 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Animation Video Interpolation in the Wild
Apr 06, 2021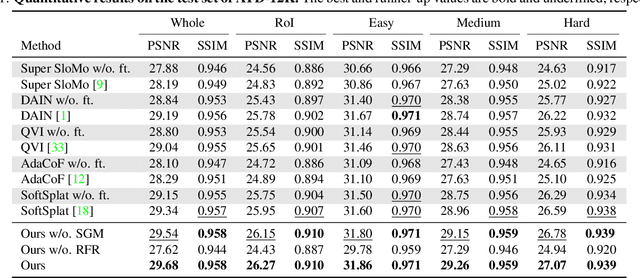

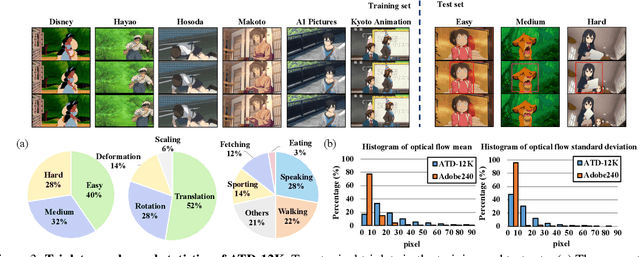
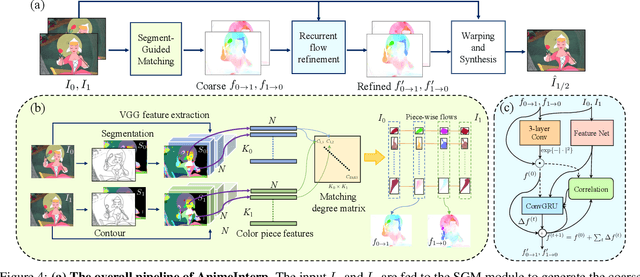
In the animation industry, cartoon videos are usually produced at low frame rate since hand drawing of such frames is costly and time-consuming. Therefore, it is desirable to develop computational models that can automatically interpolate the in-between animation frames. However, existing video interpolation methods fail to produce satisfying results on animation data. Compared to natural videos, animation videos possess two unique characteristics that make frame interpolation difficult: 1) cartoons comprise lines and smooth color pieces. The smooth areas lack textures and make it difficult to estimate accurate motions on animation videos. 2) cartoons express stories via exaggeration. Some of the motions are non-linear and extremely large. In this work, we formally define and study the animation video interpolation problem for the first time. To address the aforementioned challenges, we propose an effective framework, AnimeInterp, with two dedicated modules in a coarse-to-fine manner. Specifically, 1) Segment-Guided Matching resolves the "lack of textures" challenge by exploiting global matching among color pieces that are piece-wise coherent. 2) Recurrent Flow Refinement resolves the "non-linear and extremely large motion" challenge by recurrent predictions using a transformer-like architecture. To facilitate comprehensive training and evaluations, we build a large-scale animation triplet dataset, ATD-12K, which comprises 12,000 triplets with rich annotations. Extensive experiments demonstrate that our approach outperforms existing state-of-the-art interpolation methods for animation videos. Notably, AnimeInterp shows favorable perceptual quality and robustness for animation scenarios in the wild. The proposed dataset and code are available at https://github.com/lisiyao21/AnimeInterp/.
