 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Dataset Distillation via Model Augmentation
Dec 12, 2022



Dataset Distillation (DD), a newly emerging field, aims at generating much smaller and high-quality synthetic datasets from large ones. Existing DD methods based on gradient matching achieve leading performance; however, they are extremely computationally intensive as they require continuously optimizing a dataset among thousands of randomly initialized models. In this paper, we assume that training the synthetic data with diverse models leads to better generalization performance. Thus we propose two \textbf{model augmentation} techniques, ~\ie using \textbf{early-stage models} and \textbf{weight perturbation} to learn an informative synthetic set with significantly reduced training cost. Extensive experiments demonstrate that our method achieves up to 20$\times$ speedup and comparable performance on par with state-of-the-art baseline methods.
Are All Spurious Features in Natural Language Alike? An Analysis through a Causal Lens
Oct 25, 2022



The term `spurious correlations' has been used in NLP to informally denote any undesirable feature-label correlations. However, a correlation can be undesirable because (i) the feature is irrelevant to the label (e.g. punctuation in a review), or (ii) the feature's effect on the label depends on the context (e.g. negation words in a review), which is ubiquitous in language tasks. In case (i), we want the model to be invariant to the feature, which is neither necessary nor sufficient for prediction. But in case (ii), even an ideal model (e.g. humans) must rely on the feature, since it is necessary (but not sufficient) for prediction. Therefore, a more fine-grained treatment of spurious features is needed to specify the desired model behavior. We formalize this distinction using a causal model and probabilities of necessity and sufficiency, which delineates the causal relations between a feature and a label. We then show that this distinction helps explain results of existing debiasing methods on different spurious features, and demystifies surprising results such as the encoding of spurious features in model representations after debiasing.
Task Transfer and Domain Adaptation for Zero-Shot Question Answering
Jun 14, 2022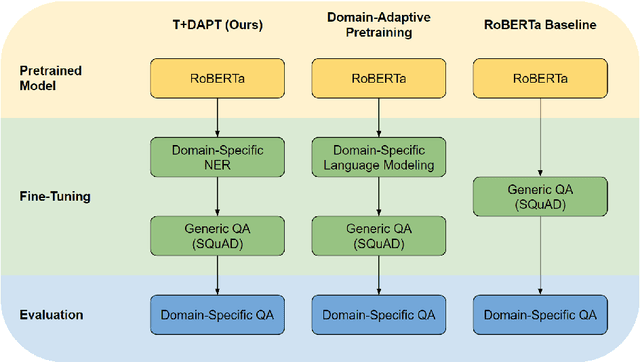

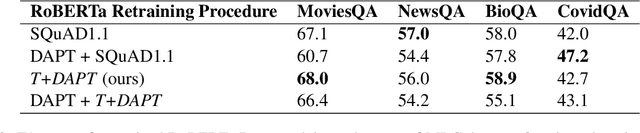

Pretrained language models have shown success in various areas of natural language processing, including reading comprehension tasks. However, when applying machine learning methods to new domains, labeled data may not always be available. To address this, we use supervised pretraining on source-domain data to reduce sample complexity on domain-specific downstream tasks. We evaluate zero-shot performance on domain-specific reading comprehension tasks by combining task transfer with domain adaptation to fine-tune a pretrained model with no labelled data from the target task. Our approach outperforms Domain-Adaptive Pretraining on downstream domain-specific reading comprehension tasks in 3 out of 4 domains.
