 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Political Bias in LLMs through Structured Multi-Agent Debate
Jun 13, 2025Large language models (LLMs) are increasingly used to simulate social behaviour, yet their political biases and interaction dynamics in debates remain underexplored. We investigate how LLM type and agent gender attributes influence political bias using a structured multi-agent debate framework, by engaging Neutral, Republican, and Democrat American LLM agents in debates on politically sensitive topics. We systematically vary the underlying LLMs, agent genders, and debate formats to examine how model provenance and agent personas influence political bias and attitudes throughout debates. We find that Neutral agents consistently align with Democrats, while Republicans shift closer to the Neutral; gender influences agent attitudes, with agents adapting their opinions when aware of other agents' genders; and contrary to prior research, agents with shared political affiliations can form echo chambers, exhibiting the expected intensification of attitudes as debates progress.
Dynamical Diffusion: Learning Temporal Dynamics with Diffusion Models
Mar 02, 2025Diffusion models have emerged as powerful generative frameworks by progressively adding noise to data through a forward process and then reversing this process to generate realistic samples. While these models have achieved strong performance across various tasks and modalities, their application to temporal predictive learning remains underexplored. Existing approaches treat predictive learning as a conditional generation problem, but often fail to fully exploit the temporal dynamics inherent in the data, leading to challenges in generating temporally coherent sequences. To address this, we introduce Dynamical Diffusion (DyDiff), a theoretically sound framework that incorporates temporally aware forward and reverse processes. Dynamical Diffusion explicitly models temporal transitions at each diffusion step, establishing dependencies on preceding states to better capture temporal dynamics. Through the reparameterization trick, Dynamical Diffusion achieves efficient training and inference similar to any standard diffusion model. Extensive experiments across scientific spatiotemporal forecasting, video prediction, and time series forecasting demonstrate that Dynamical Diffusion consistently improves performance in temporal predictive tasks, filling a crucial gap in existing methodologies. Code is available at this repository: https://github.com/thuml/dynamical-diffusion.
Long-Sequence Recommendation Models Need Decoupled Embeddings
Oct 03, 2024



Lifelong user behavior sequences, comprising up to tens of thousands of history behaviors, are crucial for capturing user interests and predicting user responses in modern recommendation systems. A two-stage paradigm is typically adopted to handle these long sequences: a few relevant behaviors are first searched from the original long sequences via an attention mechanism in the first stage and then aggregated with the target item to construct a discriminative representation for prediction in the second stage. In this work, we identify and characterize, for the first time, a neglected deficiency in existing long-sequence recommendation models: a single set of embeddings struggles with learning both attention and representation, leading to interference between these two processes. Initial attempts to address this issue using linear projections -- a technique borrowed from language processing -- proved ineffective, shedding light on the unique challenges of recommendation models. To overcome this, we propose the Decoupled Attention and Representation Embeddings (DARE) model, where two distinct embedding tables are initialized and learned separately to fully decouple attention and representation. Extensive experiments and analysis demonstrate that DARE provides more accurate search of correlated behaviors and outperforms baselines with AUC gains up to 0.9% on public datasets and notable online system improvements. Furthermore, decoupling embedding spaces allows us to reduce the attention embedding dimension and accelerate the search procedure by 50% without significant performance impact, enabling more efficient, high-performance online serving.
On the Embedding Collapse when Scaling up Recommendation Models
Oct 06, 2023Recent advances in deep foundation models have led to a promising trend of developing large recommendation models to leverage vast amounts of available data. However, we experiment to scale up existing recommendation models and observe that the enlarged models do not improve satisfactorily. In this context, we investigate the embedding layers of enlarged models and identify a phenomenon of embedding collapse, which ultimately hinders scalability, wherein the embedding matrix tends to reside in a low-dimensional subspace. Through empirical and theoretical analysis, we demonstrate that the feature interaction module specific to recommendation models has a two-sided effect. On the one hand, the interaction restricts embedding learning when interacting with collapsed embeddings, exacerbating the collapse issue. On the other hand, feature interaction is crucial in mitigating the fitting of spurious features, thereby improving scalability. Based on this analysis, we propose a simple yet effective multi-embedding design incorporating embedding-set-specific interaction modules to capture diverse patterns and reduce collapse. Extensive experiments demonstrate that this proposed design provides consistent scalability for various recommendation models.
