 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAgents: An Open Platform for Language Agents in the Wild
Oct 16, 2023



Language agents show potential in being capable of utilizing natural language for varied and intricate tasks in diverse environments, particularly when built upon large language models (LLMs). Current language agent frameworks aim to facilitate the construction of proof-of-concept language agents while neglecting the non-expert user access to agents and paying little attention to application-level designs. We present OpenAgents, an open platform for using and hosting language agents in the wild of everyday life. OpenAgents includes three agents: (1) Data Agent for data analysis with Python/SQL and data tools; (2) Plugins Agent with 200+ daily API tools; (3) Web Agent for autonomous web browsing. OpenAgents enables general users to interact with agent functionalities through a web user interface optimized for swift responses and common failures while offering developers and researchers a seamless deployment experience on local setups, providing a foundation for crafting innovative language agents and facilitating real-world evaluations. We elucidate the challenges and opportunities, aspiring to set a foundation for future research and development of real-world language agents.
Towards A Unified View of Sparse Feed-Forward Network in Pretraining Large Language Model
May 23, 2023



Large and sparse feed-forward networks (S-FFN) such as Mixture-of-Experts (MoE) have demonstrated to be an efficient approach for scaling up Transformers model size for pretraining large language models. By only activating part of the FFN parameters conditioning on input, S-FFN improves generalization performance while keeping training and inference costs (in FLOPs) fixed. In this work, we analyzed the two major design choices of S-FFN: the memory block (or expert) size and the memory block selection method under a general conceptual framework of sparse neural memory. Using this unified framework, we compare several S-FFN architectures for language modeling and provide insights into their relative efficacy and efficiency. From our analysis results, we found a simpler selection method -- Avg-K that selects blocks through their mean aggregated hidden states, achieves lower perplexity in language modeling pretraining compared to existing MoE architectures.
Learning to translate by learning to communicate
Jul 14, 2022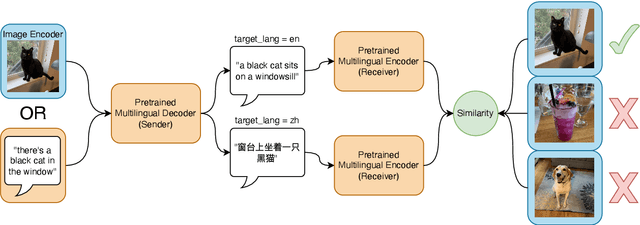
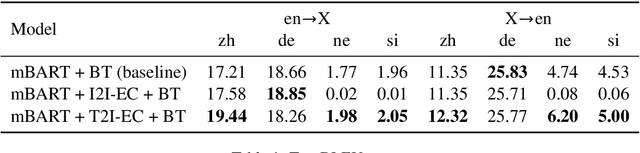
We formulate and test a technique to use Emergent Communication (EC) with a pretrained multilingual model to improve on modern Unsupervised NMT systems, especially for low-resource languages. It has been argued that the currently dominant paradigm in NLP of pretraining on text-only corpora will not yield robust natural language understanding systems, and the need for grounded, goal-oriented, and interactive language learning has been highlighted. In our approach, we embed a modern multilingual model (mBART, Liu et. al. 2020) into an EC image-reference game, in which the model is incentivized to use multilingual generations to accomplish a vision-grounded task, with the hypothesis that this will align multiple languages to a shared task space. We present two variants of EC Fine-Tuning (Steinert-Threlkeld et. al. 2022), one of which outperforms a backtranslation-based baseline in 6/8 translation settings, and proves especially beneficial for the very low-resource languages of Nepali and Sinhala.
Probing Across Time: What Does RoBERTa Know and When?
Apr 16, 2021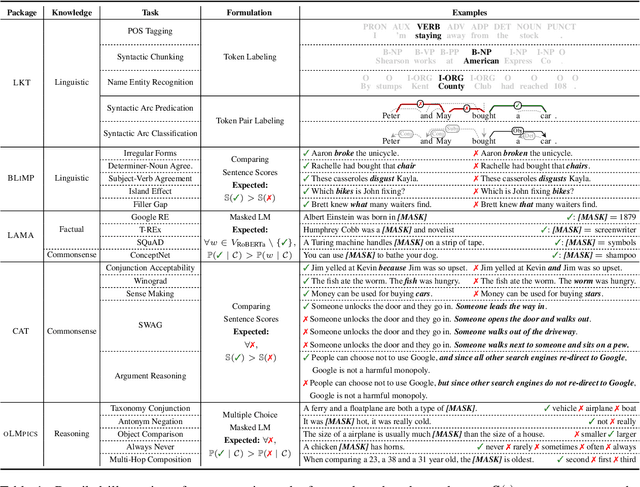
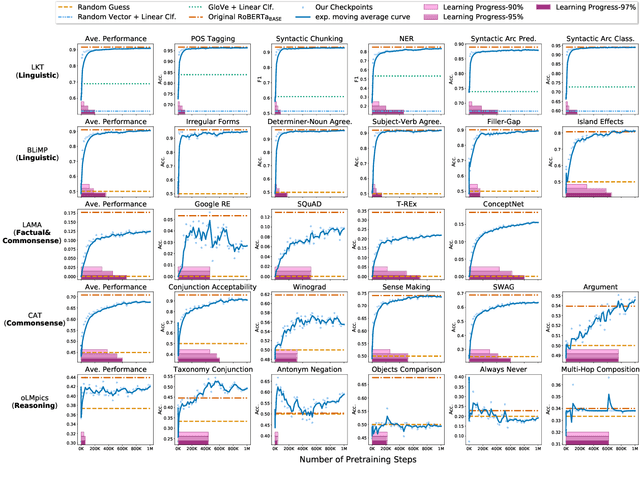
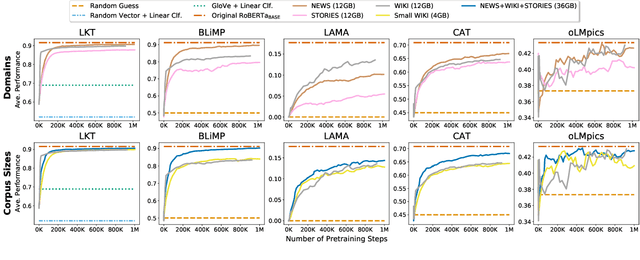
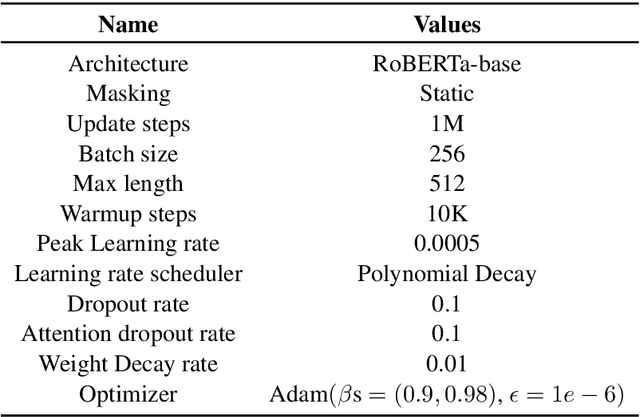
Models of language trained on very large corpora have been demonstrated useful for NLP. As fixed artifacts, they have become the object of intense study, with many researchers "probing" the extent to which linguistic abstractions, factual and commonsense knowledge, and reasoning abilities they acquire and readily demonstrate. Building on this line of work, we consider a new question: for types of knowledge a language model learns, when during (pre)training are they acquired? We plot probing performance across iterations, using RoBERTa as a case study. Among our findings: linguistic knowledge is acquired fast, stably, and robustly across domains. Facts and commonsense are slower and more domain-sensitive. Reasoning abilities are, in general, not stably acquired. As new datasets, pretraining protocols, and probes emerge, we believe that probing-across-time analyses can help researchers understand the complex, intermingled learning that these models undergo and guide us toward more efficient approaches that accomplish necessary learning faster.
Linguistically-Informed Transformations (LIT): A Method for Automatically Generating Contrast Sets
Nov 12, 2020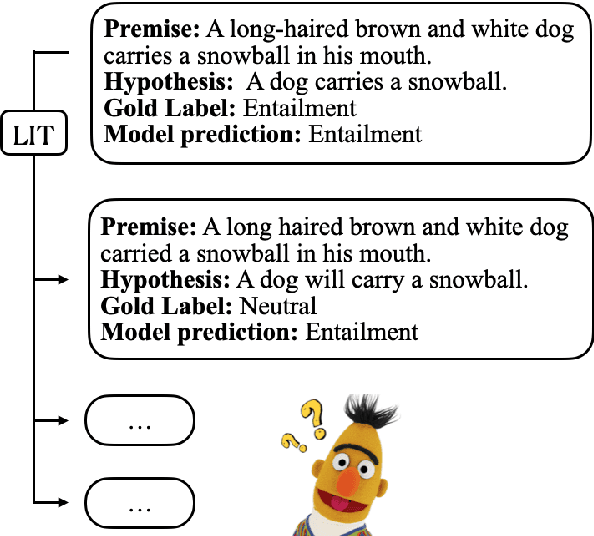

