 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Prompt Tuning
May 24, 2022
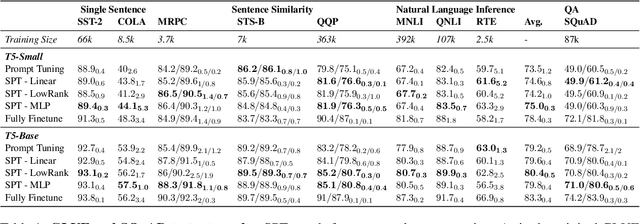

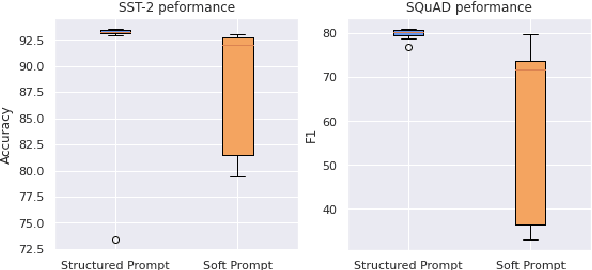
We propose structured prompt tuning, a simple and effective method to improve prompt tuning. Instead of prepending a sequence of tunable embeddings to the input, we generate the soft prompt embeddings through a hypernetwork. Our approach subsumes the standard prompt tuning, allows more flexibility in model design and can be applied to both single-task and multi-task training settings. Empirically, structured prompt tuning shows a gain of +1.2$~1.5 points on the GLUE benchmark and is less sensitive to the change of learning rate, compared to standard prompt tuning.
On Continual Model Refinement in Out-of-Distribution Data Streams
May 04, 2022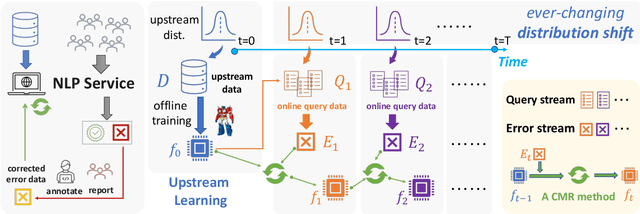
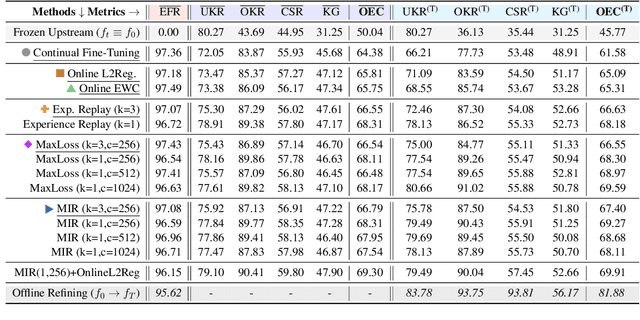
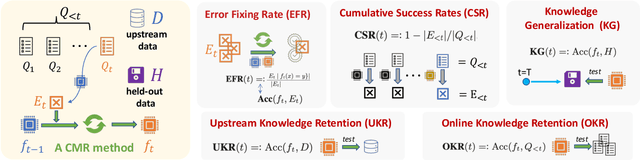
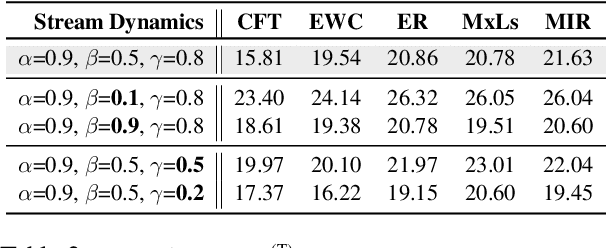
Real-world natural language processing (NLP) models need to be continually updated to fix the prediction errors in out-of-distribution (OOD) data streams while overcoming catastrophic forgetting. However, existing continual learning (CL) problem setups cannot cover such a realistic and complex scenario. In response to this, we propose a new CL problem formulation dubbed continual model refinement (CMR). Compared to prior CL settings, CMR is more practical and introduces unique challenges (boundary-agnostic and non-stationary distribution shift, diverse mixtures of multiple OOD data clusters, error-centric streams, etc.). We extend several existing CL approaches to the CMR setting and evaluate them extensively. For benchmarking and analysis, we propose a general sampling algorithm to obtain dynamic OOD data streams with controllable non-stationarity, as well as a suite of metrics measuring various aspects of online performance. Our experiments and detailed analysis reveal the promise and challenges of the CMR problem, supporting that studying CMR in dynamic OOD streams can benefit the longevity of deployed NLP models in production.
