 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
Mar 12, 2024



We investigate efficient methods for training Large Language Models (LLMs) to possess capabilities in multiple specialized domains, such as coding, math reasoning and world knowledge. Our method, named Branch-Train-MiX (BTX), starts from a seed model, which is branched to train experts in embarrassingly parallel fashion with high throughput and reduced communication cost. After individual experts are asynchronously trained, BTX brings together their feedforward parameters as experts in Mixture-of-Expert (MoE) layers and averages the remaining parameters, followed by an MoE-finetuning stage to learn token-level routing. BTX generalizes two special cases, the Branch-Train-Merge method, which does not have the MoE finetuning stage to learn routing, and sparse upcycling, which omits the stage of training experts asynchronously. Compared to alternative approaches, BTX achieves the best accuracy-efficiency tradeoff.
Instruction-tuned Language Models are Better Knowledge Learners
Feb 20, 2024



In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that PIT significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
In-Context Pretraining: Language Modeling Beyond Document Boundaries
Oct 20, 2023



Large language models (LMs) are currently trained to predict tokens given document prefixes, enabling them to directly perform long-form generation and prompting-style tasks which can be reduced to document completion. Existing pretraining pipelines train LMs by concatenating random sets of short documents to create input contexts but the prior documents provide no signal for predicting the next document. We instead present In-Context Pretraining, a new approach where language models are pretrained on a sequence of related documents, thereby explicitly encouraging them to read and reason across document boundaries. We can do In-Context Pretraining by simply changing the document ordering so that each context contains related documents, and directly applying existing pretraining pipelines. However, this document sorting problem is challenging. There are billions of documents and we would like the sort to maximize contextual similarity for every document without repeating any data. To do this, we introduce approximate algorithms for finding related documents with efficient nearest neighbor search and constructing coherent input contexts with a graph traversal algorithm. Our experiments show In-Context Pretraining offers a simple and scalable approach to significantly enhance LMs'performance: we see notable improvements in tasks that require more complex contextual reasoning, including in-context learning (+8%), reading comprehension (+15%), faithfulness to previous contexts (+16%), long-context reasoning (+5%), and retrieval augmentation (+9%).
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Oct 08, 2023



Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
Reimagining Retrieval Augmented Language Models for Answering Queries
Jun 01, 2023



We present a reality check on large language models and inspect the promise of retrieval augmented language models in comparison. Such language models are semi-parametric, where models integrate model parameters and knowledge from external data sources to make their predictions, as opposed to the parametric nature of vanilla large language models. We give initial experimental findings that semi-parametric architectures can be enhanced with views, a query analyzer/planner, and provenance to make a significantly more powerful system for question answering in terms of accuracy and efficiency, and potentially for other NLP tasks
Towards A Unified View of Sparse Feed-Forward Network in Pretraining Large Language Model
May 23, 2023



Large and sparse feed-forward networks (S-FFN) such as Mixture-of-Experts (MoE) have demonstrated to be an efficient approach for scaling up Transformers model size for pretraining large language models. By only activating part of the FFN parameters conditioning on input, S-FFN improves generalization performance while keeping training and inference costs (in FLOPs) fixed. In this work, we analyzed the two major design choices of S-FFN: the memory block (or expert) size and the memory block selection method under a general conceptual framework of sparse neural memory. Using this unified framework, we compare several S-FFN architectures for language modeling and provide insights into their relative efficacy and efficiency. From our analysis results, we found a simpler selection method -- Avg-K that selects blocks through their mean aggregated hidden states, achieves lower perplexity in language modeling pretraining compared to existing MoE architectures.
LEVER: Learning to Verify Language-to-Code Generation with Execution
Feb 16, 2023The advent of pre-trained code language models (CodeLMs) has lead to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base CodeLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
Dec 28, 2022