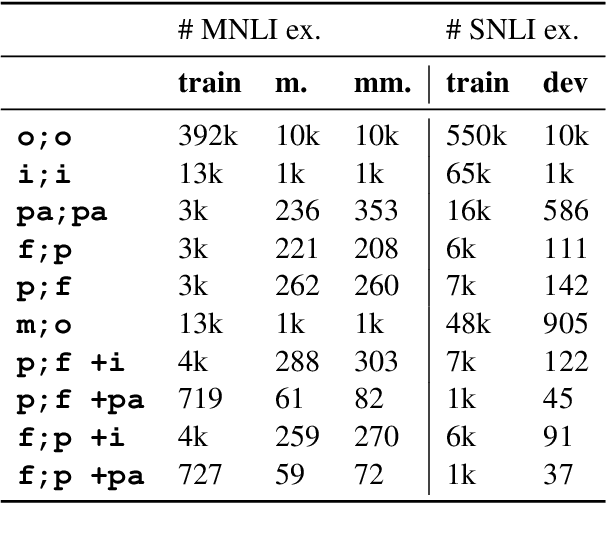
Although large-scale pretrained language models, such as BERT and RoBERTa, have achieved superhuman performance on in-distribution test sets, their performance suffers on out-of-distribution test sets (e.g., on contrast sets). Building contrast sets often re-quires human-expert annotation, which is expensive and hard to create on a large scale. In this work, we propose a Linguistically-Informed Transformation (LIT) method to automatically generate contrast sets, which enables practitioners to explore linguistic phenomena of interests as well as compose different phenomena. Experimenting with our method on SNLI and MNLI shows that current pretrained language models, although being claimed to contain sufficient linguistic knowledge, struggle on our automatically generated contrast sets. Furthermore, we improve models' performance on the contrast sets by apply-ing LIT to augment the training data, without affecting performance on the original data.