 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient XAI Techniques: A Taxonomic Survey
Feb 16, 2023Recently, there has been a growing demand for the deployment of Explainable Artificial Intelligence (XAI) algorithms in real-world applications. However, traditional XAI methods typically suffer from a high computational complexity problem, which discourages the deployment of real-time systems to meet the time-demanding requirements of real-world scenarios. Although many approaches have been proposed to improve the efficiency of XAI methods, a comprehensive understanding of the achievements and challenges is still needed. To this end, in this paper we provide a review of efficient XAI. Specifically, we categorize existing techniques of XAI acceleration into efficient non-amortized and efficient amortized methods. The efficient non-amortized methods focus on data-centric or model-centric acceleration upon each individual instance. In contrast, amortized methods focus on learning a unified distribution of model explanations, following the predictive, generative, or reinforcement frameworks, to rapidly derive multiple model explanations. We also analyze the limitations of an efficient XAI pipeline from the perspectives of the training phase, the deployment phase, and the use scenarios. Finally, we summarize the challenges of deploying XAI acceleration methods to real-world scenarios, overcoming the trade-off between faithfulness and efficiency, and the selection of different acceleration methods.
Retiring $Δ$DP: New Distribution-Level Metrics for Demographic Parity
Jan 31, 2023Demographic parity is the most widely recognized measure of group fairness in machine learning, which ensures equal treatment of different demographic groups. Numerous works aim to achieve demographic parity by pursuing the commonly used metric $\Delta DP$. Unfortunately, in this paper, we reveal that the fairness metric $\Delta DP$ can not precisely measure the violation of demographic parity, because it inherently has the following drawbacks: \textit{i)} zero-value $\Delta DP$ does not guarantee zero violation of demographic parity, \textit{ii)} $\Delta DP$ values can vary with different classification thresholds. To this end, we propose two new fairness metrics, \textsf{A}rea \textsf{B}etween \textsf{P}robability density function \textsf{C}urves (\textsf{ABPC}) and \textsf{A}rea \textsf{B}etween \textsf{C}umulative density function \textsf{C}urves (\textsf{ABCC}), to precisely measure the violation of demographic parity in distribution level. The new fairness metrics directly measure the difference between the distributions of the prediction probability for different demographic groups. Thus our proposed new metrics enjoy: \textit{i)} zero-value \textsf{ABCC}/\textsf{ABPC} guarantees zero violation of demographic parity; \textit{ii)} \textsf{ABCC}/\textsf{ABPC} guarantees demographic parity while the classification threshold adjusted. We further re-evaluate the existing fair models with our proposed fairness metrics and observe different fairness behaviors of those models under the new metrics.
Data-centric AI: Perspectives and Challenges
Jan 12, 2023The role of data in building AI systems has recently been significantly magnified by the emerging concept of data-centric AI (DCAI), which advocates a fundamental shift from model advancements to ensuring data quality and reliability. Although our community has continuously invested efforts into enhancing data in different aspects, they are often isolated initiatives on specific tasks. To facilitate the collective initiative in our community and push forward DCAI, we draw a big picture and bring together three general missions: training data development, evaluation data development, and data maintenance. We provide a top-level discussion on representative DCAI tasks and share perspectives. Finally, we list open challenges to motivate future exploration.