Autoregressive Search Engines: Generating Substrings as Document Identifiers
Apr 22, 2022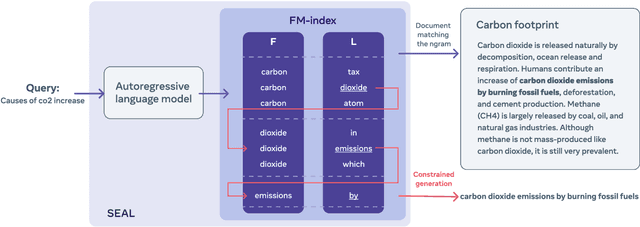
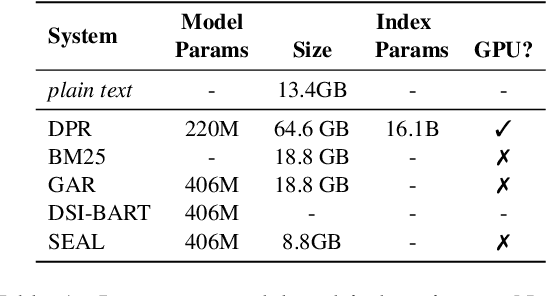
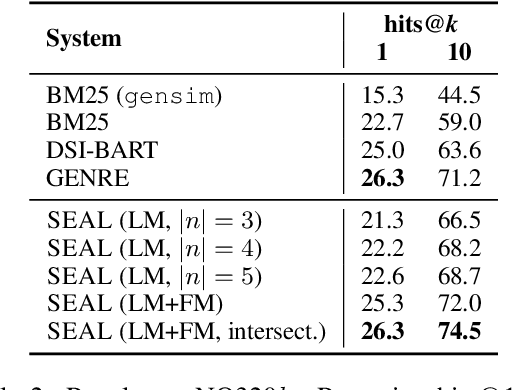
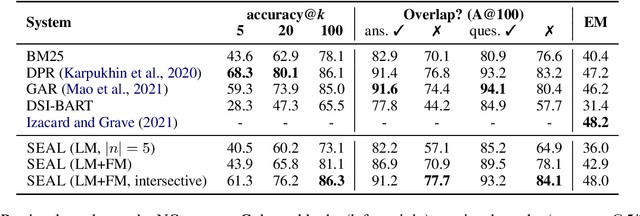
Knowledge-intensive language tasks require NLP systems to both provide the correct answer and retrieve supporting evidence for it in a given corpus. Autoregressive language models are emerging as the de-facto standard for generating answers, with newer and more powerful systems emerging at an astonishing pace. In this paper we argue that all this (and future) progress can be directly applied to the retrieval problem with minimal intervention to the models' architecture. Previous work has explored ways to partition the search space into hierarchical structures and retrieve documents by autoregressively generating their unique identifier. In this work we propose an alternative that doesn't force any structure in the search space: using all ngrams in a passage as its possible identifiers. This setup allows us to use an autoregressive model to generate and score distinctive ngrams, that are then mapped to full passages through an efficient data structure. Empirically, we show this not only outperforms prior autoregressive approaches but also leads to an average improvement of at least 10 points over more established retrieval solutions for passage-level retrieval on the KILT benchmark, establishing new state-of-the-art downstream performance on some datasets, while using a considerably lighter memory footprint than competing systems. Code and pre-trained models at https://github.com/facebookresearch/SEAL.
