 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription Logic EL++ Embeddings with Intersectional Closure
Feb 28, 2022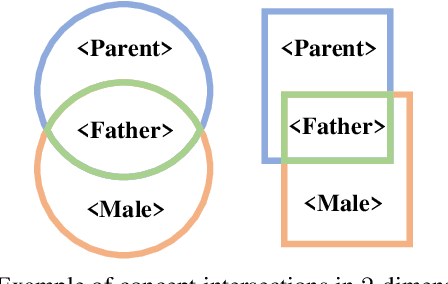
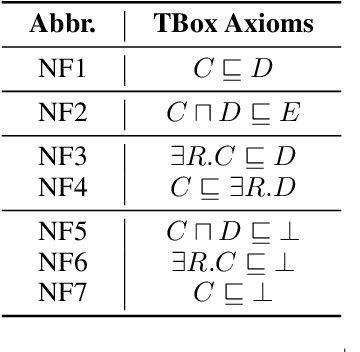
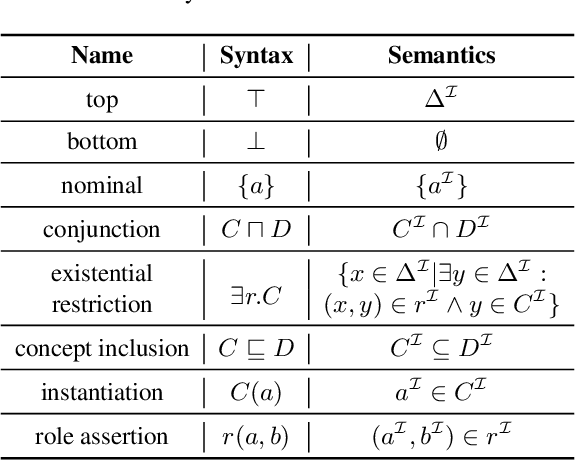
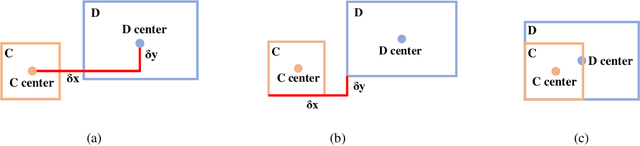
Many ontologies, in particular in the biomedical domain, are based on the Description Logic EL++. Several efforts have been made to interpret and exploit EL++ ontologies by distributed representation learning. Specifically, concepts within EL++ theories have been represented as n-balls within an n-dimensional embedding space. However, the intersectional closure is not satisfied when using n-balls to represent concepts because the intersection of two n-balls is not an n-ball. This leads to challenges when measuring the distance between concepts and inferring equivalence between concepts. To this end, we developed EL Box Embedding (ELBE) to learn Description Logic EL++ embeddings using axis-parallel boxes. We generate specially designed box-based geometric constraints from EL++ axioms for model training. Since the intersection of boxes remains as a box, the intersectional closure is satisfied. We report extensive experimental results on three datasets and present a case study to demonstrate the effectiveness of the proposed method.
