 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalM$2$: An Extremely Lightweight Saliency Mamba Model for Real-Time Cognitive Awareness of Driver Attention
Feb 22, 2025



Driver attention recognition in driving scenarios is a popular direction in traffic scene perception technology. It aims to understand human driver attention to focus on specific targets/objects in the driving scene. However, traffic scenes contain not only a large amount of visual information but also semantic information related to driving tasks. Existing methods lack attention to the actual semantic information present in driving scenes. Additionally, the traffic scene is a complex and dynamic process that requires constant attention to objects related to the current driving task. Existing models, influenced by their foundational frameworks, tend to have large parameter counts and complex structures. Therefore, this paper proposes a real-time saliency Mamba network based on the latest Mamba framework. As shown in Figure 1, our model uses very few parameters (0.08M, only 0.09~11.16% of other models), while maintaining SOTA performance or achieving over 98% of the SOTA model's performance.
Learning Based MPC for Autonomous Driving Using a Low Dimensional Residual Model
Dec 05, 2024



In this paper, a learning based Model Predictive Control (MPC) using a low dimensional residual model is proposed for autonomous driving. One of the critical challenge in autonomous driving is the complexity of vehicle dynamics, which impedes the formulation of accurate vehicle model. Inaccurate vehicle model can significantly impact the performance of MPC controller. To address this issue, this paper decomposes the nominal vehicle model into invariable and variable elements. The accuracy of invariable component is ensured by calibration, while the deviations in the variable elements are learned by a low-dimensional residual model. The features of residual model are selected as the physical variables most correlated with nominal model errors. Physical constraints among these features are formulated to explicitly define the valid region within the feature space. The formulated model and constraints are incorporated into the MPC framework and validated through both simulation and real vehicle experiments. The results indicate that the proposed method significantly enhances the model accuracy and controller performance.
A Data-Driven Modeling and Motion Control of Heavy-Load Hydraulic Manipulators via Reversible Transformation
Nov 21, 2024



This work proposes a data-driven modeling and the corresponding hybrid motion control framework for unmanned and automated operation of industrial heavy-load hydraulic manipulator. Rather than the direct use of a neural network black box, we construct a reversible nonlinear model by using multilayer perceptron to approximate dynamics in the physical integrator chain system after reversible transformations. The reversible nonlinear model is trained offline using supervised learning techniques, and the data are obtained from simulations or experiments. Entire hybrid motion control framework consists of the model inversion controller that compensates for the nonlinear dynamics and proportional-derivative controller that enhances the robustness. The stability is proved with Lyapunov theory. Co-simulation and Experiments show the effectiveness of proposed modeling and hybrid control framework. With a commercial 39-ton class hydraulic excavator for motion control tasks, the root mean square error of trajectory tracking error decreases by at least 50\% compared to traditional control methods. In addition, by analyzing the system model, the proposed framework can be rapidly applied to different control plants.
PDC & DM-SFT: A Road for LLM SQL Bug-Fix Enhancing
Nov 11, 2024



Code Large Language Models (Code LLMs), such as Code llama and DeepSeek-Coder, have demonstrated exceptional performance in the code generation tasks. However, most existing models focus on the abilities of generating correct code, but often struggle with bug repair. We introduce a suit of methods to enhance LLM's SQL bug-fixing abilities. The methods are mainly consisted of two parts: A Progressive Dataset Construction (PDC) from scratch and Dynamic Mask Supervised Fine-tuning (DM-SFT). PDC proposes two data expansion methods from the perspectives of breadth first and depth first respectively. DM-SFT introduces an efficient bug-fixing supervised learning approach, which effectively reduce the total training steps and mitigate the "disorientation" in SQL code bug-fixing training. In our evaluation, the code LLM models trained with two methods have exceeds all current best performing model which size is much larger.
BF-Meta: Secure Blockchain-enhanced Privacy-preserving Federated Learning for Metaverse
Oct 29, 2024



