 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimelineQA: A Benchmark for Question Answering over Timelines
Jun 01, 2023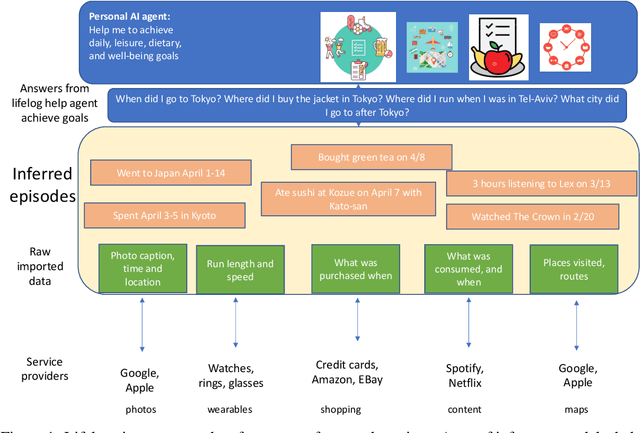

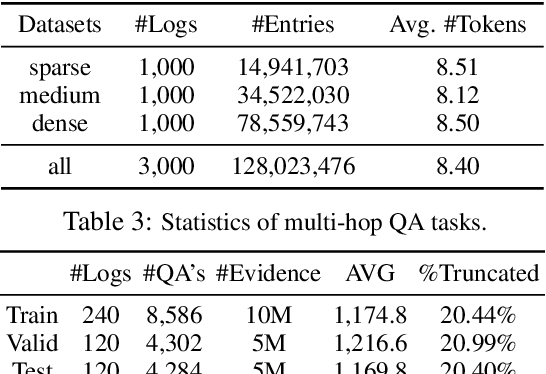
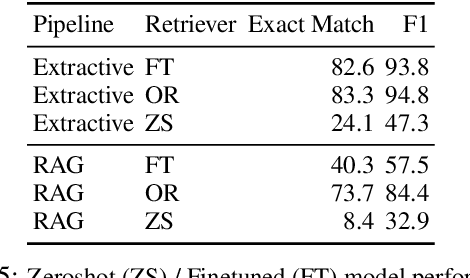
Lifelogs are descriptions of experiences that a person had during their life. Lifelogs are created by fusing data from the multitude of digital services, such as online photos, maps, shopping and content streaming services. Question answering over lifelogs can offer personal assistants a critical resource when they try to provide advice in context. However, obtaining answers to questions over lifelogs is beyond the current state of the art of question answering techniques for a variety of reasons, the most pronounced of which is that lifelogs combine free text with some degree of structure such as temporal and geographical information. We create and publicly release TimelineQA1, a benchmark for accelerating progress on querying lifelogs. TimelineQA generates lifelogs of imaginary people. The episodes in the lifelog range from major life episodes such as high school graduation to those that occur on a daily basis such as going for a run. We describe a set of experiments on TimelineQA with several state-of-the-art QA models. Our experiments reveal that for atomic queries, an extractive QA system significantly out-performs a state-of-the-art retrieval-augmented QA system. For multi-hop queries involving aggregates, we show that the best result is obtained with a state-of-the-art table QA technique, assuming the ground truth set of episodes for deriving the answer is available.
Reimagining Retrieval Augmented Language Models for Answering Queries
Jun 01, 2023



We present a reality check on large language models and inspect the promise of retrieval augmented language models in comparison. Such language models are semi-parametric, where models integrate model parameters and knowledge from external data sources to make their predictions, as opposed to the parametric nature of vanilla large language models. We give initial experimental findings that semi-parametric architectures can be enhanced with views, a query analyzer/planner, and provenance to make a significantly more powerful system for question answering in terms of accuracy and efficiency, and potentially for other NLP tasks
Unstructured and structured data: Can we have the best of both worlds with large language models?
Apr 25, 2023This paper presents an opinion on the potential of using large language models to query on both unstructured and structured data. It also outlines some research challenges related to the topic of building question-answering systems for both types of data.
