 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Pruned Key-Value Attention: Learning When to Write by Predicting Future Utility
May 13, 2026Under modern test-time compute and agentic paradigms, language models process ever-longer sequences. Efficient text generation with transformer architectures is increasingly constrained by the Key-Value cache memory footprint and bandwidth. To address this limitation, we introduce Self-Pruned Key-Value Attention (SP-KV), a mechanism designed to predict future KV utility in order to reduce the size of the long-term KV cache. This strategy operates at a fine granularity: a lightweight utility predictor scores each key-value pair, and while recent KVs are always available via a local window, older pairs are written in the cache and used in global attention only if their predicted utility surpasses a given threshold. The LLM and the utility predictor are trained jointly end-to-end exclusively through next-token prediction loss, and are adapted from pretrained LLM checkpoints. Rather than enforcing a fixed compression ratio, SP-KV performs dynamic sparsification: the mechanism adapts to the input and typically reduces the KV cache size by a factor of $3$ to $10\times$, longer sequences often being more compressible. This leads to vast improvements in memory usage and decoding speed, with little to no degradation of validation loss nor performance on a broad set of downstream tasks. Beyond serving as an effective KV-cache reduction mechanism, our method reveals structured layer- and head-specific sparsity patterns that we can use to guide the design of hybrid local-global attention architectures.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Stochastic activations
Sep 26, 2025We introduce stochastic activations. This novel strategy randomly selects between several non-linear functions in the feed-forward layer of a large language model. In particular, we choose between SILU or RELU depending on a Bernoulli draw. This strategy circumvents the optimization problem associated with RELU, namely, the constant shape for negative inputs that prevents the gradient flow. We leverage this strategy in two ways: (1) We use stochastic activations during pre-training and fine-tune the model with RELU, which is used at inference time to provide sparse latent vectors. This reduces the inference FLOPs and translates into a significant speedup in the CPU. Interestingly, this leads to much better results than training from scratch with the RELU activation function. (2) We evaluate stochastic activations for generation. This strategy performs reasonably well: it is only slightly inferior to the best deterministic non-linearity, namely SILU combined with temperature scaling. This offers an alternative to existing strategies by providing a controlled way to increase the diversity of the generated text.
Inference-time sparse attention with asymmetric indexing
Feb 12, 2025
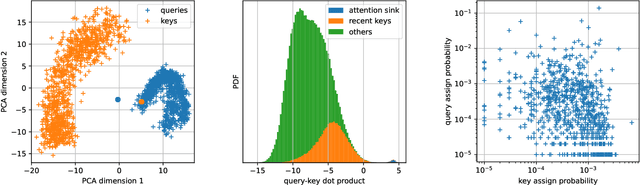


Self-attention in transformer models is an incremental associative memory that maps key vectors to value vectors. One way to speed up self-attention is to employ GPU-compliant vector search algorithms, yet the standard partitioning methods yield poor results in this context, because (1) keys and queries follow different distributions and (2) the effect of RoPE positional encoding. In this paper, we introduce SAAP (Self-Attention with Asymmetric Partitions), which overcomes these problems. It is an asymmetrical indexing technique that employs distinct partitions for keys and queries, thereby approximating self-attention with a data-adaptive sparsity pattern. It works on pretrained language models without finetuning, as it only requires to train (offline) a small query classifier. On a long context Llama 3.1-8b model, with sequences ranging from 100k to 500k tokens, our method typically reduces by a factor 20 the fraction of memory that needs to be looked-up, which translates to a time saving of 60\% when compared to FlashAttention-v2.
Evaluation data contamination in LLMs: how do we measure it and (when) does it matter?
Nov 06, 2024