Efficient Regional Memory Network for Video Object Segmentation
Mar 24, 2021
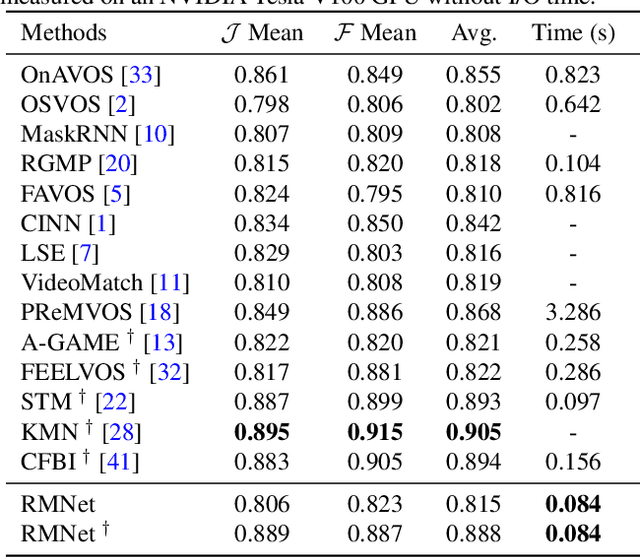
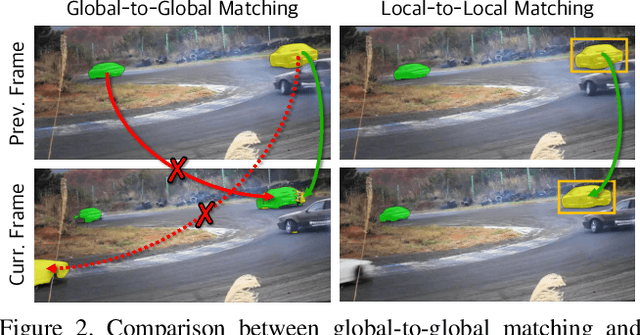
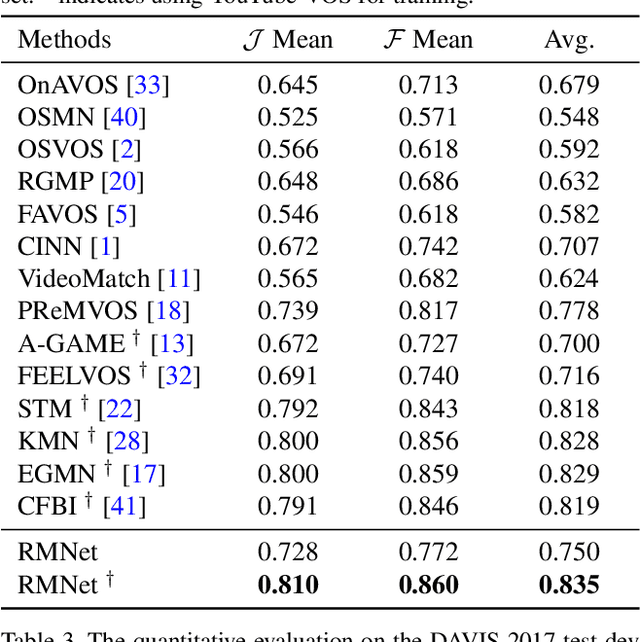
Recently, several Space-Time Memory based networks have shown that the object cues (e.g. video frames as well as the segmented object masks) from the past frames are useful for segmenting objects in the current frame. However, these methods exploit the information from the memory by global-to-global matching between the current and past frames, which lead to mismatching to similar objects and high computational complexity. To address these problems, we propose a novel local-to-local matching solution for semi-supervised VOS, namely Regional Memory Network (RMNet). In RMNet, the precise regional memory is constructed by memorizing local regions where the target objects appear in the past frames. For the current query frame, the query regions are tracked and predicted based on the optical flow estimated from the previous frame. The proposed local-to-local matching effectively alleviates the ambiguity of similar objects in both memory and query frames, which allows the information to be passed from the regional memory to the query region efficiently and effectively. Experimental results indicate that the proposed RMNet performs favorably against state-of-the-art methods on the DAVIS and YouTube-VOS datasets.
Learning N:M Fine-grained Structured Sparse Neural Networks From Scratch
Feb 08, 2021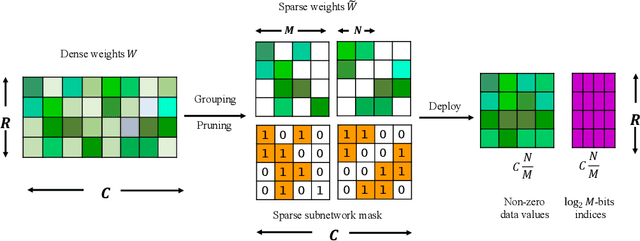
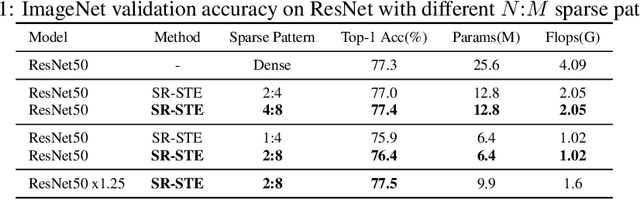
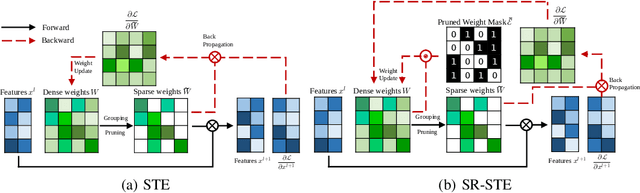
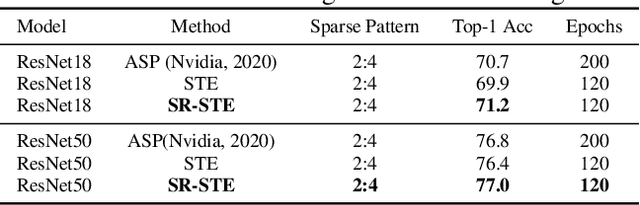
Sparsity in Deep Neural Networks (DNNs) has been widely studied to compress and accelerate the models on resource-constrained environments. It can be generally categorized into unstructured fine-grained sparsity that zeroes out multiple individual weights distributed across the neural network, and structured coarse-grained sparsity which prunes blocks of sub-networks of a neural network. Fine-grained sparsity can achieve a high compression ratio but is not hardware friendly and hence receives limited speed gains. On the other hand, coarse-grained sparsity cannot concurrently achieve both apparent acceleration on modern GPUs and decent performance. In this paper, we are the first to study training from scratch an N:M fine-grained structured sparse network, which