Annotating Columns with Pre-trained Language Models
Apr 05, 2021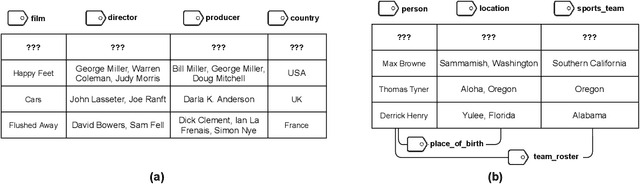
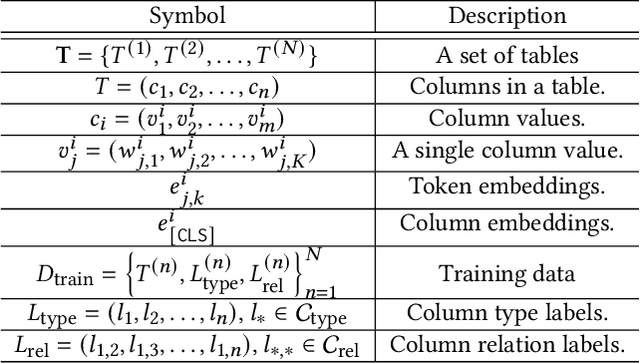
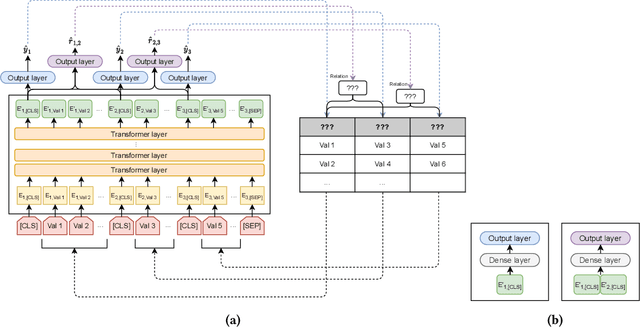
Inferring meta information about tables, such as column headers or relationships between columns, is an active research topic in data management as we find many tables are missing some of this information. In this paper, we study the problem of annotating table columns (i.e., predicting column types and the relationships between columns) using only information from the table itself. We show that a multi-task learning approach (called Doduo), trained using pre-trained language models on both tasks outperforms individual learning approaches. Experimental results show that Doduo establishes new state-of-the-art performance on two benchmarks for the column type prediction and column relation prediction tasks with up to 4.0% and 11.9% improvements, respectively. We also establish that Doduo can already perform the previous state-of-the-art performance with a minimal number of tokens, only 8 tokens per column.
Convex Aggregation for Opinion Summarization
Apr 03, 2021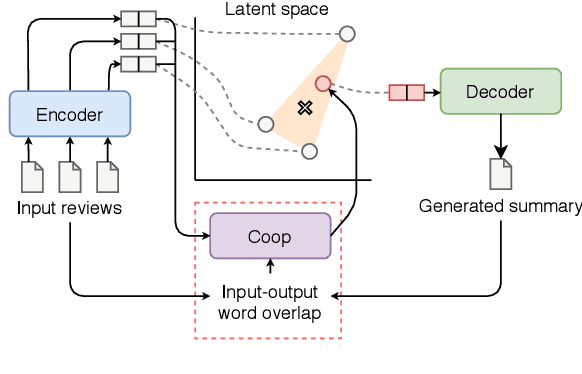
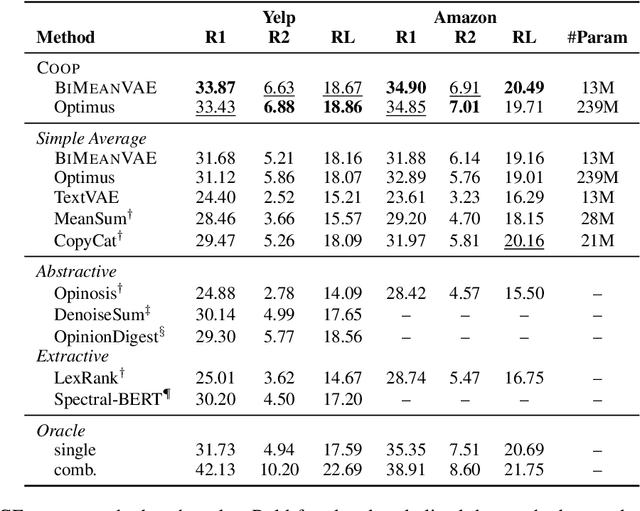
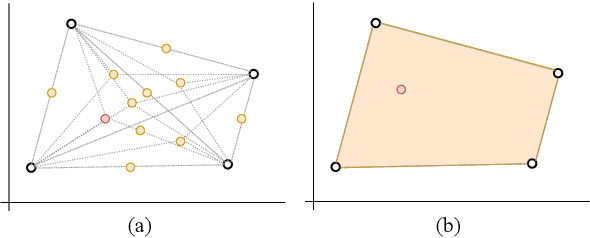
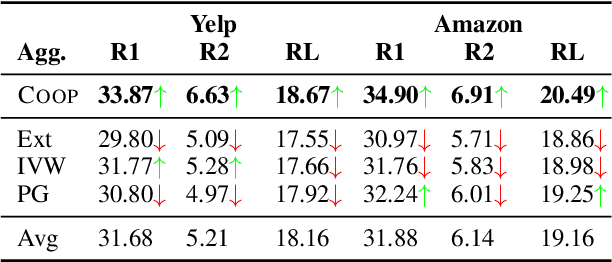
Recent approaches for unsupervised opinion summarization have predominantly used the review reconstruction training paradigm. An encoder-decoder model is trained to reconstruct single reviews and learns a latent review encoding space. At summarization time, the unweighted average of latent review vectors is decoded into a summary. In this paper, we challenge the convention of simply averaging the latent vector set, and claim that this simplistic approach fails to consider variations in the quality of input reviews or the idiosyncrasies of the decoder. We propose Coop, a convex vector aggregation framework for opinion summarization, that searches for better combinations of input reviews. Coop requires no further supervision and uses a