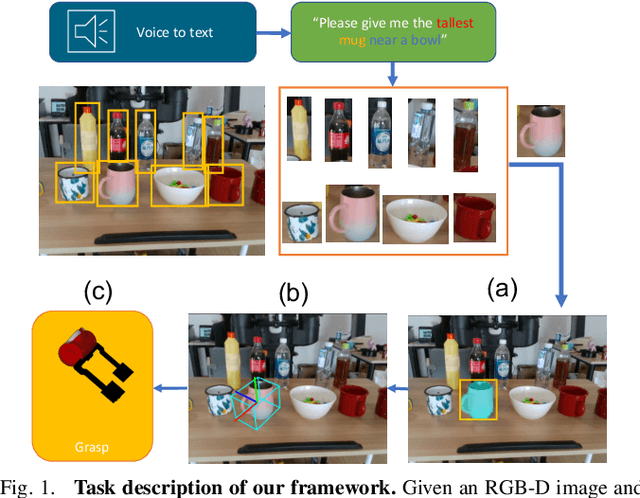

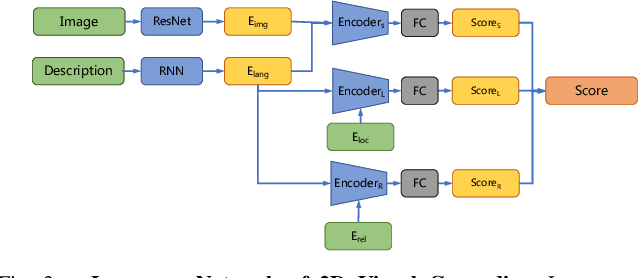

This paper studies the task of any objects grasping from the known categories by free-form language instructions. This task demands the technique in computer vision, natural language processing, and robotics. We bring these disciplines together on this open challenge, which is essential to human-robot interaction. Critically, the key challenge lies in inferring the category of objects from linguistic instructions and accurately estimating the 6-DoF information of unseen objects from the known classes. In contrast, previous works focus on inferring the pose of object candidates at the instance level. This significantly limits its applications in real-world scenarios.In this paper, we propose a language-guided 6-DoF category-level object localization model to achieve robotic grasping by comprehending human intention. To this end, we propose a novel two-stage method. Particularly, the first stage grounds the target in the RGB image through language description of names, attributes, and spatial relations of objects. The second stage extracts and segments point clouds from the cropped depth image and estimates the full 6-DoF object pose at category-level. Under such a manner, our approach can locate the specific object by following human instructions, and estimate the full 6-DoF pose of a category-known but unseen instance which is not utilized for training the model. Extensive experimental results show that our method is competitive with the state-of-the-art language-conditioned grasp method. Importantly, we deploy our approach on a physical robot to validate the usability of our framework in real-world applications. Please refer to the supplementary for the demo videos of our robot experiments.
I Know What You Draw: Learning Grasp Detection Conditioned on a Few Freehand Sketches
May 09, 2022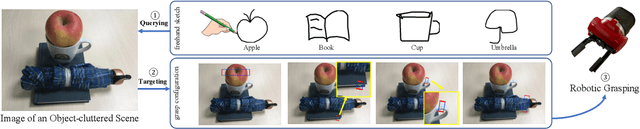
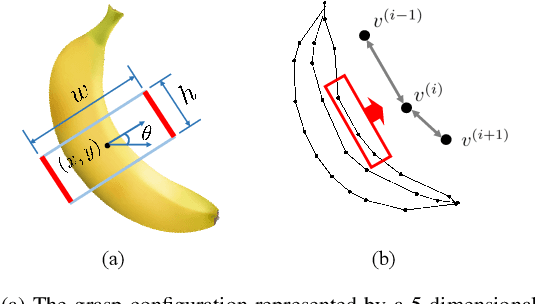
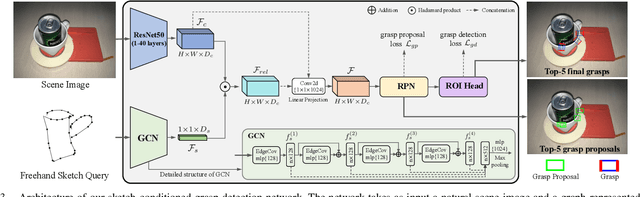

In this paper, we are interested in the problem of generating target grasps by understanding freehand sketches. The sketch is useful for the persons who cannot formulate language and the cases where a textual description is not available on the fly. However, very few works are aware of the usability of this novel interactive way between humans and robots. To this end, we propose a method to generate a potential grasp configuration relevant to the sketch-depicted objects. Due to the inherent ambiguity of sketches with abstract details, we take the advantage of the graph by incorporating the structure of the sketch to enhance the representation ability. This graph-represented sketch is further validated to improve the generalization of the network, capable of learning the sketch-queried grasp detection by using a small collection (around 100 samples) of hand-drawn sketches. Additionally, our model is trained and tested in an end-to-end manner which is easy to be implemented in real-world applications. Experiments on the multi-object VMRD and GraspNet-1Billion datasets demonstrate the good generalization of the proposed method. The physical robot experiments confirm the utility of our method in object-cluttered scenes.