can maintain the advantages of both unstructured fine-grained sparsity and structured coarse-grained sparsity simultaneously on specifically designed GPUs. Specifically, a 2:4 sparse network could achieve 2x speed-up without performance drop on Nvidia A100 GPUs. Furthermore, we propose a novel and effective ingredient, sparse-refined straight-through estimator (SR-STE), to alleviate the negative influence of the approximated gradients computed by vanilla STE during optimization. We also define a metric, Sparse Architecture Divergence (SAD), to measure the sparse network's topology change during the training process. Finally, We justify SR-STE's advantages with SAD and demonstrate the effectiveness of SR-STE by performing comprehensive experiments on various tasks. Source codes and models are available at https://github.com/NM-sparsity/NM-sparsity.
Exploiting Raw Images for Real-Scene Super-Resolution
Feb 02, 2021
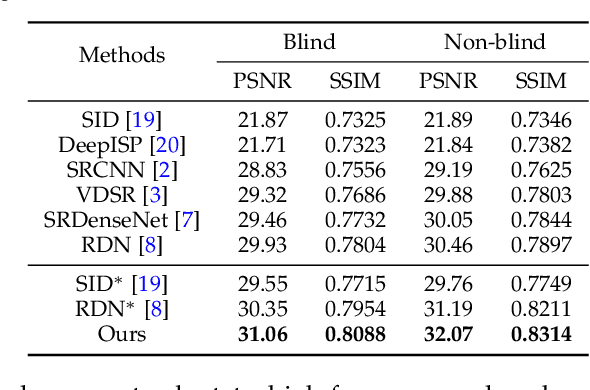
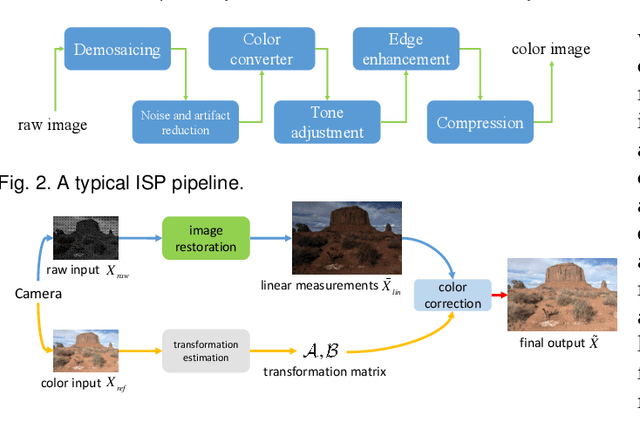
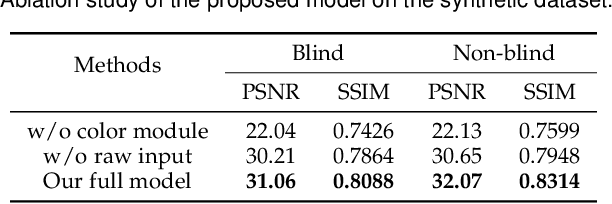
Super-resolution is a fundamental problem in computer vision which aims to overcome the spatial limitation of camera sensors. While significant progress has been made in single image super-resolution, most algorithms only perform well on synthetic data, which limits their applications in real scenarios. In this paper, we study the problem of real-scene single image super-resolution to bridge the gap between synthetic data and real captured images. We focus on two issues of existing super-resolution algorithms: lack of realistic training data and insufficient utilization of visual information obtained from cameras. To address the first issue, we propose a method to generate more realistic training data by mimicking the imaging process of digital cameras. For the second issue, we develop a two-branch convolutional neural network to exploit the radiance information originally-recorded in raw images. In addition, we propose a dense channel-attention block for better image restoration as well as a learning-based guided filter network for effective color correction. Our model is able to generalize to different cameras without deliberately training on images from specific camera types. Extensive experiments demonstrate that the proposed algorithm can recover fine details and clear structures, and achieve high-quality results for single image super-resolution in real scenes.
