 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: SpatioTemporal Adaptive Reward Allocation for Text-to-Image RL Post-Training
Jun 18, 2026Existing RL post-training methods for text-to-image generation usually convert the final-image reward into a single scalar advantage and apply it with the same strength to the entire generative trajectory. However, text-to-image generation naturally has temporal and spatial structure: different denoising steps are responsible for different generation stages, and the content that truly determines text alignment often appears only in part of the image. This granularity mismatch makes it difficult for policy updates to focus on the generative components that actually affect the reward. To address this issue, we propose \textbf{SpatioTemporal Adaptive Reward (STAR) Allocation} for RL post-training of text-to-image diffusion and flow models. STAR uses text-image attention inside the generative model and starts from the core content that the user truly cares about in the prompt. It constructs spatial allocation maps that dynamically vary across denoising steps and rollouts, and allocates the same group-relative advantage to more relevant latent regions with almost no additional computational overhead. STAR then applies stronger policy updates to these regions through a spatially resolved policy objective. We use Stable Diffusion 3.5 Medium as the base model and evaluate on three tasks: GenEval, OCR text rendering, and PickScore. Experimental results show that STAR improves compositional semantic alignment, text rendering, and preference optimization without changing the external reward source, achieving $\mathbf{0.9759}$, $\mathbf{0.9757}$, and $\mathbf{23.60}$ on GenEval, OCR, and PickScore, respectively.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
The Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results
Apr 12, 2026This paper provides a review of the NTIRE 2026 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural and realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. Performance is evaluated using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 96 registrants, with 10 teams submitting valid models; ultimately, 9 teams achieved valid scores in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Large Foundation Model for Ads Recommendation
Aug 20, 2025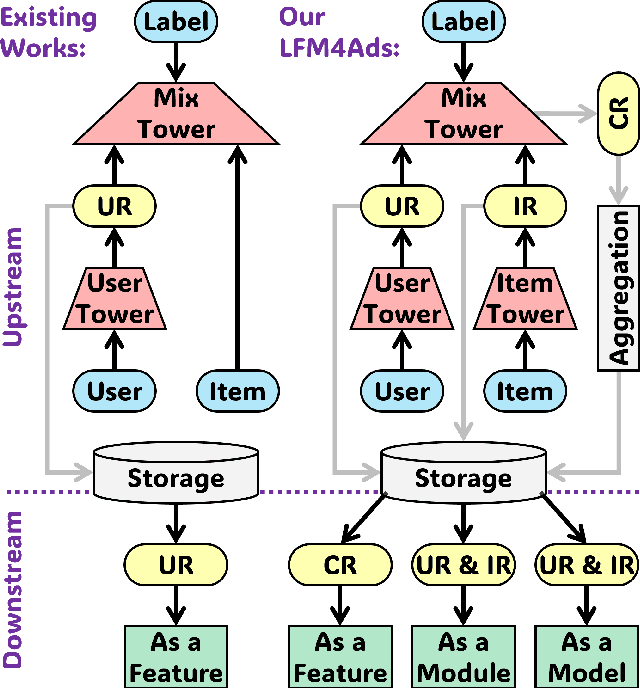
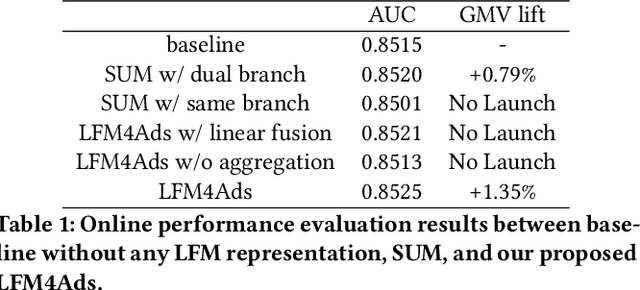
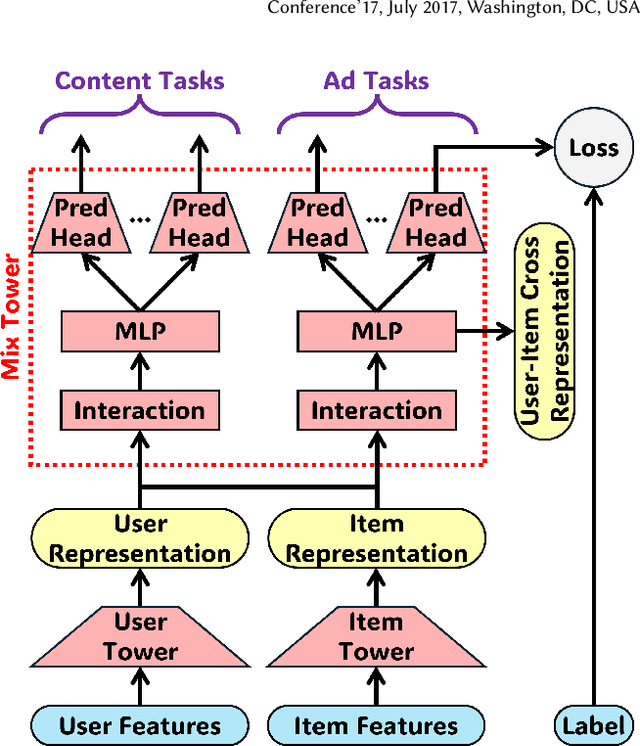
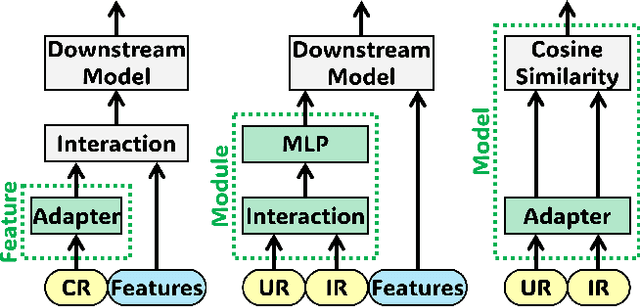
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
Long-Sequence Recommendation Models Need Decoupled Embeddings
Oct 03, 2024



Lifelong user behavior sequences, comprising up to tens of thousands of history behaviors, are crucial for capturing user interests and predicting user responses in modern recommendation systems. A two-stage paradigm is typically adopted to handle these long sequences: a few relevant behaviors are first searched from the original long sequences via an attention mechanism in the first stage and then aggregated with the target item to construct a discriminative representation for prediction in the second stage. In this work, we identify and characterize, for the first time, a neglected deficiency in existing long-sequence recommendation models: a single set of embeddings struggles with learning both attention and representation, leading to interference between these two processes. Initial attempts to address this issue using linear projections -- a technique borrowed from language processing -- proved ineffective, shedding light on the unique challenges of recommendation models. To overcome this, we propose the Decoupled Attention and Representation Embeddings (DARE) model, where two distinct embedding tables are initialized and learned separately to fully decouple attention and representation. Extensive experiments and analysis demonstrate that DARE provides more accurate search of correlated behaviors and outperforms baselines with AUC gains up to 0.9% on public datasets and notable online system improvements. Furthermore, decoupling embedding spaces allows us to reduce the attention embedding dimension and accelerate the search procedure by 50% without significant performance impact, enabling more efficient, high-performance online serving.