DeepOPF-AL: Augmented Learning for Solving AC-OPF Problems with Multiple Load-Solution Mappings
Jun 07, 2022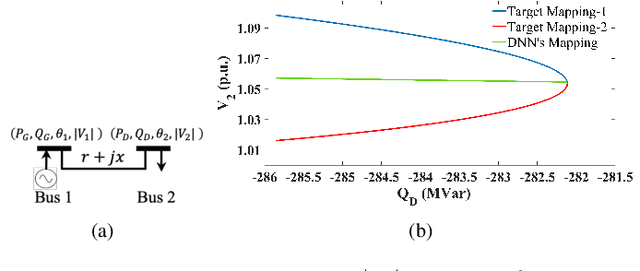
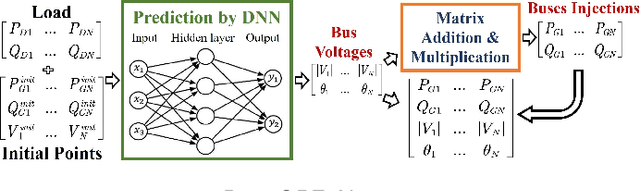
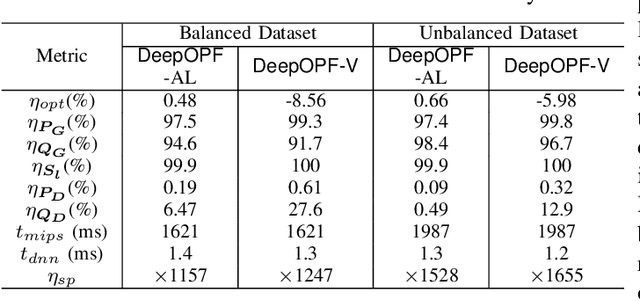
The existence of multiple load-solution mappings of non-convex AC-OPF problems poses a fundamental challenge to deep neural network (DNN) schemes. As the training dataset may contain a mixture of data points corresponding to different load-solution mappings, the DNN can fail to learn a legitimate mapping and generate inferior solutions. We propose DeepOPF-AL as an augmented-learning approach to tackle this issue. The idea is to train a DNN to learn a unique mapping from an augmented input, i.e., (load, initial point), to the solution generated by an iterative OPF solver with the load and initial point as intake. We then apply the learned augmented mapping to solve AC-OPF problems much faster than conventional solvers. Simulation results over IEEE test cases show that DeepOPF-AL achieves noticeably better optimality and similar feasibility and speedup performance, as compared to a recent DNN scheme, with the same DNN size yet elevated training complexity.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Ensuring DNN Solution Feasibility for Optimization Problems with Convex Constraints and Its Application to DC Optimal Power Flow Problems
Dec 15, 2021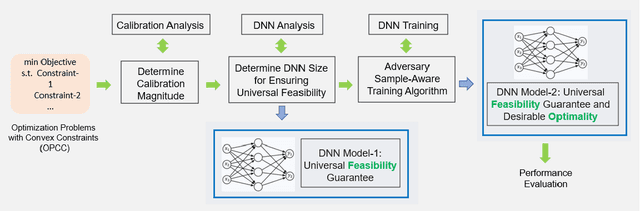
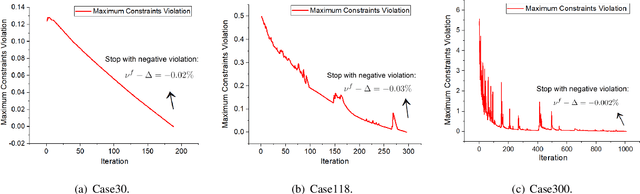
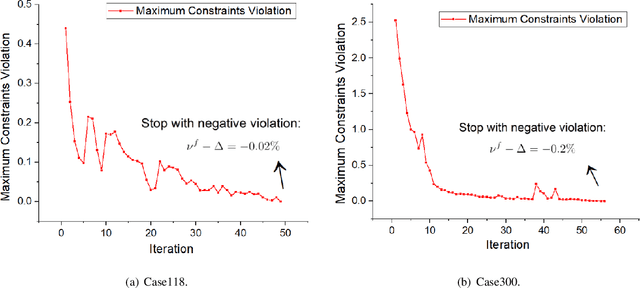
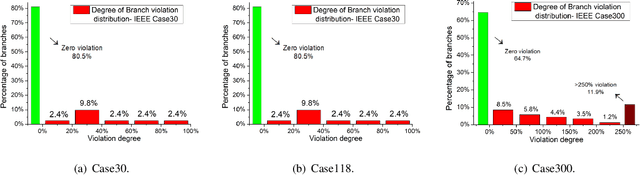
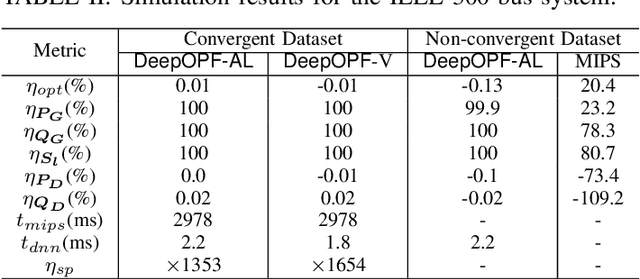
Ensuring solution feasibility is a key challenge in developing Deep Neural Network (DNN) schemes for solving constrained optimization problems, due to inherent DNN prediction errors. In this paper, we propose a "preventive learning'" framework to systematically guarantee DNN solution feasibility for problems with convex constraints and general objective functions. We first apply a predict-and-reconstruct design to not