simple word overlap objective to help the model generate summaries that are more consistent with input reviews. Experimental results show that extending opinion summarizers with Coop results in state-of-the-art performance, with ROUGE-1 improvements of 3.7% and 2.9% on the Yelp and Amazon benchmark datasets, respectively.
Deep or Simple Models for Semantic Tagging? It Depends on your Data
Jul 11, 2020
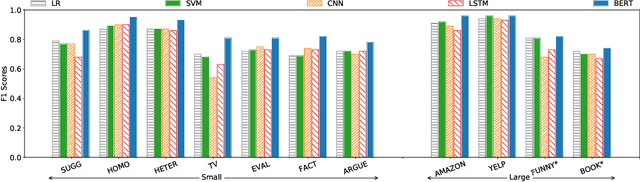
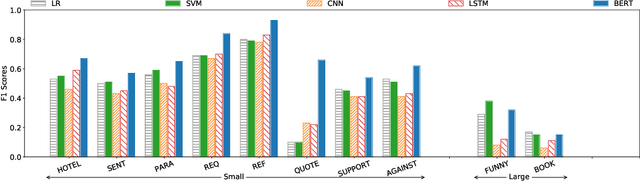
Semantic tagging, which has extensive applications in text mining, predicts whether a given piece of text conveys the meaning of a given semantic tag. The problem of semantic tagging is largely solved with supervised learning and today, deep learning models are widely perceived to be better for semantic tagging. However, there is no comprehensive study supporting the popular belief. Practitioners often have to train different types of models for each semantic tagging task to identify the best model. This process is both expensive and inefficient. We embark on a systematic study to investigate the following question: Are deep models the best performing model for all semantic tagging tasks? To answer this question, we compare deep models against "simple models" over datasets with varying characteristics. Specifically, we select three prevalent deep models (i.e. CNN, LSTM, and BERT) and two simple models (i.e. LR and SVM), and compare their performance on the semantic tagging task over 21 datasets. Results show that the size, the label ratio, and the label cleanliness of a dataset significantly impact the quality of semantic tagging. Simple models achieve similar tagging quality to deep models on large datasets, but the runtime of simple models is much shorter. Moreover, simple models can achieve better tagging quality than deep models when targeting datasets show worse label cleanliness and/or more severe imbalance. Based on these findings, our study can systematically guide practitioners in selecting the right learning model for their semantic tagging task.
