 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Distribution-Aligned Flow Matching for Data Synthesis in Medical Image Segmentation
Apr 03, 2026Data heterogeneity hinders clinical deployment of medical image analysis models, and generative data augmentation helps mitigate this issue. However, recent diffusion-based methods that synthesize image-mask pairs often ignore distribution shifts between generated and real images across scenarios, and such mismatches can markedly degrade downstream performance. To address this issue, we propose AlignFlow, a flow matching model that aligns with the target reference image distribution via differentiable reward fine-tuning, and remains effective even when only a small number of reference images are provided. Specifically, we divide the training of the flow matching model into two stages: in the first stage, the model fits the training data to generate plausible images; Then, we introduce a distribution alignment mechanism and employ differentiable reward to steer the generated images toward the distribution of the given samples from the target domain. In addition, to enhance the diversity of generated masks, we also design a flow matching based mask generation to complement the diversity in regions of interest. Extensive experiments demonstrate the effectiveness of our approach, i.e., performance improvement by 3.5-4.0% in mDice and 3.5-5.6% in mIoU across a variety of datasets and scenarios.
Batch-in-Batch: a new adversarial training framework for initial perturbation and sample selection
Jun 06, 2024Adversarial training methods commonly generate independent initial perturbation for adversarial samples from a simple uniform distribution, and obtain the training batch for the classifier without selection. In this work, we propose a simple yet effective training framework called Batch-in-Batch (BB) to enhance models robustness. It involves specifically a joint construction of initial values that could simultaneously generates $m$ sets of perturbations from the original batch set to provide more diversity for adversarial samples; and also includes various sample selection strategies that enable the trained models to have smoother losses and avoid overconfident outputs. Through extensive experiments on three benchmark datasets (CIFAR-10, SVHN, CIFAR-100) with two networks (PreActResNet18 and WideResNet28-10) that are used in both the single-step (Noise-Fast Gradient Sign Method, N-FGSM) and multi-step (Projected Gradient Descent, PGD-10) adversarial training, we show that models trained within the BB framework consistently have higher adversarial accuracy across various adversarial settings, notably achieving over a 13% improvement on the SVHN dataset with an attack radius of 8/255 compared to the N-FGSM baseline model. Furthermore, experimental analysis of the efficiency of both the proposed initial perturbation method and sample selection strategies validates our insights. Finally, we show that our framework is cost-effective in terms of computational resources, even with a relatively large value of $m$.
Entity-centered Cross-document Relation Extraction
Oct 29, 2022



Relation Extraction (RE) is a fundamental task of information extraction, which has attracted a large amount of research attention. Previous studies focus on extracting the relations within a sentence or document, while currently researchers begin to explore cross-document RE. However, current cross-document RE methods directly utilize text snippets surrounding target entities in multiple given documents, which brings considerable noisy and non-relevant sentences. Moreover, they utilize all the text paths in a document bag in a coarse-grained way, without considering the connections between these text paths.In this paper, we aim to address both of these shortages and push the state-of-the-art for cross-document RE. First, we focus on input construction for our RE model and propose an entity-based document-context filter to retain useful information in the given documents by using the bridge entities in the text paths. Second, we propose a cross-document RE model based on cross-path entity relation attention, which allow the entity relations across text paths to interact with each other. We compare our cross-document RE method with the state-of-the-art methods in the dataset CodRED. Our method outperforms them by at least 10% in F1, thus demonstrating its effectiveness.
CSSAM:Code Search via Attention Matching of Code Semantics and Structures
Aug 08, 2022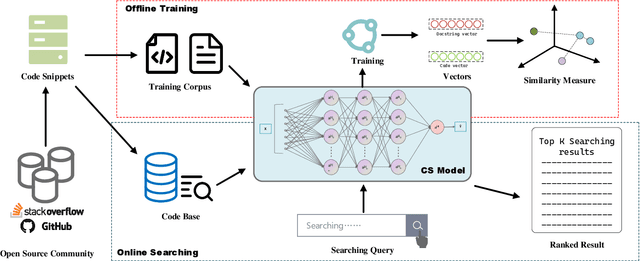
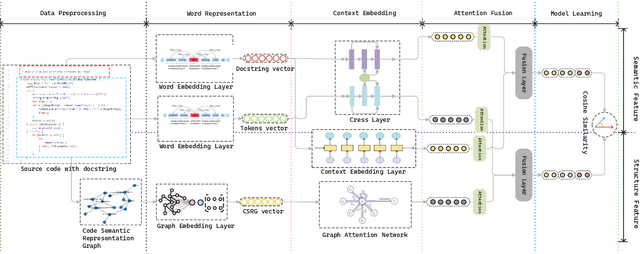

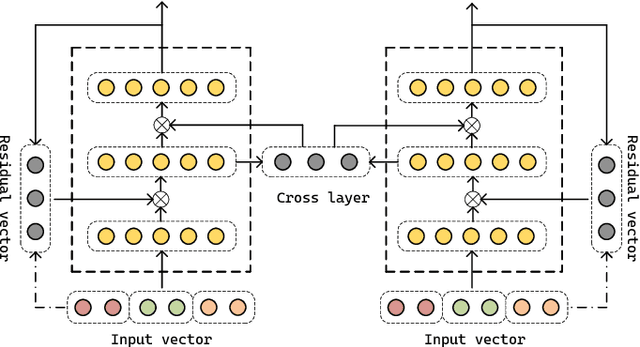
Despite the continuous efforts in improving both the effectiveness and efficiency of code search, two issues remained unsolved. First, programming languages have inherent strong structural linkages, and feature mining of code as text form would omit the structural information contained inside it. Second, there is a potential semantic relationship between code and query, it is challenging to align code and text across sequences so that vectors are spatially consistent during similarity matching. To tackle both issues, in this paper, a code search model named CSSAM (Code Semantics and Structures Attention Matching) is proposed. By introducing semantic and structural matching mechanisms, CSSAM effectively extracts and fuses multidimensional code features. Specifically, the cross and residual layer was developed to facilitate high-latitude spatial alignment of code and query at the token level. By leveraging the residual interaction, a matching module is designed to preserve more code semantics and descriptive features, that enhances the adhesion between the code and its corresponding query text. Besides, to improve the model's comprehension of the code's inherent structure, a code representation structure named CSRG (Code Semantic Representation Graph) is proposed for jointly representing abstract syntax tree nodes and the data flow of the codes. According to the experimental results on two publicly available datasets containing 540k and 330k code segments, CSSAM significantly outperforms the baselines in terms of achieving the highest SR@1/5/10, MRR, and NDCG@50 on both datasets respectively. Moreover, the ablation study is conducted to quantitatively measure the impact of each key component of CSSAM on the efficiency and effectiveness of code search, which offers the insights into the improvement of advanced code search solutions.