only guarantee equality constraints but also exploit them to reduce the number of variables to be predicted by DNN. Then, as a key methodological contribution, we systematically calibrate inequality constraints used in DNN training, thereby anticipating prediction errors and ensuring the resulting solutions remain feasible. We characterize the calibration magnitudes and the DNN size sufficient for ensuring universal feasibility. We propose a new Adversary-Sample Aware training algorithm to improve DNN's optimality performance without sacrificing feasibility guarantee. Overall, the framework provides two DNNs. The first one from characterizing the sufficient DNN size can guarantee universal feasibility while the other from the proposed training algorithm further improves optimality and maintains DNN's universal feasibility simultaneously. We apply the preventive learning framework to develop DeepOPF+ for solving the essential DC optimal power flow problem in grid operation. It improves over existing DNN-based schemes in ensuring feasibility and attaining consistent desirable speedup performance in both light-load and heavy-load regimes. Simulation results over IEEE Case-30/118/300 test cases show that DeepOPF+ generates $100\%$ feasible solutions with $<$0.5% optimality loss and up to two orders of magnitude computational speedup, as compared to a state-of-the-art iterative solver.
DataCLUE: A Benchmark Suite for Data-centric NLP
Nov 17, 2021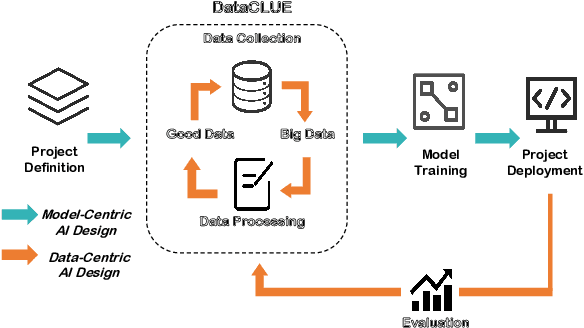

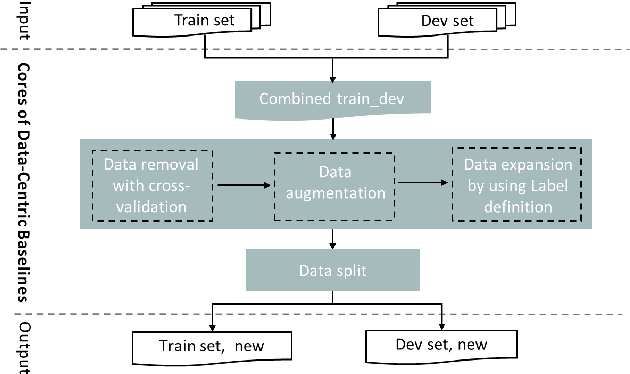
Data-centric AI has recently proven to be more effective and high-performance, while traditional model-centric AI delivers fewer and fewer benefits. It emphasizes improving the quality of datasets to achieve better model performance. This field has significant potential because of its great practicability and getting more and more attention. However, we have not seen significant research progress in this field, especially in NLP. We propose DataCLUE, which is the first Data-Centric