 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Guided Modular Routing Networks for Visual Question Answering
Paper and Code
Apr 17, 2019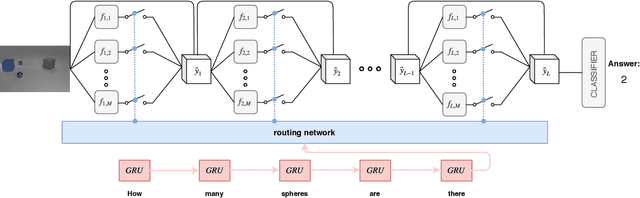
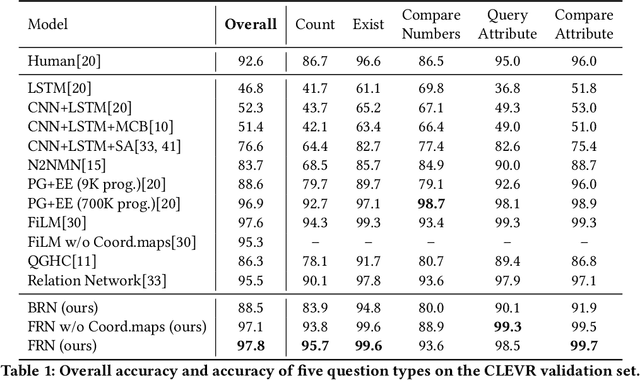
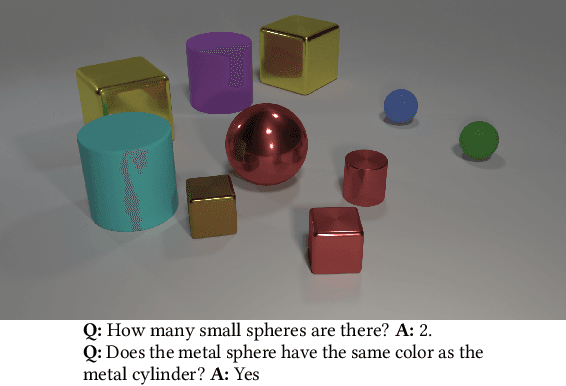

Visual Question Answering (VQA) faces two major challenges: how to better fuse the visual and textual modalities and how to make the VQA model have the reasoning ability to answer more complex questions. In this paper, we address both challenges by proposing the novel Question Guided Modular Routing Networks (QGMRN). QGMRN can fuse the visual and textual modalities in multiple semantic levels which makes the fusion occur in a fine-grained way, it also can learn to reason by routing between the generic modules without additional supervision information or prior knowledge. The proposed QGMRN consists of three sub-networks: visual network, textual network and routing network. The routing network selectively executes each module in the visual network according to the pathway activated by the question features generated by the textual network. Experiments on the CLEVR dataset show that our model can outperform the state-of-the-art. Models and Codes will be released.