Deep Learning for Spatiotemporal Modeling of Urbanization
Dec 17, 2021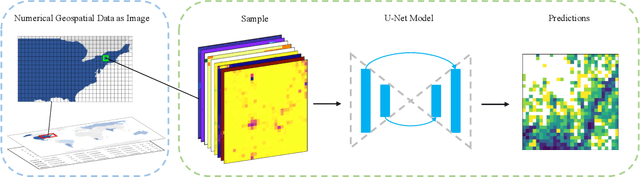
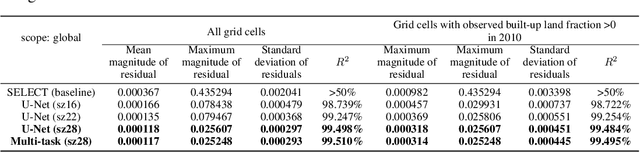
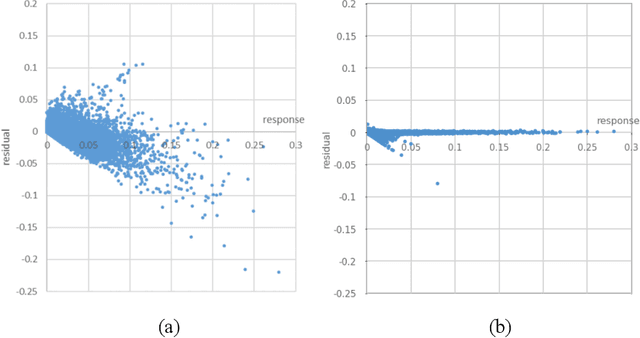

Urbanization has a strong impact on the health and wellbeing of populations across the world. Predictive spatial modeling of urbanization therefore can be a useful tool for effective public health planning. Many spatial urbanization models have been developed using classic machine learning and numerical modeling techniques. However, deep learning with its proven capacity to capture complex spatiotemporal phenomena has not been applied to urbanization modeling. Here we explore the capacity of deep spatial learning for the predictive modeling of urbanization. We treat numerical geospatial data as images with pixels and channels, and enrich the dataset by augmentation, in order to leverage the high capacity of deep learning. Our resulting model can generate end-to-end multi-variable urbanization predictions, and outperforms a state-of-the-art classic machine learning urbanization model in preliminary comparisons.
Understanding the factors driving the opioid epidemic using machine learning
Aug 16, 2021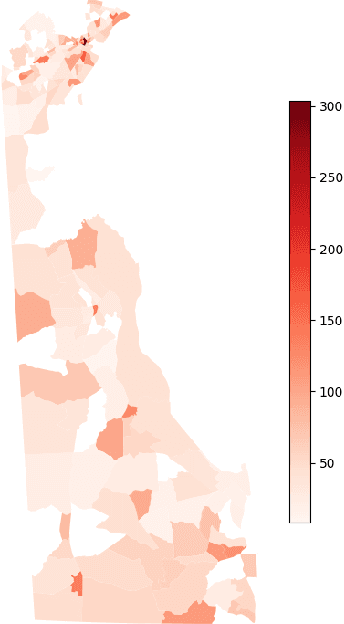
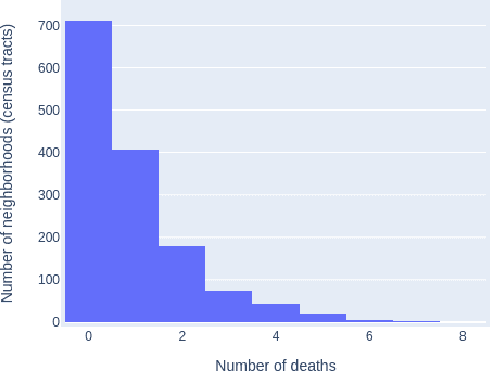
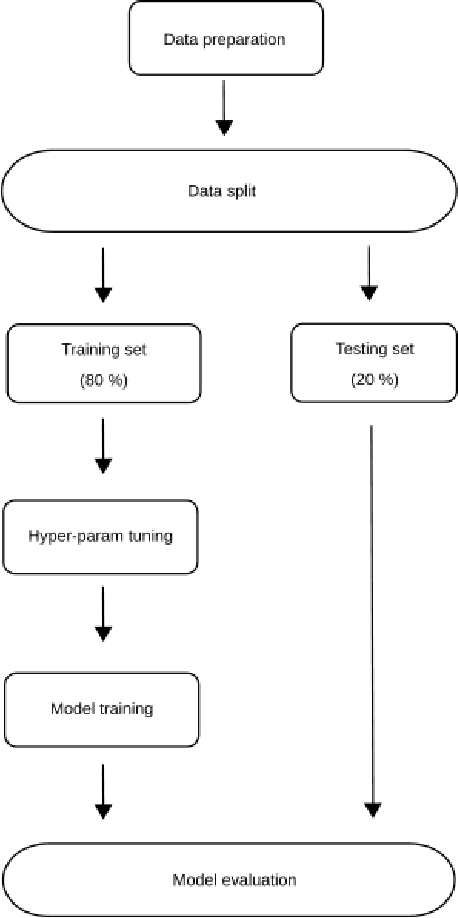
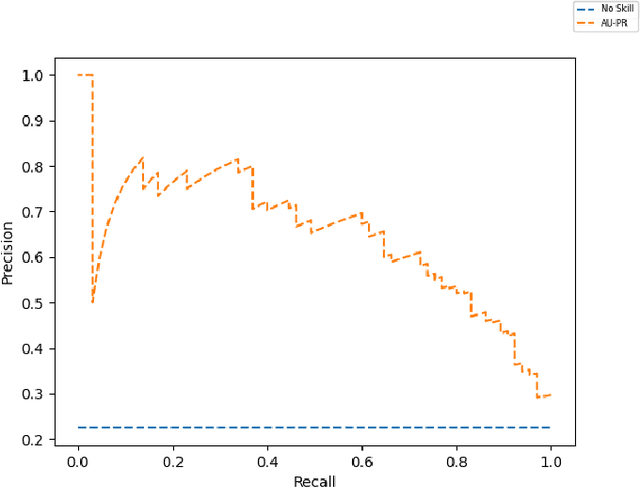