* A larger version with higher-resolution figures is available at: https://sites.google.com/view/xiangyuxu. arXiv admin note: text overlap with arXiv:1905.12156
Semi-synthesis: A fast way to produce effective datasets for stereo matching
Jan 26, 2021
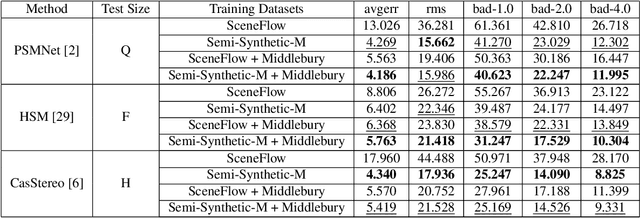

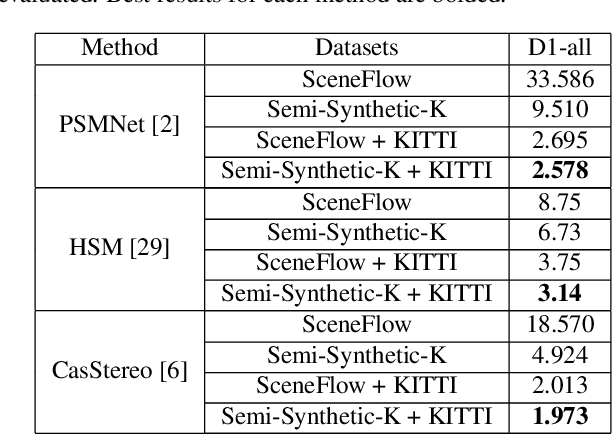
Stereo matching is an important problem in computer vision which has drawn tremendous research attention for decades. Recent years, data-driven methods with convolutional neural networks (CNNs) are continuously pushing stereo matching to new heights. However, data-driven methods require large amount of training data, which is not an easy task for real stereo data due to the annotation difficulties of per-pixel ground-truth disparity. Though synthetic dataset is proposed to fill the gaps of large data demand, the fine-tuning on real dataset is still needed due to the domain variances between synthetic data and real data. In this paper, we found that in synthetic datasets, close-to-real-scene texture rendering is a key factor to boost up stereo matching performance, while close-to-real-scene 3D modeling is less important. We then propose semi-synthetic, an effective and fast way to synthesize large amount of data with close-to-real-scene texture to minimize the gap between synthetic data and real data. Extensive experiments demonstrate that models trained with our proposed semi-synthetic datasets achieve significantly better performance than with general synthetic datasets, especially on real data benchmarks with limited training data. With further fine-tuning on the real dataset, we also achieve SOTA performance on Middlebury and competitive results on KITTI and ETH3D datasets.