The metaverse, emerging as a revolutionary platform for social and economic activities, provides various virtual services while posing security and privacy challenges. Wearable devices serve as bridges between the real world and the metaverse. To provide intelligent services without revealing users' privacy in the metaverse, leveraging federated learning (FL) to train models on local wearable devices is a promising solution. However, centralized model aggregation in traditional FL may suffer from external attacks, resulting in a single point of failure. Furthermore, the absence of incentive mechanisms may weaken users' participation during FL training, leading to degraded performance of the trained model and reduced quality of intelligent services. In this paper, we propose BF-Meta, a secure blockchain-empowered FL framework with decentralized model aggregation, to mitigate the negative influence of malicious users and provide secure virtual services in the metaverse. In addition, we design an incentive mechanism to give feedback to users based on their behaviors. Experiments conducted on five datasets demonstrate the effectiveness and applicability of BF-Meta.
Ground-to-UAV 140 GHz channel measurement and modeling
Apr 03, 2024Unmanned Aerial Vehicle (UAV) assisted terahertz (THz) wireless communications have been expected to play a vital role in the next generation of wireless networks. UAVs can serve as either repeaters or data collectors within the communication link, thereby potentially augmenting the efficacy of communication systems. Despite their promise, the channel analysis and modeling specific to THz wireless channels leveraging UAVs remain under explored. This work delves into a ground-to-UAV channel at 140 GHz, with a specific focus on the influence of UAV hovering behavior on channel performance. Employing experimental measurements through an unmodulated channel setup and a geometry-based stochastic model (GBSM) that integrates three-dimensional positional coordinates and beamwidth, this work evaluates the impact of UAV dynamic movements and antenna orientation on channel performance. Our findings highlight the minimal impact of UAV orientation adjustments on channel performance and underscore the diminishing necessity for precise alignment between UAVs and ground stations as beamwidth increases.
Active Admittance Control with Iterative Learning for General-Purpose Contact-Rich Manipulation
Mar 25, 2024