In recent years, the US has experienced an opioid epidemic with an unprecedented number of drugs overdose deaths. Research finds such overdose deaths are linked to neighborhood-level traits, thus providing opportunity to identify effective interventions. Typically, techniques such as Ordinary Least Squares (OLS) or Maximum Likelihood Estimation (MLE) are used to document neighborhood-level factors significant in explaining such adverse outcomes. These techniques are, however, less equipped to ascertain non-linear relationships between confounding factors. Hence, in this study we apply machine learning based techniques to identify opioid risks of neighborhoods in Delaware and explore the correlation of these factors using Shapley Additive explanations (SHAP). We discovered that the factors related to neighborhoods environment, followed by education and then crime, were highly correlated with higher opioid risk. We also explored the change in these correlations over the years to understand the changing dynamics of the epidemic. Furthermore, we discovered that, as the epidemic has shifted from legal (i.e., prescription opioids) to illegal (e.g.,heroin and fentanyl) drugs in recent years, the correlation of environment, crime and health related variables with the opioid risk has increased significantly while the correlation of economic and socio-demographic variables has decreased. The correlation of education related factors has been higher from the start and has increased slightly in recent years suggesting a need for increased awareness about the opioid epidemic.
Out-of-domain Generalization from a Single Source: A Uncertainty Quantification Approach