ExplainIt: Explainable Review Summarization with Opinion Causality Graphs
May 29, 2020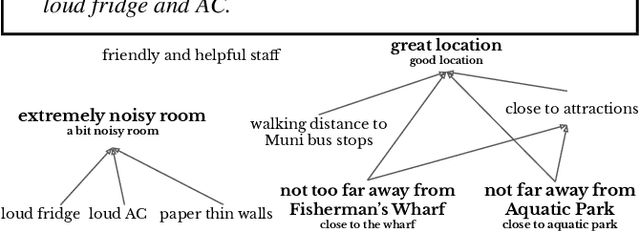


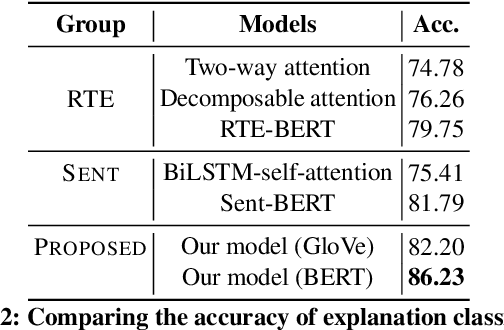
We present ExplainIt, a review summarization system centered around opinion explainability: the simple notion of high-level opinions (e.g. "noisy room") being explainable by lower-level ones (e.g., "loud fridge"). ExplainIt utilizes a combination of supervised and unsupervised components to mine the opinion phrases from reviews and organize them in an Opinion Causality Graph (OCG), a novel semi-structured representation which summarizes causal relations. To construct an OCG, we cluster semantically similar opinions in single nodes, thus canonicalizing opinion paraphrases, and draw directed edges between node pairs that are likely connected by a causal relation. OCGs can be used to generate structured summaries at different levels of granularity and for certain aspects of interest, while simultaneously providing explanations. In this paper, we present the system's individual components and evaluate their effectiveness on their respective sub-tasks, where we report substantial improvements over baselines across two domains. Finally, we validate these results with a user study, showing that ExplainIt produces reasonable opinion explanations according to human judges.
Adaptive Rule Discovery for Labeling Text Data
May 13, 2020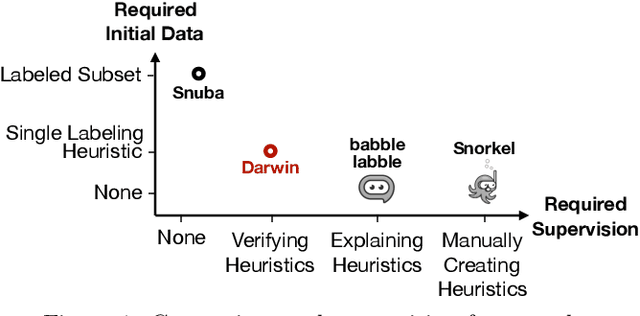
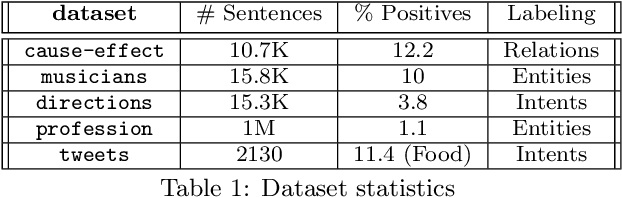
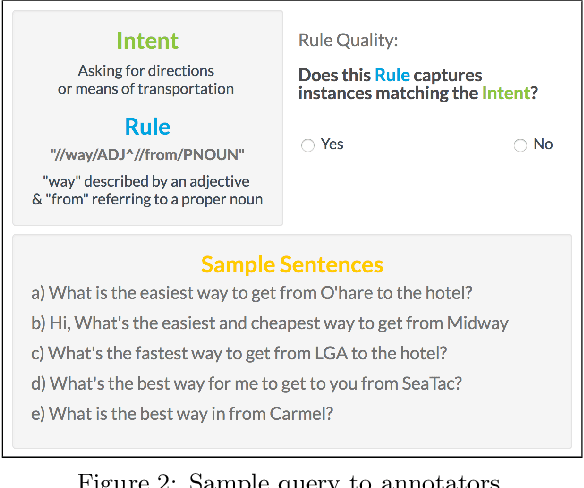
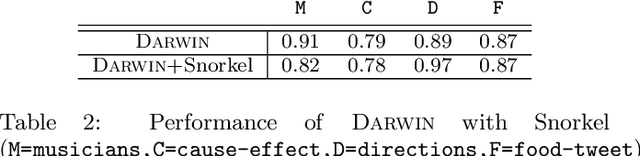
Creating and collecting labeled data is one of the major bottlenecks in machine learning pipelines and the emergence of automated feature generation techniques such as deep learning, which typically requires a lot of training data, has further exacerbated the problem. While weak-supervision techniques have circumvented this bottleneck, existing frameworks either require users to write a set of diverse, high-quality rules to label data (e.g., Snorkel), or require a labeled subset of the data to automatically mine rules (e.g., Snuba). The process of manually writing rules can be tedious and time consuming. At the same time, creating a labeled subset of the data can be costly and even infeasible in