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
Apr 21, 2022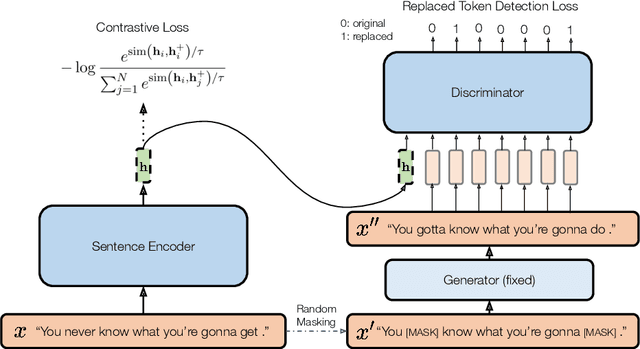
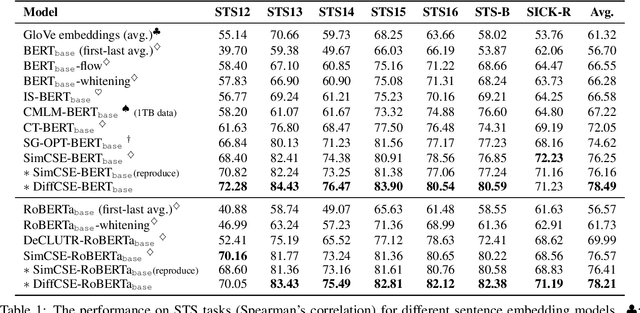
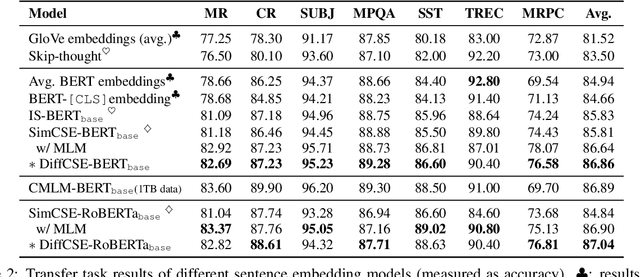
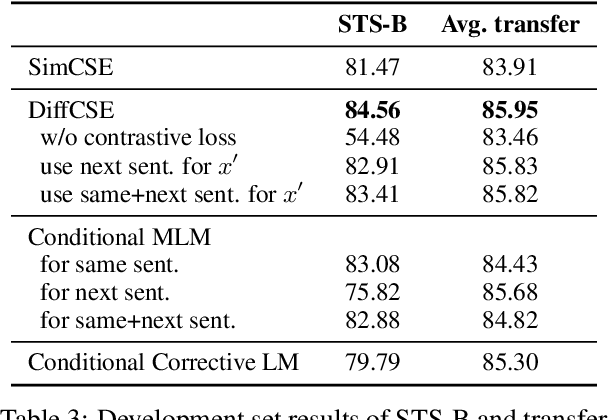
We propose DiffCSE, an unsupervised contrastive learning framework for learning sentence embeddings. DiffCSE learns sentence embeddings that are sensitive to the difference between the original sentence and an edited sentence, where the edited sentence is obtained by stochastically masking out the original sentence and then sampling from a masked language model. We show that DiffSCE is an instance of equivariant contrastive learning (Dangovski et al., 2021), which generalizes contrastive learning and learns representations that are insensitive to certain types of augmentations and sensitive to other "harmful" types of augmentations. Our experiments show that DiffCSE achieves state-of-the-art results among unsupervised sentence representation learning methods, outperforming unsupervised SimCSE by 2.3 absolute points on semantic textual similarity tasks.