Bring Your Own View: Graph Neural Networks for Link Prediction with Personalized Subgraph Selection
Dec 23, 2022



Graph neural networks (GNNs) have received remarkable success in link prediction (GNNLP) tasks. Existing efforts first predefine the subgraph for the whole dataset and then apply GNNs to encode edge representations by leveraging the neighborhood structure induced by the fixed subgraph. The prominence of GNNLP methods significantly relies on the adhoc subgraph. Since node connectivity in real-world graphs is complex, one shared subgraph is limited for all edges. Thus, the choices of subgraphs should be personalized to different edges. However, performing personalized subgraph selection is nontrivial since the potential selection space grows exponentially to the scale of edges. Besides, the inference edges are not available during training in link prediction scenarios, so the selection process needs to be inductive. To bridge the gap, we introduce a Personalized Subgraph Selector (PS2) as a plug-and-play framework to automatically, personally, and inductively identify optimal subgraphs for different edges when performing GNNLP. PS2 is instantiated as a bi-level optimization problem that can be efficiently solved differently. Coupling GNNLP models with PS2, we suggest a brand-new angle towards GNNLP training: by first identifying the optimal subgraphs for edges; and then focusing on training the inference model by using the sampled subgraphs. Comprehensive experiments endorse the effectiveness of our proposed method across various GNNLP backbones (GCN, GraphSage, NGCF, LightGCN, and SEAL) and diverse benchmarks (Planetoid, OGB, and Recommendation datasets). Our code is publicly available at \url{https://github.com/qiaoyu-tan/PS2}
MolCPT: Molecule Continuous Prompt Tuning to Generalize Molecular Representation Learning
Dec 20, 2022Molecular representation learning is crucial for the problem of molecular property prediction, where graph neural networks (GNNs) serve as an effective solution due to their structure modeling capabilities. Since labeled data is often scarce and expensive to obtain, it is a great challenge for GNNs to generalize in the extensive molecular space. Recently, the training paradigm of "pre-train, fine-tune" has been leveraged to improve the generalization capabilities of GNNs. It uses self-supervised information to pre-train the GNN, and then performs fine-tuning to optimize the downstream task with just a few labels. However, pre-training does not always yield statistically significant improvement, especially for self-supervised learning with random structural masking. In fact, the molecular structure is characterized by motif subgraphs, which are frequently occurring and influence molecular properties. To leverage the task-related motifs, we propose a novel paradigm of "pre-train, prompt, fine-tune" for molecular representation learning, named molecule continuous prompt tuning (MolCPT). MolCPT defines a motif prompting function that uses the pre-trained model to project the standalone input into an expressive prompt. The prompt effectively augments the molecular graph with meaningful motifs in the continuous representation space; this provides more structural patterns to aid the downstream classifier in identifying molecular properties. Extensive experiments on several benchmark datasets show that MolCPT efficiently generalizes pre-trained GNNs for molecular property prediction, with or without a few fine-tuning steps.
TinyKG: Memory-Efficient Training Framework for Knowledge Graph Neural Recommender Systems
Dec 08, 2022



There has been an explosion of interest in designing various Knowledge Graph Neural Networks (KGNNs), which achieve state-of-the-art performance and provide great explainability for recommendation. The promising performance is mainly resulting from their capability of capturing high-order proximity messages over the knowledge graphs. However, training KGNNs at scale is challenging due to the high memory usage. In the forward pass, the automatic differentiation engines (\textsl{e.g.}, TensorFlow/PyTorch) generally need to cache all intermediate activation maps in order to compute gradients in the backward pass, which leads to a large GPU memory footprint. Existing work solves this problem by utilizing multi-GPU distributed frameworks. Nonetheless, this poses a practical challenge when seeking to deploy KGNNs in memory-constrained environments, especially for industry-scale graphs. Here we present TinyKG, a memory-efficient GPU-based training framework for KGNNs for the tasks of recommendation. Specifically, TinyKG uses exact activations in the forward pass while storing a quantized version of activations in the GPU buffers. During the backward pass, these low-precision activations are dequantized back to full-precision tensors, in order to compute gradients. To reduce the quantization errors, TinyKG applies a simple yet effective quantization algorithm to compress the activations, which ensures unbiasedness with low variance. As such, the training memory footprint of KGNNs is largely reduced with negligible accuracy loss. To evaluate the performance of our TinyKG, we conduct comprehensive experiments on real-world datasets. We found that our TinyKG with INT2 quantization aggressively reduces the memory footprint of activation maps with $7 \times$, only with $2\%$ loss in accuracy, allowing us to deploy KGNNs on memory-constrained devices.