Recent work has shown that fine-tuning large pre-trained language models on a collection of tasks described via instructions, a.k.a. instruction-tuning, improves their zero and few-shot generalization to unseen tasks. However, there is a limited understanding of the performance trade-offs of different decisions made during the instruction-tuning process. These decisions include the scale and diversity of the instruction-tuning benchmark, different task sampling strategies, fine-tuning with and without demonstrations, training using specialized datasets for reasoning and dialogue, and finally, the fine-tuning objectives themselves. In this paper, we characterize the effect of instruction-tuning decisions on downstream task performance when scaling both model and benchmark sizes. To this end, we create OPT-IML Bench: a large benchmark for Instruction Meta-Learning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks, and prepare an evaluation framework to measure three types of model generalizations: to tasks from fully held-out categories, to held-out tasks from seen categories, and to held-out instances from seen tasks. Through the lens of this framework, we first present insights about instruction-tuning decisions as applied to OPT-30B and further exploit these insights to train OPT-IML 30B and 175B, which are instruction-tuned versions of OPT. OPT-IML demonstrates all three generalization abilities at both scales on four different evaluation benchmarks with diverse tasks and input formats -- PromptSource, FLAN, Super-NaturalInstructions, and UnifiedSKG. Not only does it significantly outperform OPT on all benchmarks but is also highly competitive with existing models fine-tuned on each specific benchmark. We release OPT-IML at both scales, together with the OPT-IML Bench evaluation framework.
Training Trajectories of Language Models Across Scales
Dec 19, 2022



Scaling up language models has led to unprecedented performance gains, but little is understood about how the training dynamics change as models get larger. How do language models of different sizes learn during pre-training? Why do larger language models demonstrate more desirable behaviors? In this paper, we analyze the intermediate training checkpoints of differently sized OPT models (Zhang et al.,2022)--from 125M to 175B parameters--on next-token prediction, sequence-level generation, and downstream tasks. We find that 1) at a given perplexity and independent of model sizes, a similar subset of training tokens see the most significant reduction in loss, with the rest stagnating or showing double-descent behavior; 2) early in training, all models learn to reduce the perplexity of grammatical sequences that contain hallucinations, with small models halting at this suboptimal distribution and larger ones eventually learning to assign these sequences lower probabilities; 3) perplexity is a strong predictor of in-context learning performance on 74 multiple-choice tasks from BIG-Bench, and this holds independent of the model size. Together, these results show that perplexity is more predictive of model behaviors than model size or training computation.
FOLIO: Natural Language Reasoning with First-Order Logic
Sep 02, 2022
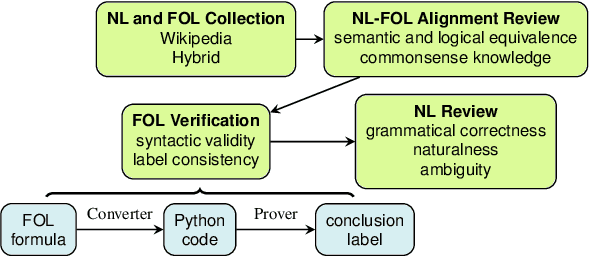
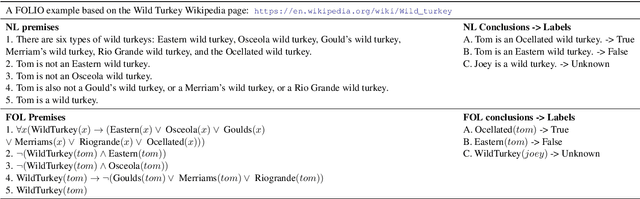
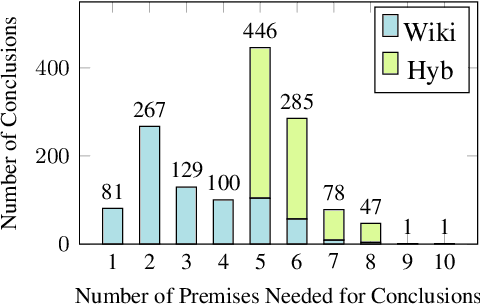
We present FOLIO, a human-annotated, open-domain, and logically complex and diverse dataset for reasoning in natural language (NL), equipped with first order logic (FOL) annotations. FOLIO consists of 1,435 examples (unique conclusions), each paired with one of 487 sets of premises which serve as rules to be used to deductively reason for the validity of each conclusion. The logical correctness of premises and conclusions is ensured by their parallel FOL annotations, which are automatically verified by our FOL inference engine. In addition to the main NL reasoning task, NL-FOL pairs in FOLIO automatically constitute a new NL-FOL translation dataset using FOL as the logical form. Our experiments on FOLIO systematically evaluate the FOL reasoning ability of supervised fine-tuning on medium-sized language models (BERT, RoBERTa) and few-shot prompting on large language models (GPT-NeoX, OPT, GPT-3, Codex). For NL-FOL translation, we experiment with GPT-3 and Codex. Our results show that one of the most capable Large Language Model (LLM) publicly available, GPT-3 davinci, achieves only slightly better than random results with few-shot prompting on a subset of FOLIO, and the model is especially bad at predicting the correct truth values for False and Unknown conclusions. Our dataset and code are available at https://github.com/Yale-LILY/FOLIO.