InCoder: A Generative Model for Code Infilling and Synthesis
Apr 17, 2022

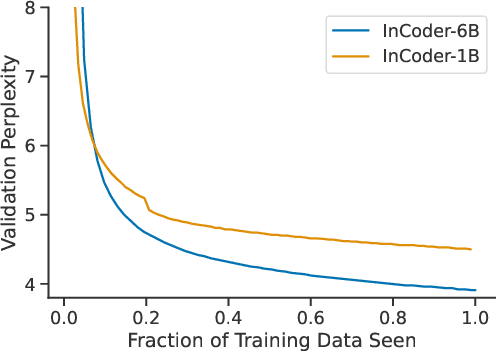
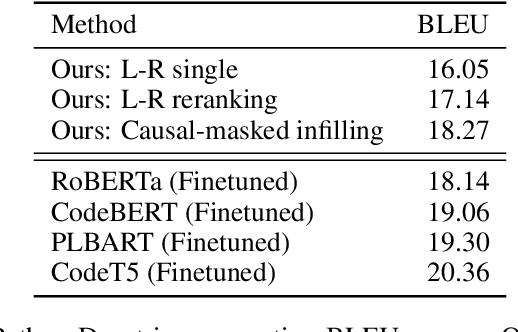
Code is seldom written in a single left-to-right pass and is instead repeatedly edited and refined. We introduce InCoder, a unified generative model that can perform program synthesis (via left-to-right generation) as well as editing (via infilling). InCoder is trained to generate code files from a large corpus of permissively licensed code, where regions of code have been randomly masked and moved to the end of each file, allowing code infilling with bidirectional context. Our model is the first generative model that is able to directly perform zero-shot code infilling, which we evaluate on challenging tasks such as type inference, comment generation, and variable re-naming. We find that the ability to condition on bidirectional context substantially improves performance on these tasks, while still performing comparably on standard program synthesis benchmarks in comparison to left-to-right only models pretrained at similar scale. The InCoder models and code are publicly released. https://sites.google.com/view/incoder-code-models
Improving Passage Retrieval with Zero-Shot Question Generation
Apr 15, 2022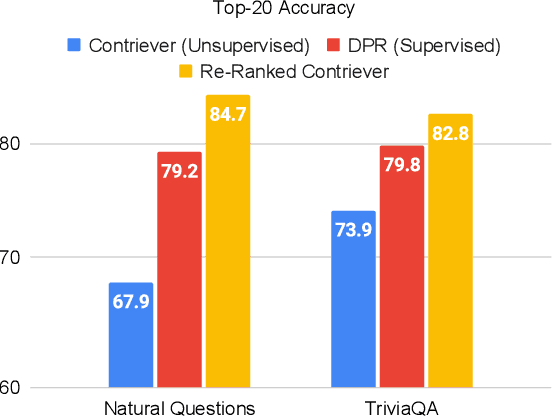
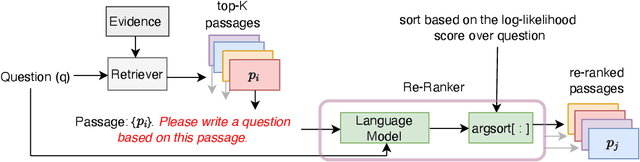
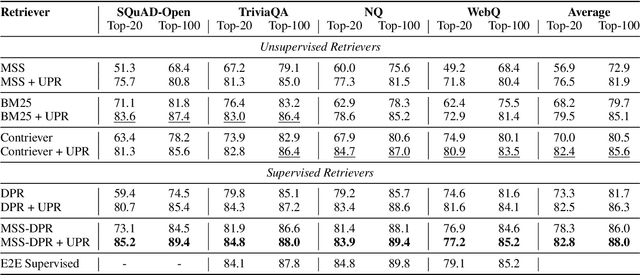
We propose a simple and effective re-ranking method for improving passage retrieval in open question answering. The re-ranker re-scores retrieved passages with a zero-shot question generation model, which uses a pre-trained language model to compute the probability of the input question conditioned on a retrieved passage. This approach can be applied on top of any retrieval method (e.g. neural or keyword-based), does not require any domain- or task-specific training (and therefore is expected to generalize better to data distribution shifts), and provides rich cross-attention between query and passage (i.e. it must explain every token in the question). When evaluated on a number of open-domain retrieval datasets, our re-ranker improves strong unsupervised retrieval models by 6%-18% absolute and strong supervised models by up to 12% in terms of top-20 passage retrieval accuracy. We also obtain new state-of-the-art results on full open-domain question answering by simply adding the new re-ranker to existing models with no further changes.