Learning Spatial and Spatio-Temporal Pixel Aggregations for Image and Video Denoising
Jan 26, 2021
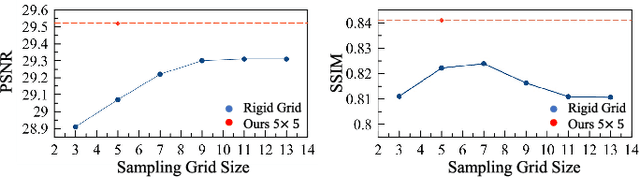
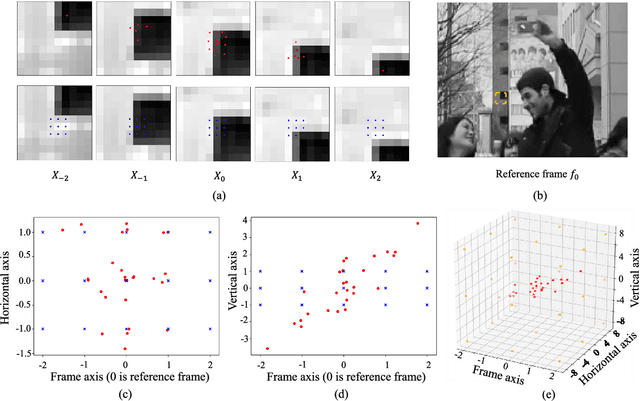
Existing denoising methods typically restore clear results by aggregating pixels from the noisy input. Instead of relying on hand-crafted aggregation schemes, we propose to explicitly learn this process with deep neural networks. We present a spatial pixel aggregation network and learn the pixel sampling and averaging strategies for image denoising. The proposed model naturally adapts to image structures and can effectively improve the denoised results. Furthermore, we develop a spatio-temporal pixel aggregation network for video denoising to efficiently sample pixels across the spatio-temporal space. Our method is able to solve the misalignment issues caused by large motion in dynamic scenes. In addition, we introduce a new regularization term for effectively training the proposed video denoising model. We present extensive analysis of the proposed method and demonstrate that our model performs favorably against the state-of-the-art image and video denoising approaches on both synthetic and real-world data.
* Project page: https://sites.google.com/view/xiangyuxu/denoise_stpan. arXiv admin note: substantial text overlap with arXiv:1904.06903
Enhanced Quadratic Video Interpolation
Sep 10, 2020
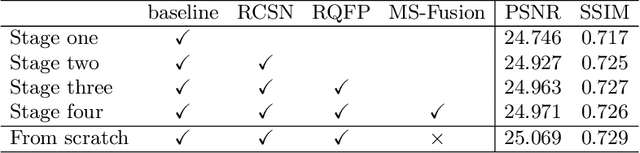
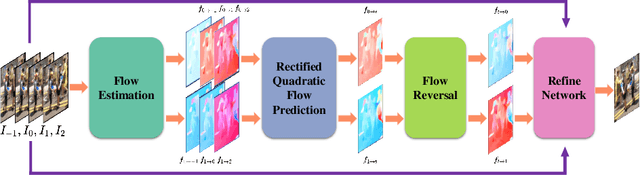
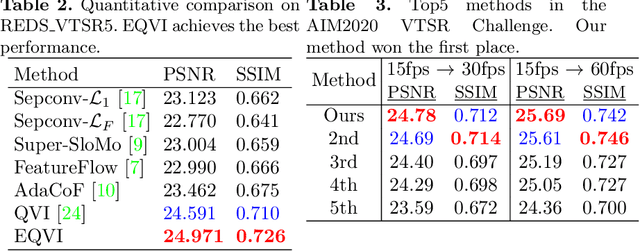
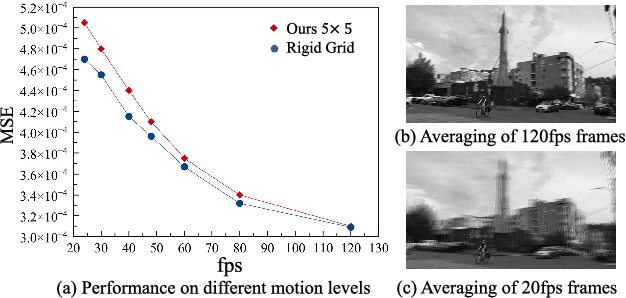
With the prosperity of digital video industry, video frame interpolation has arisen continuous attention in computer vision community and become a new upsurge in industry. Many learning-based methods have been proposed and achieved progressive results. Among them, a recent algorithm named quadratic video interpolation (QVI) achieves appealing performance. It exploits higher-order motion information (e.g. acceleration) and successfully models the estimation of interpolated flow. However, its produced intermediate frames still contain some unsatisfactory ghosting, artifacts and inaccurate motion, especially when large and complex motion occurs. In this work, we further improve the performance of QVI from three facets and propose an enhanced quadratic video interpolation (EQVI) model. In particular, we adopt a rectified quadratic flow prediction (RQFP) formulation with least squares method to estimate the motion more accurately. Complementary with image pixel-level blending, we introduce a residual contextual synthesis network (RCSN) to employ contextual information in high-dimensional feature space, which could help the model handle more complicated scenes and motion patterns. Moreover, to further boost the performance, we devise a novel multi-scale fusion network (MS-Fusion) which can be regarded as a learnable augmentation process. The proposed EQVI model won the first place in the AIM2020 Video Temporal Super-Resolution Challenge.