ForkMerge: Overcoming Negative Transfer in Multi-Task Learning
Jan 30, 2023The goal of multi-task learning is to utilize useful knowledge from multiple related tasks to improve the generalization performance of all tasks. However, learning multiple tasks simultaneously often results in worse performance than learning them independently, which is known as negative transfer. Most previous works attribute negative transfer in multi-task learning to gradient conflicts between different tasks and propose several heuristics to manipulate the task gradients for mitigating this problem, which mainly considers the optimization difficulty and overlooks the generalization problem. To fully understand the root cause of negative transfer, we experimentally analyze negative transfer from the perspectives of optimization, generalization, and hypothesis space. Stemming from our analysis, we introduce ForkMerge, which periodically forks the model into multiple branches with different task weights, and merges dynamically to filter out detrimental parameter updates to avoid negative transfer. On a series of multi-task learning tasks, ForkMerge achieves improved performance over state-of-the-art methods and largely avoids negative transfer.
Debiased Pseudo Labeling in Self-Training
Feb 18, 2022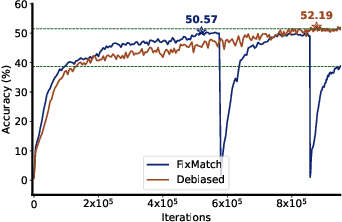
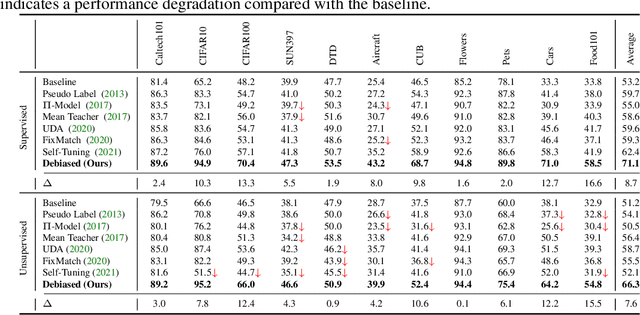
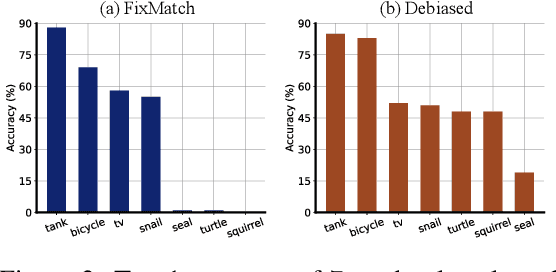
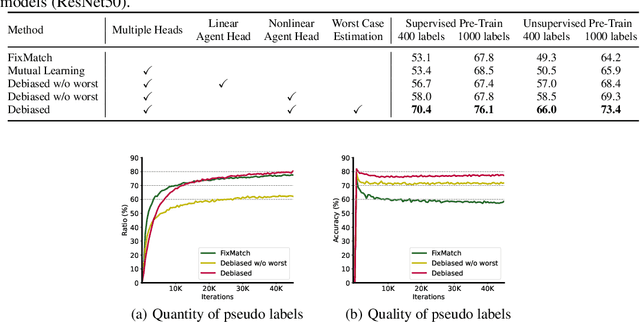
Deep neural networks achieve remarkable performances on a wide range of tasks with the aid of large-scale labeled datasets. However, large-scale annotations are time-consuming and labor-exhaustive to obtain on realistic tasks. To mitigate the requirement for labeled data, self-training is widely used in both academia and industry by pseudo labeling on readily-available unlabeled data. Despite its popularity, pseudo labeling is well-believed to be unreliable and often leads to training instability. Our experimental studies further reveal that the performance of self-training is biased due to data sampling, pre-trained models, and training strategies, especially the inappropriate utilization of pseudo labels. To this end, we propose Debiased, in which the generation and utilization of pseudo labels are decoupled by two independent heads. To further improve the quality of pseudo labels, we introduce a worst-case estimation of pseudo labeling and seamlessly optimize the representations to avoid the worst-case. Extensive experiments justify that the proposed Debiased not only yields an average improvement of $14.4$\% against state-of-the-art algorithms on $11$ tasks (covering generic object recognition, fine-grained object recognition, texture classification, and scene classification) but also helps stabilize training and balance performance across classes.