The Web Is Your Oyster -- Knowledge-Intensive NLP against a Very Large Web Corpus
Dec 18, 2021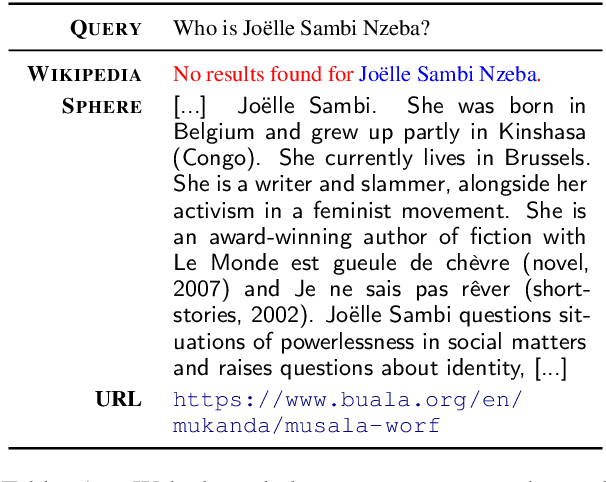
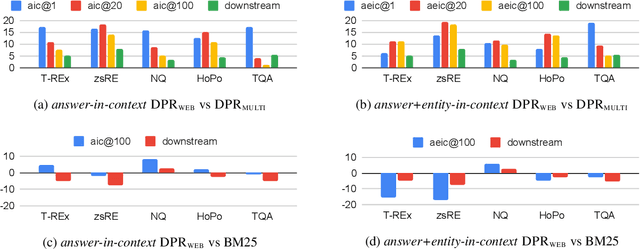
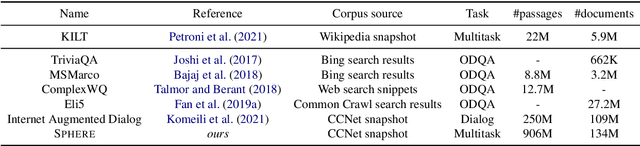
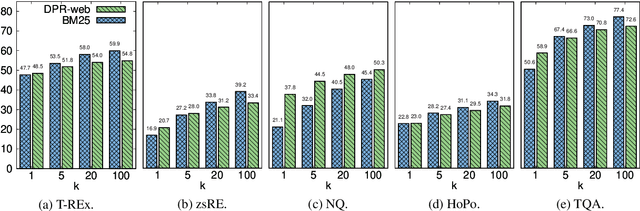
In order to address the increasing demands of real-world applications, the research for knowledge-intensive NLP (KI-NLP) should advance by capturing the challenges of a truly open-domain environment: web scale knowledge, lack of structure, inconsistent quality, and noise. To this end, we propose a new setup for evaluating existing KI-NLP tasks in which we generalize the background corpus to a universal web snapshot. We repurpose KILT, a standard KI-NLP benchmark initially developed for Wikipedia, and ask systems to use a subset of CCNet - the Sphere corpus - as a knowledge source. In contrast to Wikipedia, Sphere is orders of magnitude larger and better reflects the full diversity of knowledge on the Internet. We find that despite potential gaps of coverage, challenges of scale, lack of structure and lower quality, retrieval from Sphere enables a state-of-the-art retrieve-and-read system to match and even outperform Wikipedia-based models on several KILT tasks - even if we aggressively filter content that looks like Wikipedia. We also observe that while a single dense passage index over Wikipedia can outperform a sparse BM25 version, on Sphere this is not yet possible. To facilitate further research into this area, and minimise the community's reliance on proprietary black box search engines, we will share our indices, evaluation metrics and infrastructure.