Density-preserving Deep Point Cloud Compression
Apr 27, 2022
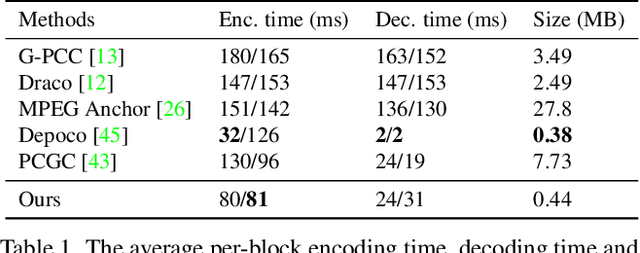

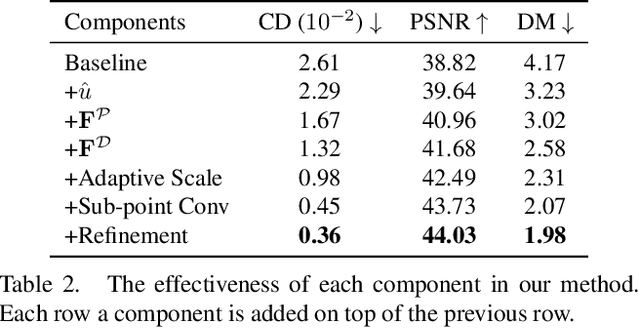
Local density of point clouds is crucial for representing local details, but has been overlooked by existing point cloud compression methods. To address this, we propose a novel deep point cloud compression method that preserves local density information. Our method works in an auto-encoder fashion: the encoder downsamples the points and learns point-wise features, while the decoder upsamples the points using these features. Specifically, we propose to encode local geometry and density with three embeddings: density embedding, local position embedding and ancestor embedding. During the decoding, we explicitly predict the upsampling factor for each point, and the directions and scales of the upsampled points. To mitigate the clustered points issue in existing methods, we design a novel sub-point convolution layer, and an upsampling block with adaptive scale. Furthermore, our method can also compress point-wise attributes, such as normal. Extensive qualitative and quantitative results on SemanticKITTI and ShapeNet demonstrate that our method achieves the state-of-the-art rate-distortion trade-off.
One-shot Federated Learning without Server-side Training
Apr 26, 2022
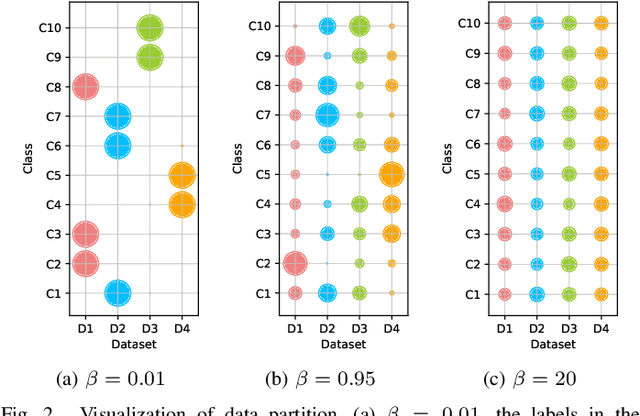
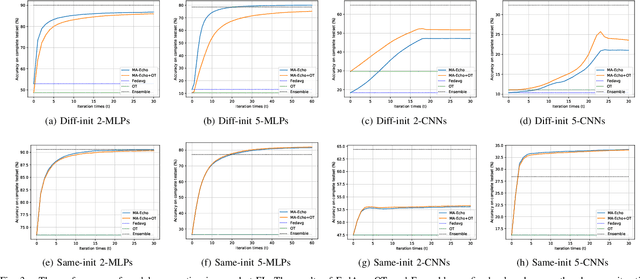
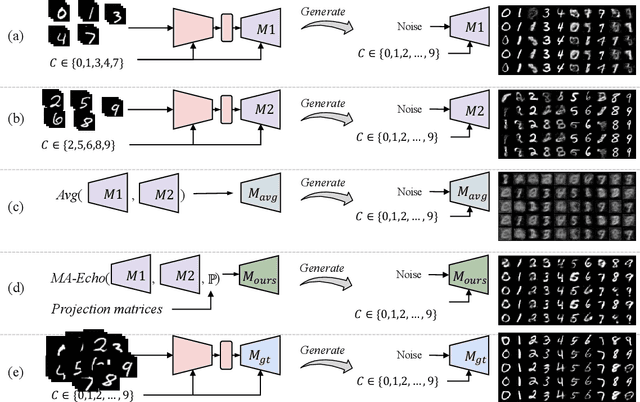
Federated Learning (FL) has recently made significant progress as a new machine learning paradigm for privacy protection. Due to the high communication cost of traditional FL, one-shot federated learning is gaining popularity as a way to reduce communication cost between clients and the server. Most of the existing one-shot FL methods are based on Knowledge Distillation; however, distillation based approach requires an extra training phase and depends on publicly available data sets. In this work, we consider a novel and challenging