imbalanced settings. This is due to the fact that a random sample in imbalanced settings often contains only a few positive instances. To address these shortcomings, we present Darwin, an interactive system designed to alleviate the task of writing rules for labeling text data in weakly-supervised settings. Given an initial labeling rule, Darwin automatically generates a set of candidate rules for the labeling task at hand, and utilizes the annotator's feedback to adapt the candidate rules. We describe how Darwin is scalable and versatile. It can operate over large text corpora (i.e., more than 1 million sentences) and supports a wide range of labeling functions (i.e., any function that can be specified using a context free grammar). Finally, we demonstrate with a suite of experiments over five real-world datasets that Darwin enables annotators to generate weakly-supervised labels efficiently and with a small cost. In fact, our experiments show that rules discovered by Darwin on average identify 40% more positive instances compared to Snuba even when it is provided with 1000 labeled instances.
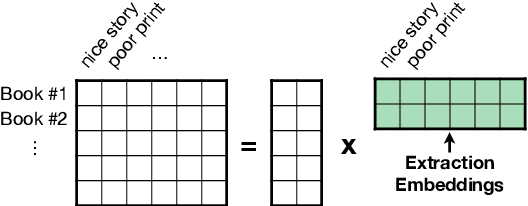
OpinionDigest: A Simple Framework for Opinion Summarization
May 05, 2020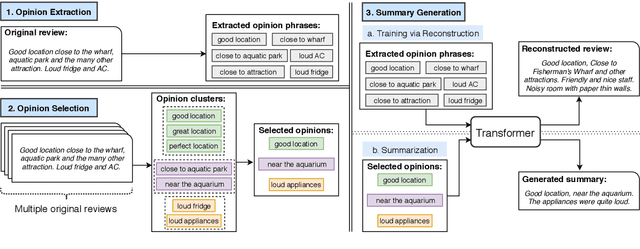
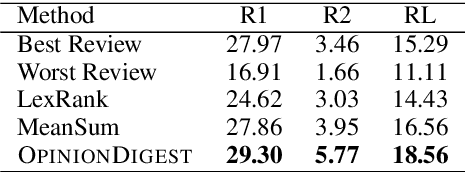
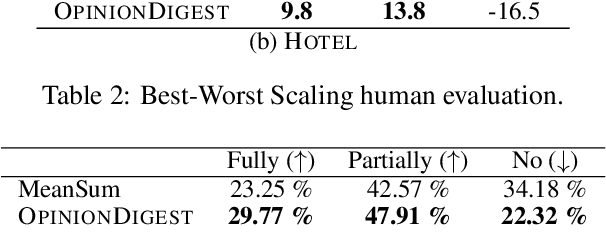
We present OpinionDigest, an abstractive opinion summarization framework, which does not rely on gold-standard summaries for training. The framework uses an Aspect-based Sentiment Analysis model to extract opinion phrases from reviews, and trains a Transformer model to reconstruct the original reviews from these extractions. At summarization time, we merge extractions from multiple reviews and select the most popular ones. The selected opinions are used as input to the trained Transformer model, which verbalizes them into an opinion summary. OpinionDigest can also generate customized summaries, tailored to specific user needs, by filtering the selected opinions according to their aspect and/or sentiment. Automatic evaluation on Yelp data shows that our framework outperforms competitive baselines. Human studies on two corpora verify that OpinionDigest produces informative summaries and shows promising customization capabilities.