Decoupled Adaptation for Cross-Domain Object Detection
Oct 06, 2021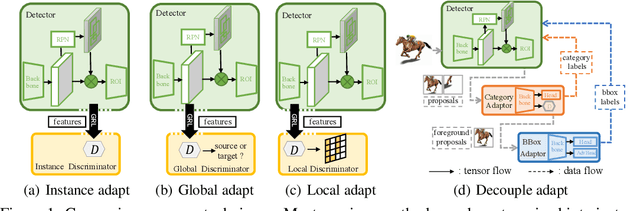
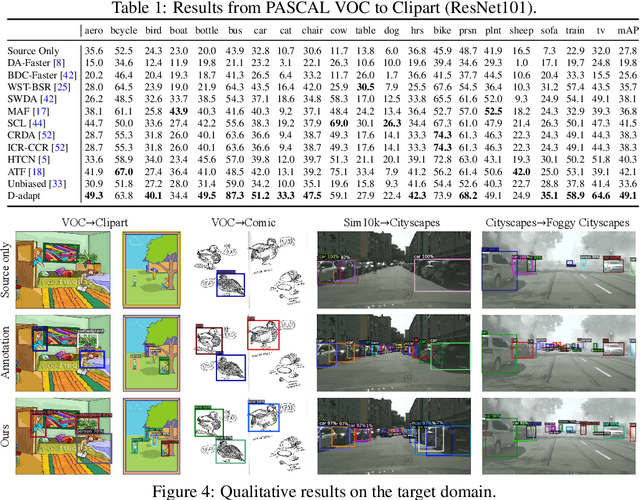
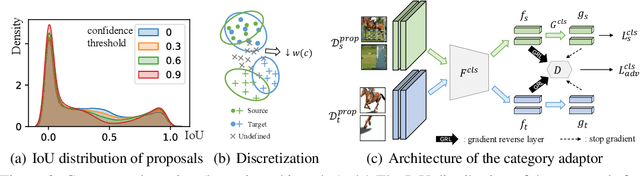
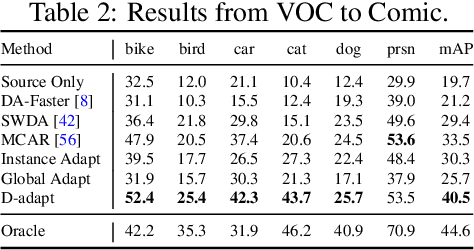
Cross-domain object detection is more challenging than object classification since multiple objects exist in an image and the location of each object is unknown in the unlabeled target domain. As a result, when we adapt features of different objects to enhance the transferability of the detector, the features of the foreground and the background are easy to be confused, which may hurt the discriminability of the detector. Besides, previous methods focused on category adaptation but ignored another important part for object detection, i.e., the adaptation on bounding box regression. To this end, we propose D-adapt, namely Decoupled Adaptation, to decouple the adversarial adaptation and the training of the detector. Besides, we fill the blank of regression domain adaptation in object detection by introducing a bounding box adaptor. Experiments show that D-adapt achieves state-of-the-art results on four cross-domain object detection tasks and yields 17% and 21% relative improvement on benchmark datasets Clipart1k and Comic2k in particular.