benchmark applied in NLP field. We also provide three simple but effective baselines to foster research in this field (improve Macro-F1 up to 5.7% point). In addition, we conduct comprehensive experiments with human annotators and show the hardness of DataCLUE. We also try an advanced method: the forgetting informed bootstrapping label correction method. All the resources related to DataCLUE, including datasets, toolkit, leaderboard, and baselines, is available online at https://github.com/CLUEbenchmark/DataCLUE
Calculating Question Similarity is Enough:A New Method for KBQA Tasks
Nov 15, 2021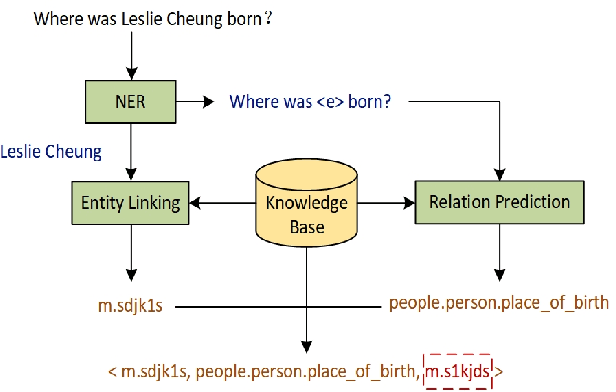
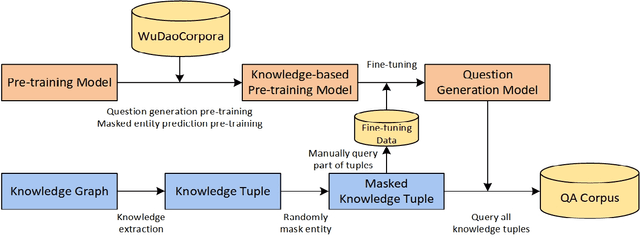

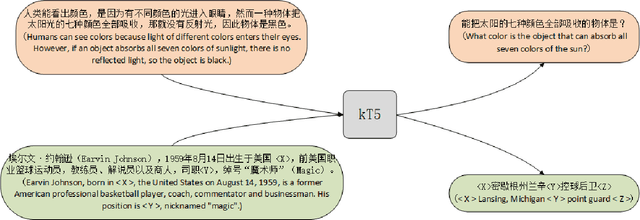
Knowledge Base Question Answering (KBQA) aims to answer natural language questions with the help of an external knowledge base. The core idea is to find the link between the internal knowledge behind questions and known triples of the knowledge base. The KBQA task pipeline contains several steps, including entity recognition, relationship extraction, and entity linking. This kind of pipeline method means that errors in any procedure will inevitably propagate to the final prediction. In order to solve the above problem, this paper proposes a Corpus Generation - Retrieve Method (CGRM) with Pre-training Language Model (PLM) and Knowledge Graph (KG). Firstly, based on the mT5 model, we designed two new pre-training tasks: knowledge masked language modeling and question generation based on the paragraph to obtain the knowledge enhanced T5 (kT5) model. Secondly, after preprocessing triples of knowledge graph with a series of heuristic rules, the kT5 model generates natural language QA pairs based on processed triples. Finally, we directly solve the QA by retrieving the synthetic dataset. We test our method on NLPCC-ICCPOL 2016 KBQA dataset, and the results show that our framework improves the performance of KBQA and the out straight-forward method is competitive with the state-of-the-art.