Force interaction is inevitable when robots face multiple operation scenarios. How to make the robot competent in force control for generalized operations such as multi-tasks still remains a challenging problem. Aiming at the reproducibility of interaction tasks and the lack of a generalized force control framework for multi-task scenarios, this paper proposes a novel hybrid control framework based on active admittance control with iterative learning parameters-tunning mechanism. The method adopts admittance control as the underlying algorithm to ensure flexibility, and iterative learning as the high-level algorithm to regulate the parameters of the admittance model. The whole algorithm has flexibility and learning ability, which is capable of achieving the goal of excellent versatility. Four representative interactive robot manipulation tasks are chosen to investigate the consistency and generalisability of the proposed method. Experiments are designed to verify the effectiveness of the whole framework, and an average of 98.21% and 91.52% improvement of RMSE is obtained relative to the traditional admittance control as well as the model-free adaptive control, respectively.
SongDriver2: Real-time Emotion-based Music Arrangement with Soft Transition
May 14, 2023Real-time emotion-based music arrangement, which aims to transform a given music piece into another one that evokes specific emotional resonance with the user in real-time, holds significant application value in various scenarios, e.g., music therapy, video game soundtracks, and movie scores. However, balancing emotion real-time fit with soft emotion transition is a challenge due to the fine-grained and mutable nature of the target emotion. Existing studies mainly focus on achieving emotion real-time fit, while the issue of soft transition remains understudied, affecting the overall emotional coherence of the music. In this paper, we propose SongDriver2 to address this balance. Specifically, we first recognize the last timestep's music emotion and then fuse it with the current timestep's target input emotion. The fused emotion then serves as the guidance for SongDriver2 to generate the upcoming music based on the input melody data. To adjust music similarity and emotion real-time fit flexibly, we downsample the original melody and feed it into the generation model. Furthermore, we design four music theory features to leverage domain knowledge to enhance emotion information and employ semi-supervised learning to mitigate the subjective bias introduced by manual dataset annotation. According to the evaluation results, SongDriver2 surpasses the state-of-the-art methods in both objective and subjective metrics. These results demonstrate that SongDriver2 achieves real-time fit and soft transitions simultaneously, enhancing the coherence of the generated music.
Target Detection Framework for Lobster Eye X-Ray Telescopes with Machine Learning Algorithms
Dec 11, 2022Lobster eye telescopes are ideal monitors to detect X-ray transients, because they could observe celestial objects over a wide field of view in X-ray band. However, images obtained by lobster eye telescopes are modified by their unique point spread functions, making it hard to design a high efficiency target detection algorithm. In this paper, we integrate several machine learning algorithms to build a target detection framework for data obtained by lobster eye telescopes. Our framework would firstly generate two 2D images with different pixel scales according to positions of photons on the detector. Then an algorithm based on morphological operations and two neural networks would be used to detect candidates of celestial objects with different flux from these 2D images. At last, a random forest algorithm will be used to pick up final detection results from candidates obtained by previous steps. Tested with simulated data of the Wide-field X-ray Telescope onboard the Einstein Probe, our detection framework could achieve over 94% purity and over 90% completeness for targets with flux more than 3 mCrab (9.6 * 10-11 erg/cm2/s) and more than 94% purity and moderate completeness for targets with lower flux at acceptable time cost. The framework proposed in this paper could be used as references for data processing methods developed for other lobster eye X-ray telescopes.
SongDriver: Real-time Music Accompaniment Generation without Logical Latency nor Exposure Bias
Sep 13, 2022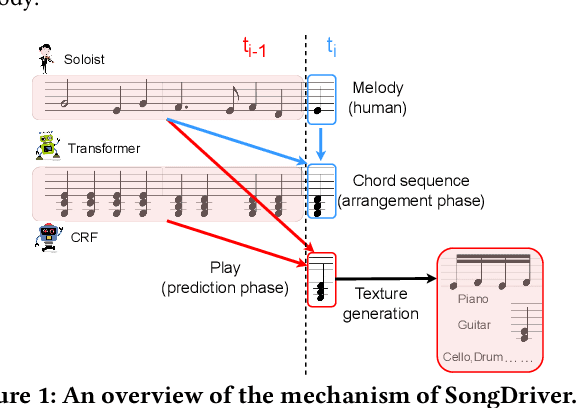
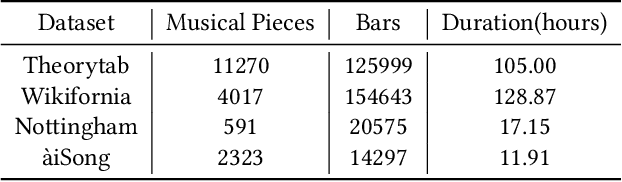
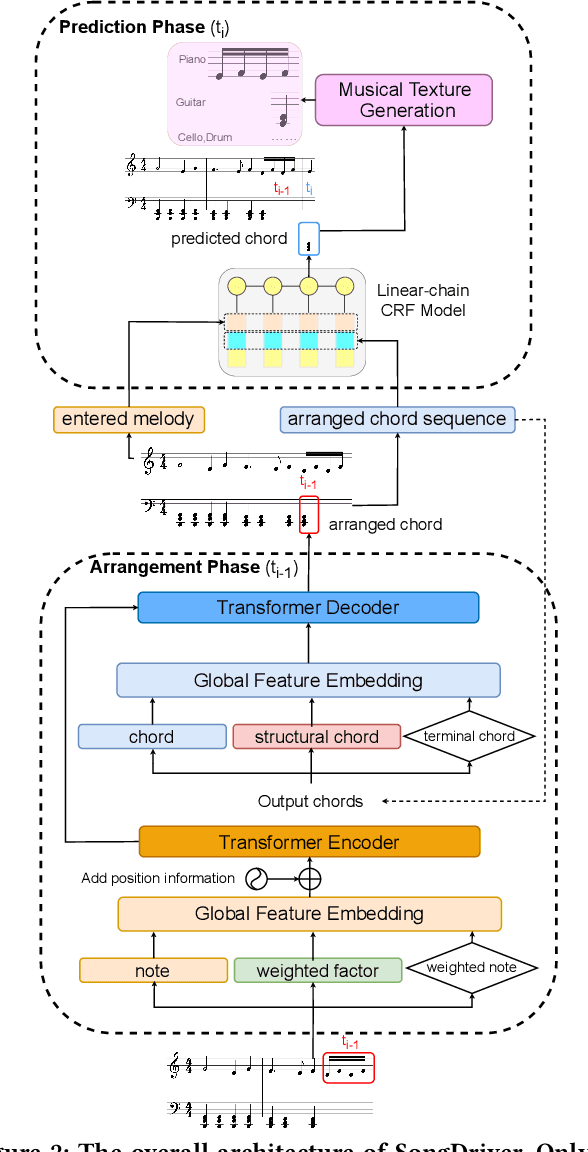
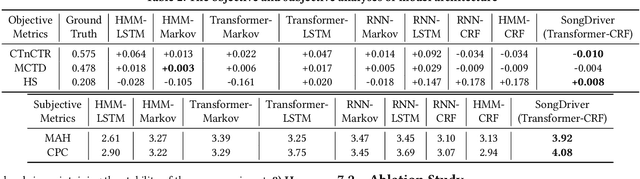
Real-time music accompaniment generation has a wide range of applications in the music industry, such as music education and live performances. However, automatic real-time music accompaniment generation is still understudied and often faces a trade-off between logical latency and exposure bias. In this paper, we propose SongDriver, a real-time music accompaniment generation system without logical latency nor exposure bias. Specifically, SongDriver divides one accompaniment generation task into two phases: 1) The arrangement phase, where a Transformer model first arranges chords for input melodies in real-time, and caches the chords for the next phase instead of playing them out. 2) The prediction phase, where a CRF model generates playable multi-track accompaniments for the coming melodies based on previously cached chords. With this two-phase strategy, SongDriver directly generates the accompaniment for the upcoming melody, achieving zero logical latency. Furthermore, when predicting chords for a timestep, SongDriver refers to the cached chords from the first phase rather than its previous predictions, which avoids the exposure bias problem. Since the input length is often constrained under real-time conditions, another potential problem is the loss of long-term sequential information. To make up for this disadvantage, we extract four musical features from a long-term music piece before the current time step as global information. In the experiment, we train SongDriver on some open-source datasets and an original \`aiSong Dataset built from Chinese-style modern pop music scores. The results show that SongDriver outperforms existing SOTA (state-of-the-art) models on both objective and subjective metrics, meanwhile significantly reducing the physical latency.