Towards Geometry Guided Neural Relighting with Flash Photography
Aug 12, 2020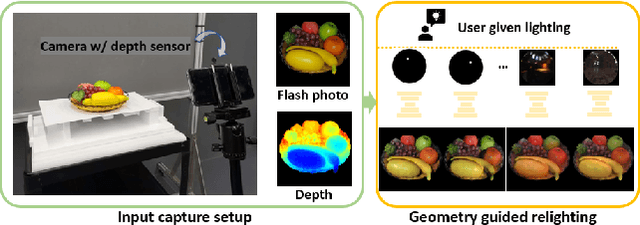

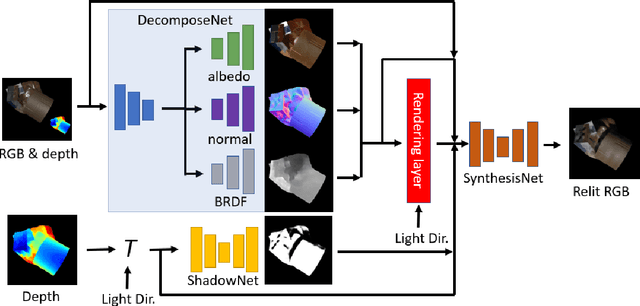
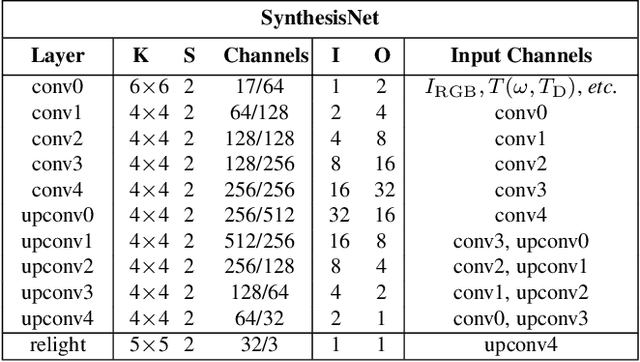
Previous image based relighting methods require capturing multiple images to acquire high frequency lighting effect under different lighting conditions, which needs nontrivial effort and may be unrealistic in certain practical use scenarios. While such approaches rely entirely on cleverly sampling the color images under different lighting conditions, little has been done to utilize geometric information that crucially influences the high-frequency features in the images, such as glossy highlight and cast shadow. We therefore propose a framework for image relighting from a single flash photograph with its corresponding depth map using deep learning. By incorporating the depth map, our approach is able to extrapolate realistic high-frequency effects under novel lighting via geometry guided image decomposition from the flashlight image, and predict the cast shadow map from the shadow-encoding transformed depth map. Moreover, the single-image based setup greatly simplifies the data capture process. We experimentally validate the advantage of our geometry guided approach over state-of-the-art image-based approaches in intrinsic image decomposition and image relighting, and also demonstrate our performance on real mobile phone photo examples.
Pix2Vox++: Multi-scale Context-aware 3D Object Reconstruction from Single and Multiple Images
Jul 07, 2020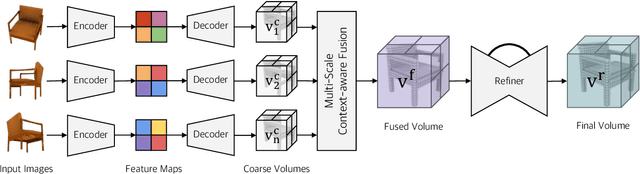
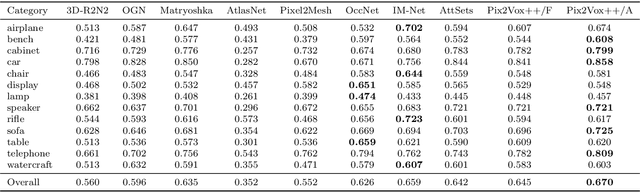
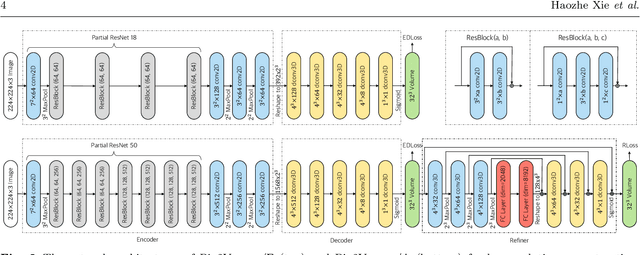
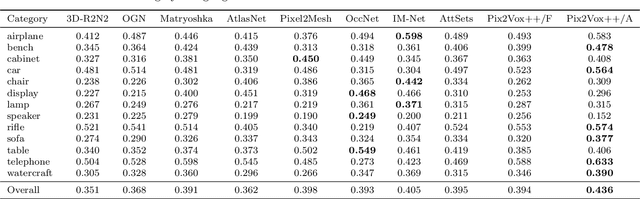
Recovering the 3D shape of an object from single or multiple images with deep neural networks has been attracting increasing attention in the past few years. Mainstream works (e.g. 3D-R2N2) use recurrent neural networks (RNNs) to sequentially fuse feature maps of input images. However, RNN-based approaches are unable to produce consistent reconstruction results when given the same input images with different orders. Moreover, RNNs may forget important features from early input images due