Aug 05, 2021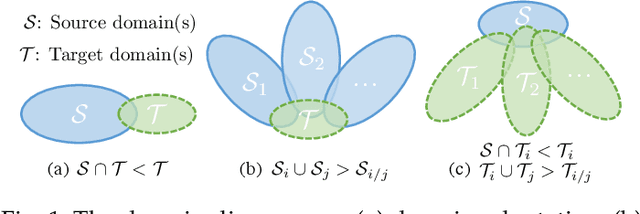
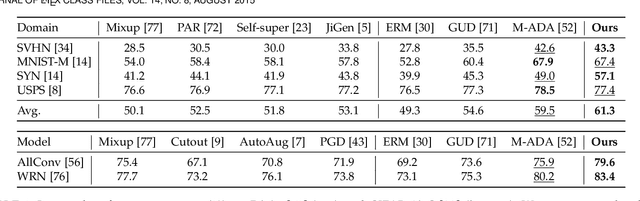
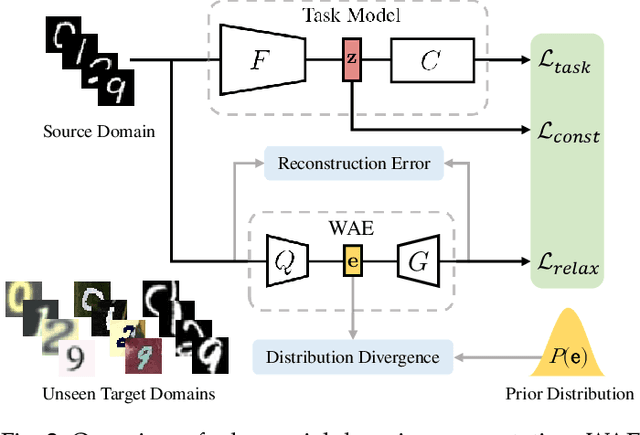
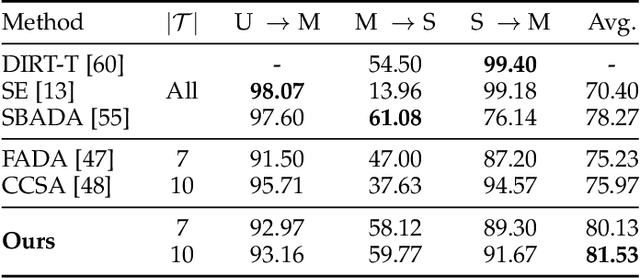
We study a worst-case scenario in generalization: Out-of-domain generalization from a single source. The goal is to learn a robust model from a single source and expect it to generalize over many unknown distributions. This challenging problem has been seldom investigated while existing solutions suffer from various limitations such as the ignorance of uncertainty assessment and label augmentation. In this paper, we propose uncertainty-guided domain generalization to tackle the aforementioned limitations. The key idea is to augment the source capacity in both feature and label spaces, while the augmentation is guided by uncertainty assessment. To the best of our knowledge, this is the first work to (1) quantify the generalization uncertainty from a single source and (2) leverage it to guide both feature and label augmentation for robust generalization. The model training and deployment are effectively organized in a Bayesian meta-learning framework. We conduct extensive comparisons and ablation study to validate our approach. The results prove our superior performance in a wide scope of tasks including image classification, semantic segmentation, text classification, and speech recognition.
Accelerated MRI Reconstruction with Separable and Enhanced Low-Rank Hankel Regularization