Mitigating Relational Bias on Knowledge Graphs
Dec 03, 2022



Knowledge graph data are prevalent in real-world applications, and knowledge graph neural networks (KGNNs) are essential techniques for knowledge graph representation learning. Although KGNN effectively models the structural information from knowledge graphs, these frameworks amplify the underlying data bias that leads to discrimination towards certain groups or individuals in resulting applications. Additionally, as existing debiasing approaches mainly focus on the entity-wise bias, eliminating the multi-hop relational bias that pervasively exists in knowledge graphs remains an open question. However, it is very challenging to eliminate relational bias due to the sparsity of the paths that generate the bias and the non-linear proximity structure of knowledge graphs. To tackle the challenges, we propose Fair-KGNN, a KGNN framework that simultaneously alleviates multi-hop bias and preserves the proximity information of entity-to-relation in knowledge graphs. The proposed framework is generalizable to mitigate the relational bias for all types of KGNN. We develop two instances of Fair-KGNN incorporating with two state-of-the-art KGNN models, RGCN and CompGCN, to mitigate gender-occupation and nationality-salary bias. The experiments carried out on three benchmark knowledge graph datasets demonstrate that the Fair-KGNN can effectively mitigate unfair situations during representation learning while preserving the predictive performance of KGNN models.
QuanGCN: Noise-Adaptive Training for Robust Quantum Graph Convolutional Networks
Nov 09, 2022Quantum neural networks (QNNs), an interdisciplinary field of quantum computing and machine learning, have attracted tremendous research interests due to the specific quantum advantages. Despite lots of efforts developed in computer vision domain, one has not fully explored QNNs for the real-world graph property classification and evaluated them in the quantum device. To bridge the gap, we propose quantum graph convolutional networks (QuanGCN), which learns the local message passing among nodes with the sequence of crossing-gate quantum operations. To mitigate the inherent noises from modern quantum devices, we apply sparse constraint to sparsify the nodes' connections and relieve the error rate of quantum gates, and use skip connection to augment the quantum outputs with original node features to improve robustness. The experimental results show that our QuanGCN is functionally comparable or even superior than the classical algorithms on several benchmark graph datasets. The comprehensive evaluations in both simulator and real quantum machines demonstrate the applicability of QuanGCN to the future graph analysis problem.
RSC: Accelerating Graph Neural Networks Training via Randomized Sparse Computations
Oct 19, 2022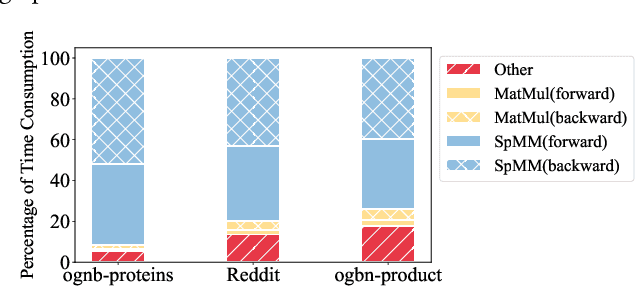

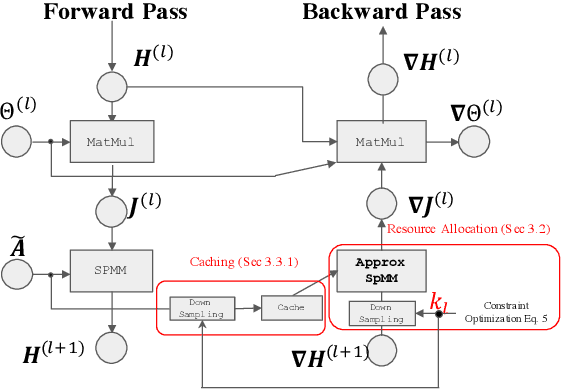
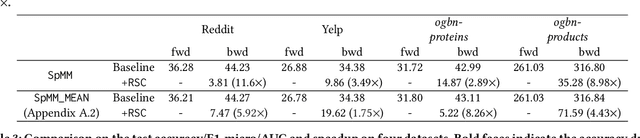
The training of graph neural networks (GNNs) is extremely time consuming because sparse graph-based operations are hard to be accelerated by hardware. Prior art explores trading off the computational precision to reduce the time complexity via sampling-based approximation. Based on the idea, previous works successfully accelerate the dense matrix based operations (e.g., convolution and linear) with negligible accuracy drop. However, unlike dense matrices, sparse matrices are stored in the irregular data format such that each row/column may have different number of non-zero entries. Thus, compared to the dense counterpart, approximating sparse operations has two unique challenges (1) we cannot directly control the efficiency of approximated sparse operation since the computation is only executed on non-zero entries; (2) sub-sampling sparse matrices is much more inefficient due to the irregular data format. To address the issues, our key idea is to control the accuracy-efficiency trade off by optimizing computation resource allocation layer-wisely and epoch-wisely. Specifically, for the first challenge, we customize the computation resource to different sparse operations, while limit the total used resource below a certain budget. For the second challenge, we cache previous sampled sparse matrices to reduce the epoch-wise sampling overhead. Finally, we propose a switching mechanisms to improve the generalization of GNNs trained with approximated operations. To this end, we propose Randomized Sparse Computation, which for the first time demonstrate the potential of training GNNs with approximated operations. In practice, rsc can achieve up to $11.6\times$ speedup for a single sparse operation and a $1.6\times$ end-to-end wall-clock time speedup with negligible accuracy drop.