to long-term memory loss. To address these issues, we propose a novel framework for single-view and multi-view 3D object reconstruction, named Pix2Vox++. By using a well-designed encoder-decoder, it generates a coarse 3D volume from each input image. A multi-scale context-aware fusion module is then introduced to adaptively select high-quality reconstructions for different parts from all coarse 3D volumes to obtain a fused 3D volume. To further correct the wrongly recovered parts in the fused 3D volume, a refiner is adopted to generate the final output. Experimental results on the ShapeNet, Pix3D, and Things3D benchmarks show that Pix2Vox++ performs favorably against state-of-the-art methods in terms of both accuracy and efficiency.
GRNet: Gridding Residual Network for Dense Point Cloud Completion
Jul 03, 2020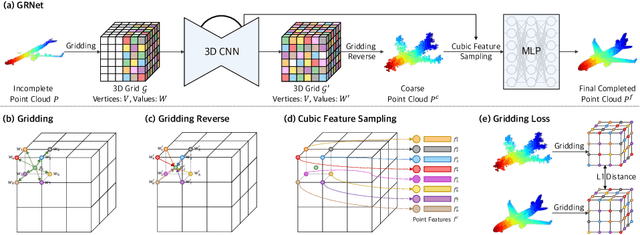
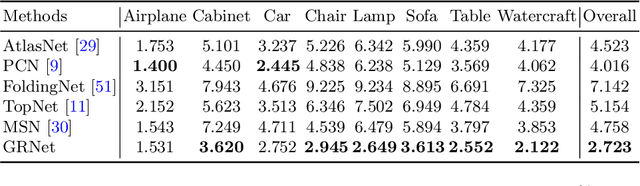
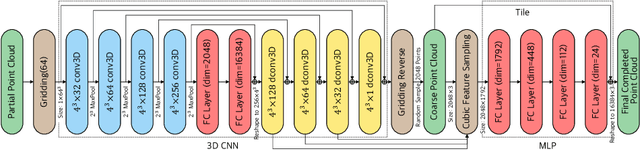
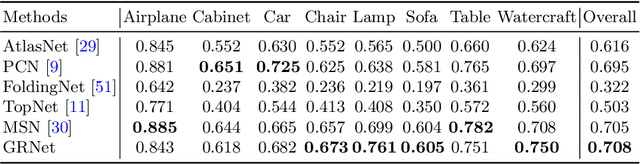
Estimating the complete 3D point cloud from an incomplete one is a key problem in many vision and robotics applications. Mainstream methods (e.g., PCN and TopNet) use Multi-layer Perceptrons (MLPs) to directly process point clouds, which may cause the loss of details because the structural and context of point clouds are not fully considered. To solve this problem, we introduce 3D grids as intermediate representations to regularize unordered point clouds. We therefore propose a novel Gridding Residual Network (GRNet) for point cloud completion. In particular, we devise two novel differentiable layers, named Gridding and Gridding Reverse, to convert between point clouds and 3D grids without losing structural information. We also present the differentiable Cubic Feature Sampling layer to extract features of neighboring points, which preserves context information. In addition, we design a new loss function, namely Gridding Loss, to calculate the L1 distance between the 3D grids of the predicted and ground truth point clouds, which is helpful to recover details. Experimental results indicate that the proposed GRNet performs favorably against state-of-the-art methods on the ShapeNet, Completion3D, and KITTI benchmarks.