Boosted Dense Retriever
Dec 14, 2021
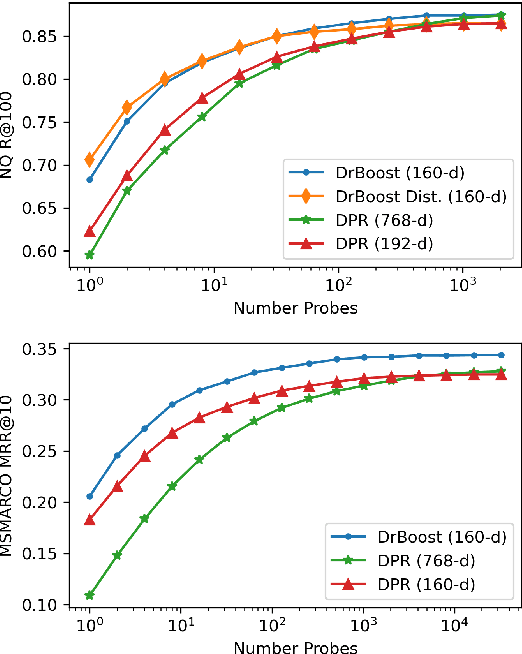

We propose DrBoost, a dense retrieval ensemble inspired by boosting. DrBoost is trained in stages: each component model is learned sequentially and specialized by focusing only on retrieval mistakes made by the current ensemble. The final representation is the concatenation of the output vectors of all the component models, making it a drop-in replacement for standard dense retrievers at test time. DrBoost enjoys several advantages compared to standard dense retrieval models. It produces representations which are 4x more compact, while delivering comparable retrieval results. It also performs surprisingly well under approximate search with coarse quantization, reducing latency and bandwidth needs by another 4x. In practice, this can make the difference between serving indices from disk versus from memory, paving the way for much cheaper deployments.
Simple Local Attentions Remain Competitive for Long-Context Tasks
Dec 14, 2021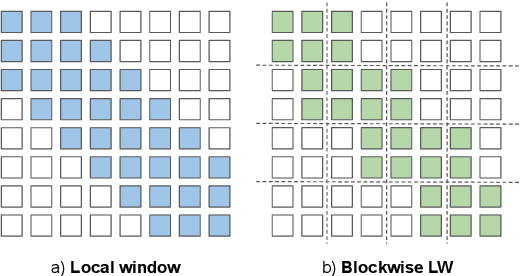
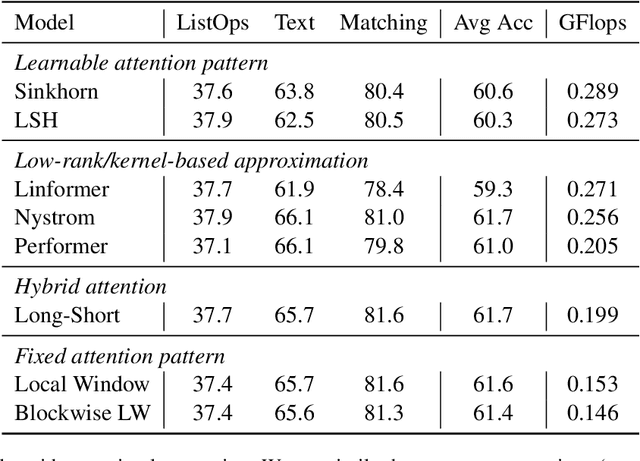
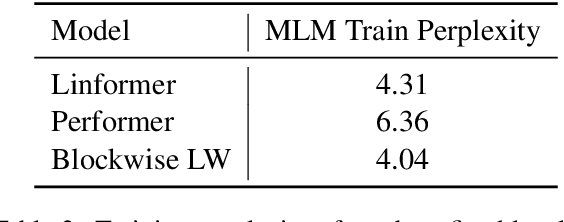
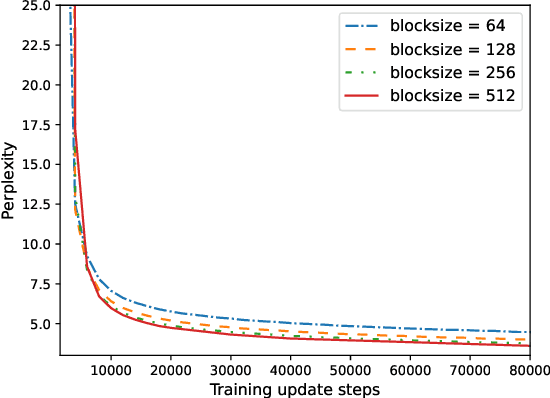
Many NLP tasks require processing long contexts beyond the length limit of pretrained models. In order to scale these models to longer text sequences, many efficient long-range attention variants have been proposed. Despite the abundance of research along this direction, it is still difficult to gauge the relative effectiveness of these models in practical use cases, e.g., if we apply these models following the pretrain-and-finetune paradigm. In this work, we aim to conduct a thorough analysis of these emerging models with large-scale and controlled experiments. For each attention variant, we pretrain large-size models using the same