FewCLUE: A Chinese Few-shot Learning Evaluation Benchmark
Jul 15, 2021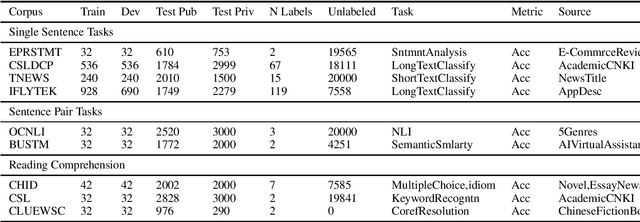
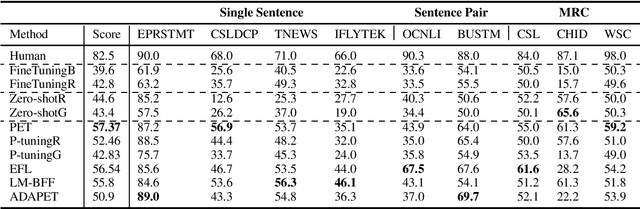

Pretrained Language Models (PLMs) have achieved tremendous success in natural language understanding tasks. While different learning schemes -- fine-tuning, zero-shot and few-shot learning -- have been widely explored and compared for languages such as English, there is comparatively little work in Chinese to fairly and comprehensively evaluate and compare these methods. This work first introduces Chinese Few-shot Learning Evaluation Benchmark (FewCLUE), the first comprehensive small sample evaluation benchmark in Chinese. It includes nine tasks, ranging from single-sentence and sentence-pair classification tasks to machine reading comprehension tasks. Given the high variance of the few-shot learning performance, we provide multiple training/validation sets to facilitate a more accurate and stable evaluation of few-shot modeling. An unlabeled training set with up to 20,000 additional samples per task is provided, allowing researchers to explore better ways of using unlabeled samples. Next, we implement a set of state-of-the-art (SOTA) few-shot learning methods (including PET, ADAPET, LM-BFF, P-tuning and EFL), and compare their performance with fine-tuning and zero-shot learning schemes on the newly constructed FewCLUE benchmark.Our results show that: 1) all five few-shot learning methods exhibit better performance than fine-tuning or zero-shot learning; 2) among the five methods, PET is the best performing few-shot method; 3) few-shot learning performance is highly dependent on the specific task. Our benchmark and code are available at https://github.com/CLUEbenchmark/FewCLUE
DeepOPF-V: Solving AC-OPF Problems Efficiently
Mar 22, 2021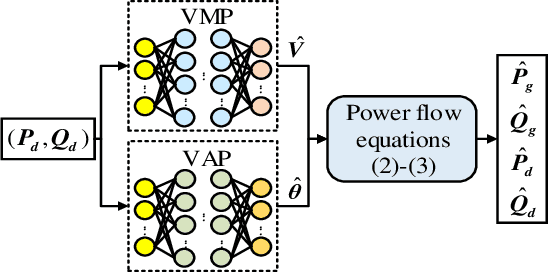
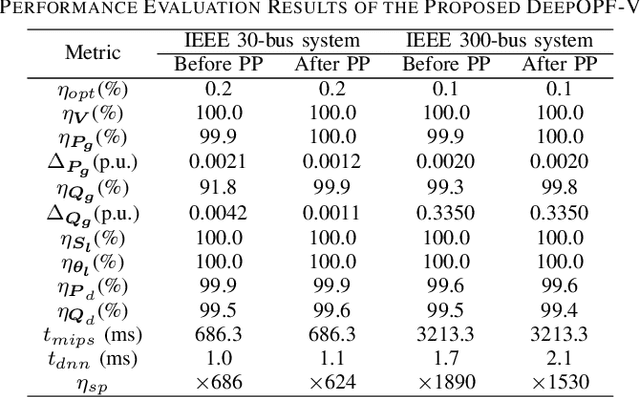
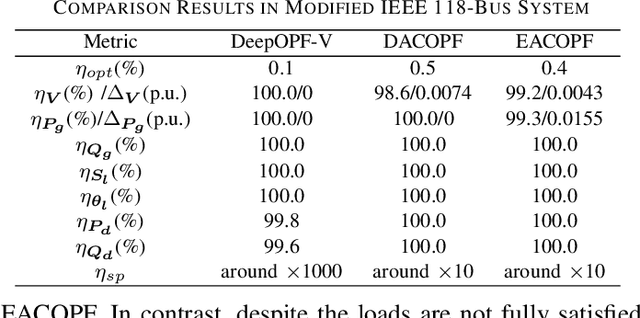
AC optimal power flow (AC-OPF) problems need to be solved more frequently in the future to maintain stable and economic operation. To tackle this challenge, a deep neural network-based voltage-constrained approach (DeepOPF-V) is proposed to find feasible solutions with high computational efficiency. It predicts voltages of all buses and then uses them to obtain all remaining variables. A fast post-processing method is developed to enforce generation constraints. The effectiveness of DeepOPF-V is validated by case studies of several IEEE test systems. Compared with existing approaches, DeepOPF-V achieves a state-of-art computation speedup up to three orders of magnitude and has better performance in preserving the feasibility of the solution.