Hampering the interpretation of benchmark scores, evaluation data contamination has become a growing concern in the evaluation of LLMs, and an active area of research studies its effects. While evaluation data contamination is easily understood intuitively, it is surprisingly difficult to define precisely which samples should be considered contaminated and, consequently, how it impacts benchmark scores. We propose that these questions should be addressed together and that contamination metrics can be assessed based on whether models benefit from the examples they mark contaminated. We propose a novel analysis method called ConTAM, and show with a large scale survey of existing and novel n-gram based contamination metrics across 13 benchmarks and 7 models from 2 different families that ConTAM can be used to better understand evaluation data contamination and its effects. We find that contamination may have a much larger effect than reported in recent LLM releases and benefits models differently at different scales. We also find that considering only the longest contaminated substring provides a better signal than considering a union of all contaminated substrings, and that doing model and benchmark specific threshold analysis greatly increases the specificity of the results. Lastly, we investigate the impact of hyperparameter choices, finding that, among other things, both using larger values of n and disregarding matches that are infrequent in the pre-training data lead to many false negatives. With ConTAM, we provide a method to empirically ground evaluation data contamination metrics in downstream effects. With our exploration, we shed light on how evaluation data contamination can impact LLMs and provide insight into the considerations important when doing contamination analysis. We end our paper by discussing these in more detail and providing concrete suggestions for future work.
Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources
Sep 12, 2024



Large Language Models still struggle in challenging scenarios that leverage structured data, complex reasoning, or tool usage. In this paper, we propose Source2Synth: a new method that can be used for teaching LLMs new skills without relying on costly human annotations. Source2Synth takes as input a custom data source and produces synthetic data points with intermediate reasoning steps grounded in real-world sources. Source2Synth improves the dataset quality by discarding low-quality generations based on their answerability. We demonstrate the generality of this approach by applying it to two challenging domains: we test reasoning abilities in multi-hop question answering (MHQA), and tool usage in tabular question answering (TQA). Our method improves performance by 25.51% for TQA on WikiSQL and 22.57% for MHQA on HotPotQA compared to the fine-tuned baselines.
TOOLVERIFIER: Generalization to New Tools via Self-Verification
Feb 21, 2024



Teaching language models to use tools is an important milestone towards building general assistants, but remains an open problem. While there has been significant progress on learning to use specific tools via fine-tuning, language models still struggle with learning how to robustly use new tools from only a few demonstrations. In this work we introduce a self-verification method which distinguishes between close candidates by self-asking contrastive questions during (1) tool selection; and (2) parameter generation. We construct synthetic, high-quality, self-generated data for this goal using Llama-2 70B, which we intend to release publicly. Extensive experiments on 4 tasks from the ToolBench benchmark, consisting of 17 unseen tools, demonstrate an average improvement of 22% over few-shot baselines, even in scenarios where the distinctions between candidate tools are finely nuanced.
The Faiss library
Jan 16, 2024



Vector databases manage large collections of embedding vectors. As AI applications are growing rapidly, so are the number of embeddings that need to be stored and indexed. The Faiss library is dedicated to vector similarity search, a core functionality of vector databases. Faiss is a toolkit of indexing methods and related primitives used to search, cluster, compress and transform vectors. This paper first describes the tradeoff space of vector search, then the design principles of Faiss in terms of structure, approach to optimization and interfacing. We benchmark key features of the library and discuss a few selected applications to highlight its broad applicability.
In-Context Pretraining: Language Modeling Beyond Document Boundaries
Oct 20, 2023



Large language models (LMs) are currently trained to predict tokens given document prefixes, enabling them to directly perform long-form generation and prompting-style tasks which can be reduced to document completion. Existing pretraining pipelines train LMs by concatenating random sets of short documents to create input contexts but the prior documents provide no signal for predicting the next document. We instead present In-Context Pretraining, a new approach where language models are pretrained on a sequence of related documents, thereby explicitly encouraging them to read and reason across document boundaries. We can do In-Context Pretraining by simply changing the document ordering so that each context contains related documents, and directly applying existing pretraining pipelines. However, this document sorting problem is challenging. There are billions of documents and we would like the sort to maximize contextual similarity for every document without repeating any data. To do this, we introduce approximate algorithms for finding related documents with efficient nearest neighbor search and constructing coherent input contexts with a graph traversal algorithm. Our experiments show In-Context Pretraining offers a simple and scalable approach to significantly enhance LMs'performance: we see notable improvements in tasks that require more complex contextual reasoning, including in-context learning (+8%), reading comprehension (+15%), faithfulness to previous contexts (+16%), long-context reasoning (+5%), and retrieval augmentation (+9%).
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Oct 08, 2023



Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.