A Comprehensive Study on Large-Scale Graph Training: Benchmarking and Rethinking
Oct 14, 2022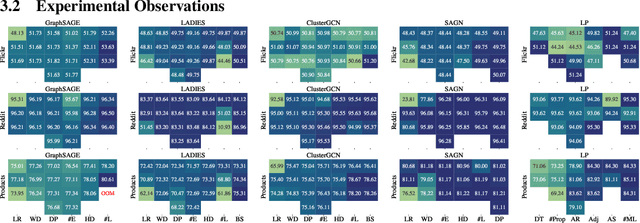
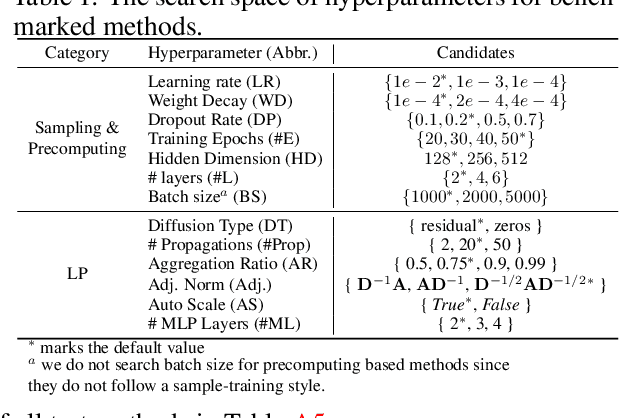

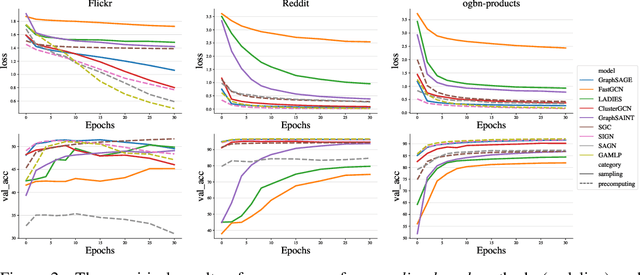
Large-scale graph training is a notoriously challenging problem for graph neural networks (GNNs). Due to the nature of evolving graph structures into the training process, vanilla GNNs usually fail to scale up, limited by the GPU memory space. Up to now, though numerous scalable GNN architectures have been proposed, we still lack a comprehensive survey and fair benchmark of this reservoir to find the rationale for designing scalable GNNs. To this end, we first systematically formulate the representative methods of large-scale graph training into several branches and further establish a fair and consistent benchmark for them by a greedy hyperparameter searching. In addition, regarding efficiency, we theoretically evaluate the time and space complexity of various branches and empirically compare them w.r.t GPU memory usage, throughput, and convergence. Furthermore, We analyze the pros and cons for various branches of scalable GNNs and then present a new ensembling training manner, named EnGCN, to address the existing issues. Remarkably, our proposed method has achieved new state-of-the-art (SOTA) performance on large-scale datasets. Our code is available at https://github.com/VITA-Group/Large_Scale_GCN_Benchmarking.