setting: performing a single round of parameter aggregation on the local models without server-side training on a public data set. In this new setting, we propose an effective algorithm for Model Aggregation via Exploring Common Harmonized Optima (MA-Echo), which iteratively updates the parameters of all local models to bring them close to a common low-loss area on the loss surface, without harming performance on their own data sets at the same time. Compared to the existing methods, MA-Echo can work well even in extremely non-identical data distribution settings where the support categories of each local model have no overlapped labels with those of the others. We conduct extensive experiments on two popular image classification data sets to compare the proposed method with existing methods and demonstrate the effectiveness of MA-Echo, which clearly outperforms the state-of-the-arts.
Pixel2Mesh++: 3D Mesh Generation and Refinement from Multi-View Images
Apr 21, 2022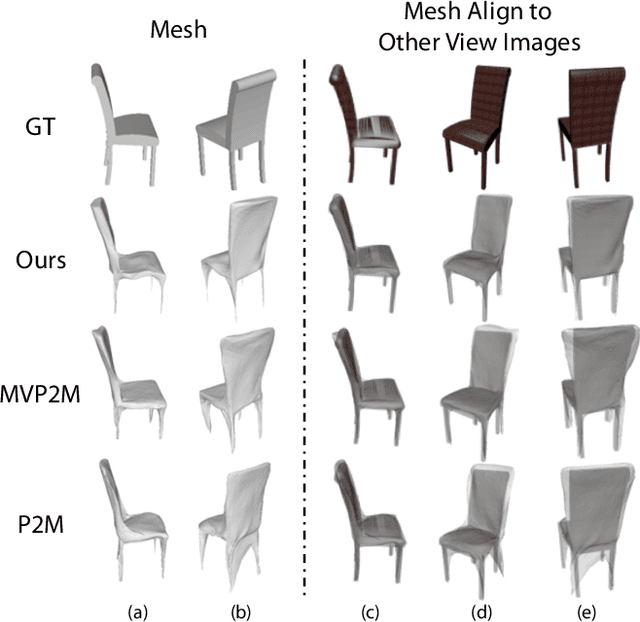
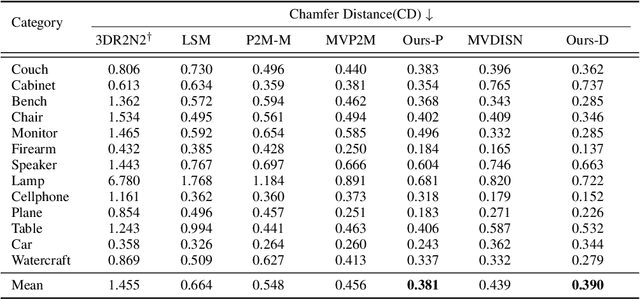
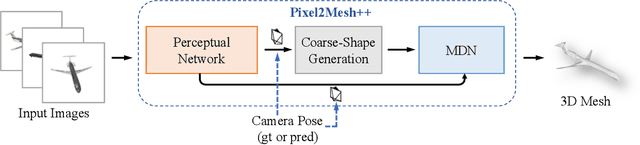
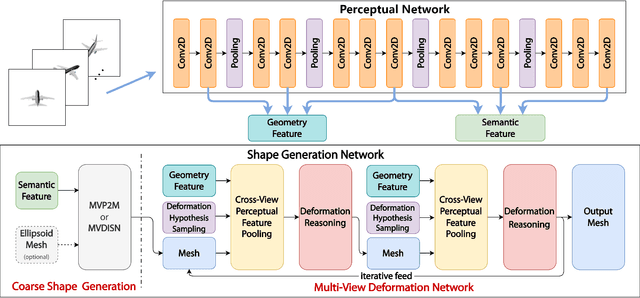
We study the problem of shape generation in 3D mesh representation from a small number of color images with or without camera poses. While many previous works learn to hallucinate the shape directly from priors, we adopt to further improve the shape quality by leveraging cross-view information with a graph convolution network. Instead of building a direct mapping function from images to 3D shape, our model learns to predict series of deformations to improve a coarse shape iteratively. Inspired by traditional multiple view geometry methods, our network samples nearby area around the initial mesh's vertex locations and reasons an optimal deformation using perceptual feature statistics built from multiple input images. Extensive experiments show that our model produces accurate 3D shapes that are not only visually plausible from the input