Jul 24, 2021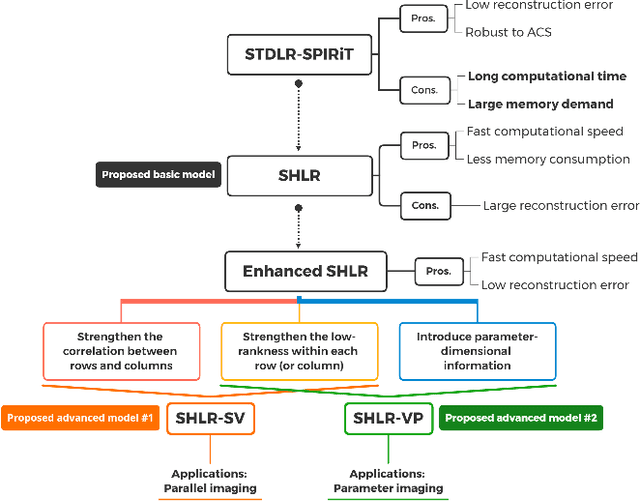
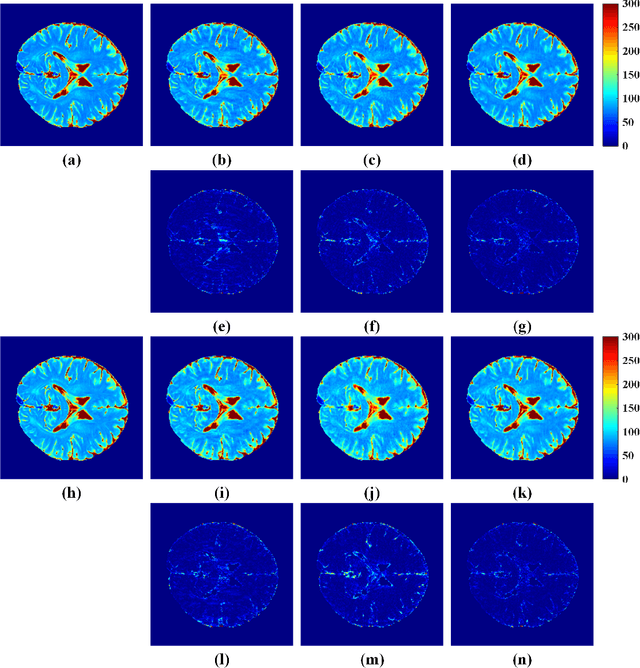
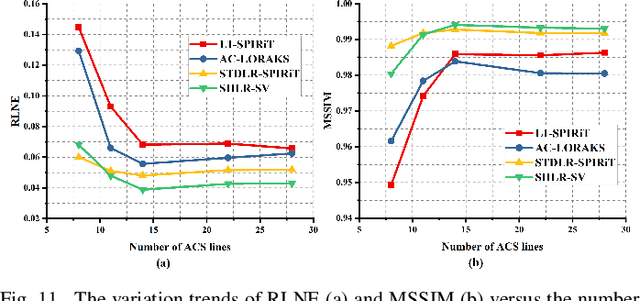
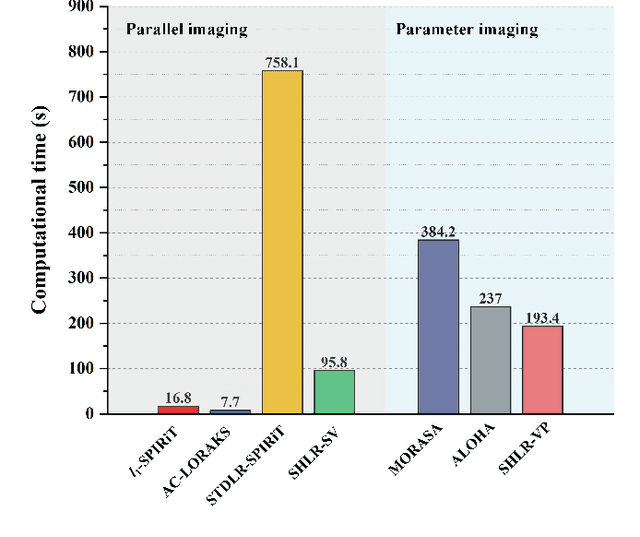
The combination of the sparse sampling and the low-rank structured matrix reconstruction has shown promising performance, enabling a significant reduction of the magnetic resonance imaging data acquisition time. However, the low-rank structured approaches demand considerable memory consumption and are time-consuming due to a noticeable number of matrix operations performed on the huge-size block Hankel-like matrix. In this work, we proposed a novel framework to utilize the low-rank property but meanwhile to achieve faster reconstructions and promising results. The framework allows us to enforce the low-rankness of Hankel matrices constructing from 1D vectors instead of 2D matrices from 1D vectors and thus avoid the construction of huge block Hankel matrix for 2D k-space matrices. Moreover, under this framework, we can easily incorporate other information, such as the smooth phase of the image and the low-rankness in the parameter dimension, to further improve the image quality. We built and validated two models for parallel and parameter magnetic resonance imaging experiments, respectively. Our retrospective in-vivo results indicate that the proposed approaches enable faster reconstructions than the state-of-the-art approaches, e.g., about 8x faster than STDLRSPIRiT, and faithful removal of undersampling artifacts.