SubjQA: A Dataset for Subjectivity and Review Comprehension
Apr 29, 2020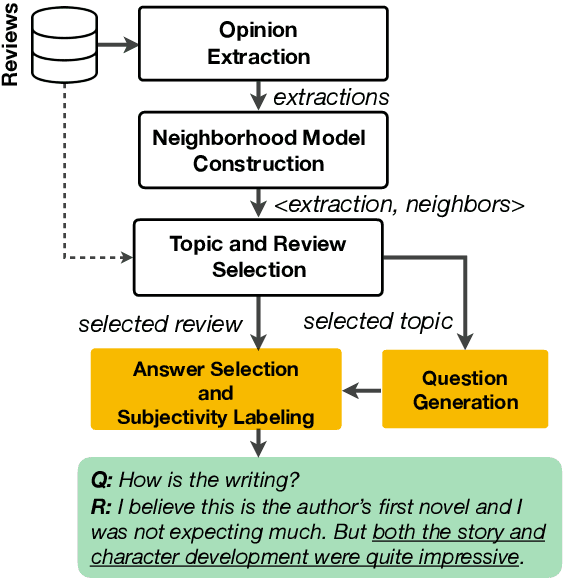
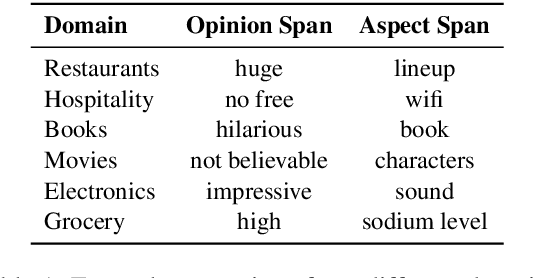
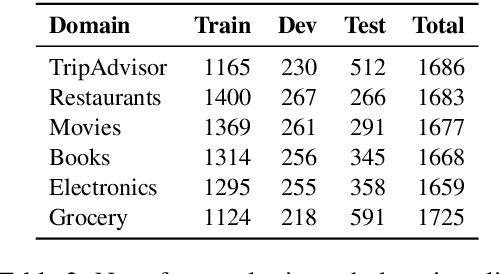
Subjectivity is the expression of internal opinions or beliefs which cannot be objectively observed or verified, and has been shown to be important for sentiment analysis and word-sense disambiguation. Furthermore, subjectivity is an important aspect of user-generated data. In spite of this, subjectivity has not been investigated in contexts where such data is widespread, such as in question answering (QA). We therefore investigate the relationship between subjectivity and QA, while developing a new dataset. We compare and contrast with analyses from previous work, and verify that findings regarding subjectivity still hold when using recently developed NLP architectures. We find that subjectivity is also an important feature in the case of QA, albeit with more intricate interactions between subjectivity and QA performance. For instance, a subjective question may or may not be associated with a subjective answer. We release an English QA dataset (SubjQA) based on customer reviews, containing subjectivity annotations for questions and answer spans across 6 distinct domains.