perspectives, but also well aligned to arbitrary viewpoints. With the help of physically driven architecture, our model also exhibits generalization capability across different semantic categories, and the number of input images. Model analysis experiments show that our model is robust to the quality of the initial mesh and the error of camera pose, and can be combined with a differentiable renderer for test-time optimization.
DST: Dynamic Substitute Training for Data-free Black-box Attack
Apr 03, 2022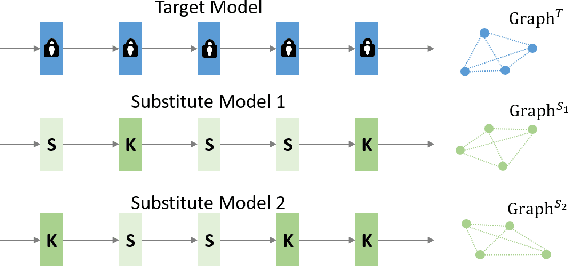
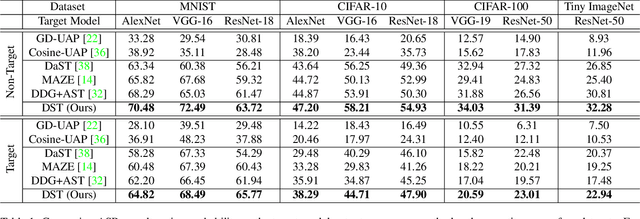
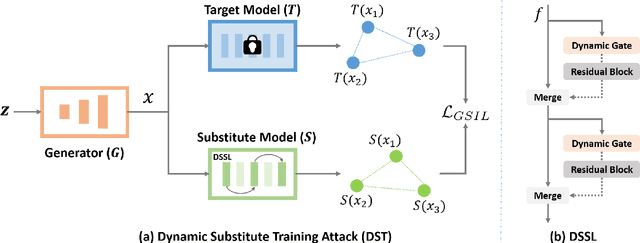
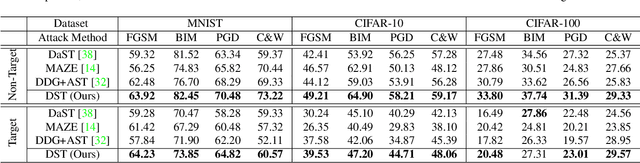
With the wide applications of deep neural network models in various computer vision tasks, more and more works study the model vulnerability to adversarial examples. For data-free black box attack scenario, existing methods are inspired by the knowledge distillation, and thus usually train a substitute model to learn knowledge from the target model using generated data as input. However, the substitute model always has a static network structure, which limits the attack ability for various target models and tasks. In this paper, we propose a novel dynamic substitute training attack method to encourage substitute model to learn better and faster from the target model. Specifically, a dynamic substitute structure learning strategy is proposed to adaptively generate optimal substitute model structure via a dynamic gate according to different target models and tasks. Moreover, we introduce a task-driven graph-based structure information learning constrain to improve the quality of generated training data, and facilitate the substitute model learning structural relationships from the target model multiple outputs. Extensive experiments have been conducted to verify the efficacy of the proposed attack method, which can achieve better performance compared with the state-of-the-art competitors on several datasets.