Unsupervised Neural Rendering for Image Hazing
Jul 14, 2021


Image hazing aims to render a hazy image from a given clean one, which could be applied to a variety of practical applications such as gaming, filming, photographic filtering, and image dehazing. To generate plausible haze, we study two less-touched but challenging problems in hazy image rendering, namely, i) how to estimate the transmission map from a single image without auxiliary information, and ii) how to adaptively learn the airlight from exemplars, i.e., unpaired real hazy images. To this end, we propose a neural rendering method for image hazing, dubbed as HazeGEN. To be specific, HazeGEN is a knowledge-driven neural network which estimates the transmission map by leveraging a new prior, i.e., there exists the structure similarity (e.g., contour and luminance) between the transmission map and the input clean image. To adaptively learn the airlight, we build a neural module based on another new prior, i.e., the rendered hazy image and the exemplar are similar in the airlight distribution. To the best of our knowledge, this could be the first attempt to deeply rendering hazy images in an unsupervised fashion. Comparing with existing haze generation methods, HazeGEN renders the hazy images in an unsupervised, learnable, and controllable manner, thus avoiding the labor-intensive efforts in paired data collection and the domain-shift issue in haze generation. Extensive experiments show the promising performance of our method comparing with some baselines in both qualitative and quantitative comparisons. The code will be released on GitHub after acceptance.
Dizygotic Conditional Variational AutoEncoder for Multi-Modal and Partial Modality Absent Few-Shot Learning
Jun 28, 2021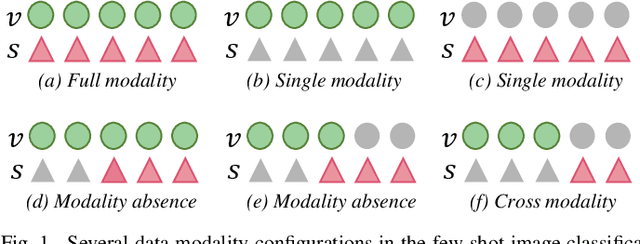
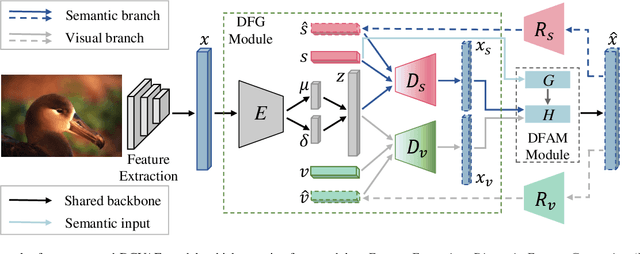
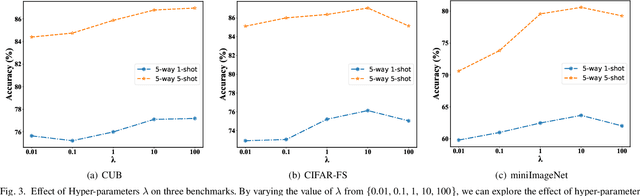
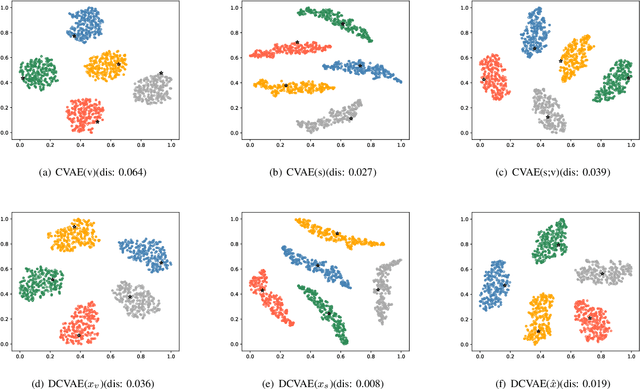
Data augmentation is a powerful technique for improving the performance of the few-shot classification task. It generates more samples as supplements, and then this task can be transformed into a common supervised learning issue for solution. However, most mainstream data augmentation based approaches only consider the single modality information, which leads to the low diversity and quality of generated features. In this paper, we present a novel multi-modal data augmentation approach named Dizygotic Conditional Variational AutoEncoder (DCVAE) for addressing the aforementioned issue. DCVAE conducts feature synthesis via pairing two Conditional Variational AutoEncoders (CVAEs) with the same seed but different modality conditions in a dizygotic symbiosis manner. Subsequently, the generated features of two CVAEs are adaptively combined to yield the final feature, which can be converted back into its paired conditions while ensuring these conditions are consistent with the original conditions not only in representation but also in function. DCVAE essentially provides a new idea of data augmentation in various multi-modal scenarios by exploiting the complement of different modality prior information. Extensive experimental results demonstrate our work achieves state-of-the-art performances on miniImageNet, CIFAR-FS and CUB datasets, and is able to work well in the partial modality absence case.