long-doc corpus and then finetune these models for real-world long-context tasks. Our findings reveal pitfalls of an existing widely-used long-range benchmark and show none of the tested efficient attentions can beat a simple local window attention under standard pretraining paradigms. Further analysis on local attention variants suggests that even the commonly used attention-window overlap is not necessary to achieve good downstream results -- using disjoint local attentions, we are able to build a simpler and more efficient long-doc QA model that matches the performance of Longformer~\citep{longformer} with half of its pretraining compute.
CCQA: A New Web-Scale Question Answering Dataset for Model Pre-Training
Oct 14, 2021

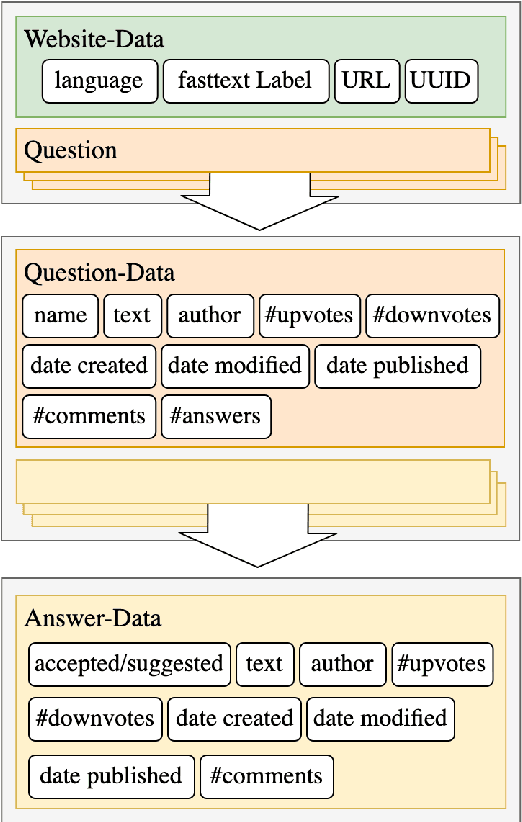

With the rise of large-scale pre-trained language models, open-domain question-answering (ODQA) has become an important research topic in NLP. Based on the popular pre-training fine-tuning approach, we posit that an additional in-domain pre-training stage using a large-scale, natural, and diverse question-answering (QA) dataset can be beneficial for ODQA. Consequently, we propose a novel QA dataset based on the Common Crawl project in this paper. Using the readily available schema.org annotation, we extract around 130 million multilingual question-answer pairs, including about 60 million English data-points. With this previously unseen number of natural QA pairs, we pre-train popular language models to show the potential of large-scale in-domain pre-training for the task of question-answering. In our experiments, we find that pre-training question-answering models on our Common Crawl Question Answering dataset (CCQA) achieves promising results in zero-shot, low resource and fine-tuned settings across multiple tasks, models and benchmarks.