A Good Image Generator Is What You Need for High-Resolution Video Synthesis
Apr 30, 2021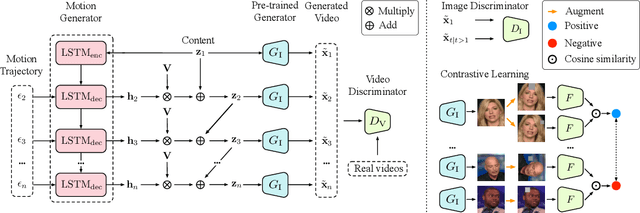



Image and video synthesis are closely related areas aiming at generating content from noise. While rapid progress has been demonstrated in improving image-based models to handle large resolutions, high-quality renderings, and wide variations in image content, achieving comparable video generation results remains problematic. We present a framework that leverages contemporary image generators to render high-resolution videos. We frame the video synthesis problem as discovering a trajectory in the latent space of a pre-trained and fixed image generator. Not only does such a framework render high-resolution videos, but it also is an order of magnitude more computationally efficient. We introduce a motion generator that discovers the desired trajectory, in which content and motion are disentangled. With such a representation, our framework allows for a broad range of applications, including content and motion manipulation. Furthermore, we introduce a new task, which we call cross-domain video synthesis, in which the image and motion generators are trained on disjoint datasets belonging to different domains. This allows for generating moving objects for which the desired video data is not available. Extensive experiments on various datasets demonstrate the advantages of our methods over existing video generation techniques. Code will be released at https://github.com/snap-research/MoCoGAN-HD.
Uncertainty-guided Model Generalization to Unseen Domains
Mar 12, 2021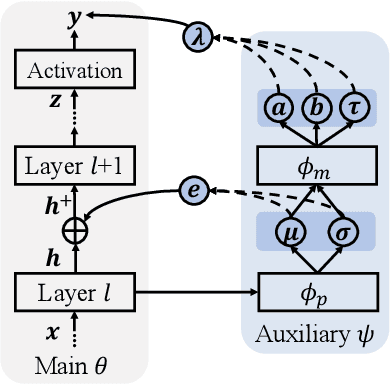
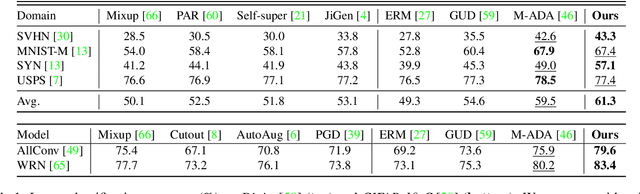
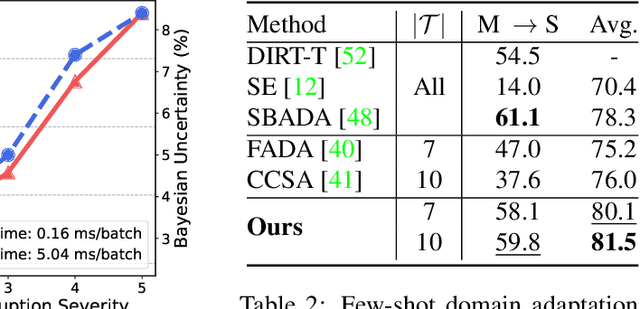
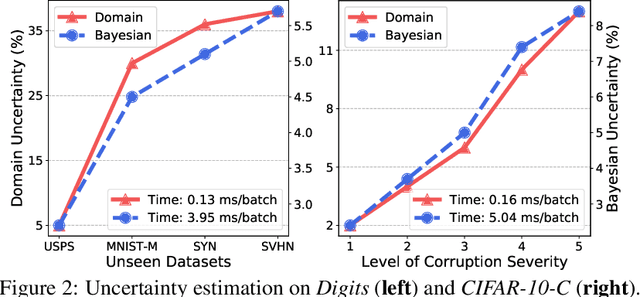
We study a worst-case scenario in generalization: Out-of-domain generalization from a single source. The goal is to learn a robust model from a single source and expect it to generalize over many unknown distributions. This challenging problem has been seldom investigated while existing solutions suffer from various limitations. In this paper, we propose a new solution. The key idea is to augment the source capacity in both input and label spaces, while the augmentation is guided by uncertainty assessment. To the best of our knowledge, this is the first work to (1) access the generalization uncertainty from a single source and (2) leverage it to guide both input and label augmentation for robust generalization. The model training and deployment are effectively organized in a Bayesian meta-learning framework. We conduct extensive comparisons and ablation study to validate our approach. The results prove our superior performance in a wide scope of tasks including image classification, semantic segmentation, text classification, and speech recognition.
SMIL: Multimodal Learning with Severely Missing Modality
Mar 09, 2021
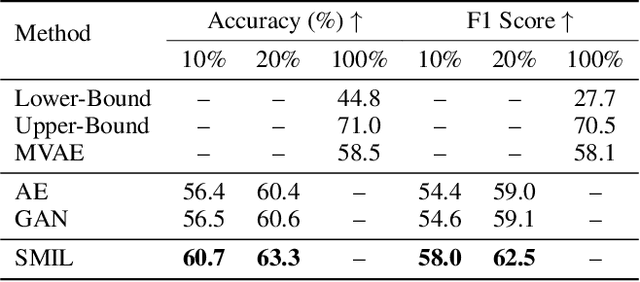
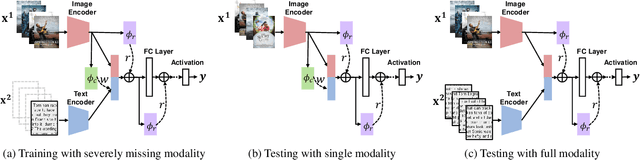
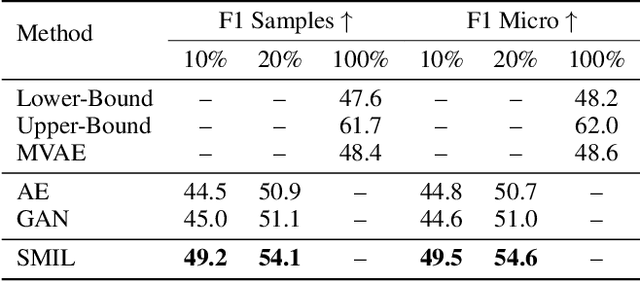
A common assumption in multimodal learning is the completeness of training data, i.e., full modalities are available in all training examples. Although there exists research endeavor in developing novel methods to tackle the incompleteness of testing data, e.g., modalities are partially missing in testing examples, few of them can handle incomplete training modalities. The problem becomes even more challenging if considering the case of severely missing, e.g., 90% training examples may have incomplete modalities. For the first time in the literature, this paper formally studies multimodal learning with missing modality in terms of flexibility (missing modalities in training, testing, or both) and efficiency (most training data have incomplete modality). Technically, we propose a new method named SMIL that leverages Bayesian meta-learning in uniformly achieving both objectives. To validate our idea, we conduct a series of experiments on three popular benchmarks: MM-IMDb, CMU-MOSI, and avMNIST. The results prove the state-of-the-art performance of SMIL over existing methods and generative baselines including autoencoders and generative adversarial networks. Our code is available at https://github.com/mengmenm/SMIL.