 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Wikipedia Verifiability with AI
Jul 08, 2022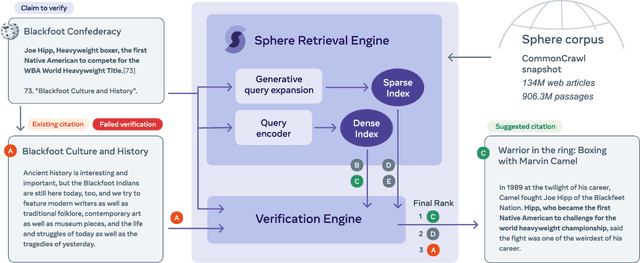

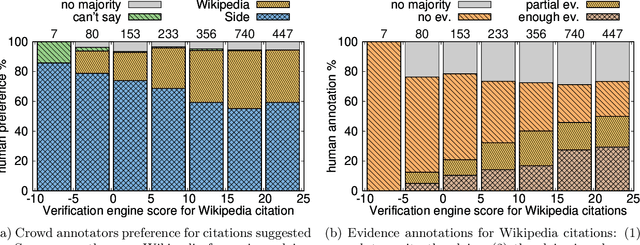
Verifiability is a core content policy of Wikipedia: claims that are likely to be challenged need to be backed by citations. There are millions of articles available online and thousands of new articles are released each month. For this reason, finding relevant sources is a difficult task: many claims do not have any references that support them. Furthermore, even existing citations might not support a given claim or become obsolete once the original source is updated or deleted. Hence, maintaining and improving the quality of Wikipedia references is an important challenge and there is a pressing need for better tools to assist humans in this effort. Here, we show that the process of improving references can be tackled with the help of artificial intelligence (AI). We develop a neural network based system, called Side, to identify Wikipedia citations that are unlikely to support their claims, and subsequently recommend better ones from the web. We train this model on existing Wikipedia references, therefore learning from the contributions and combined wisdom of thousands of Wikipedia editors. Using crowd-sourcing, we observe that for the top 10% most likely citations to be tagged as unverifiable by our system, humans prefer our system's suggested alternatives compared to the originally cited reference 70% of the time. To validate the applicability of our system, we built a demo to engage with the English-speaking Wikipedia community and find that Side's first citation recommendation collects over 60% more preferences than existing Wikipedia citations for the same top 10% most likely unverifiable claims according to Side. Our results indicate that an AI-based system could be used, in tandem with humans, to improve the verifiability of Wikipedia. More generally, we hope that our work can be used to assist fact checking efforts and increase the general trustworthiness of information online.
The Web Is Your Oyster -- Knowledge-Intensive NLP against a Very Large Web Corpus
Dec 18, 2021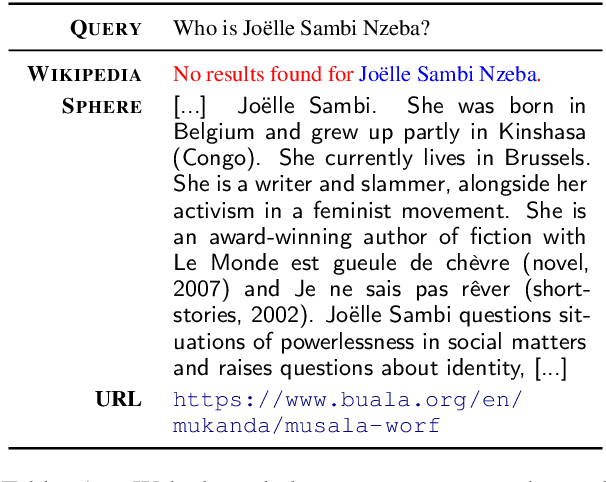
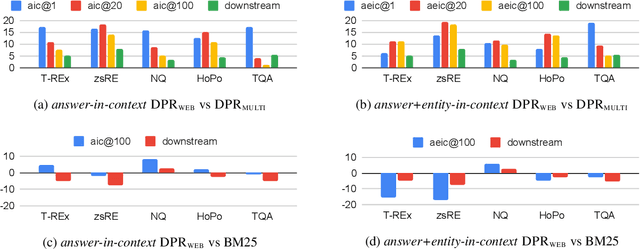
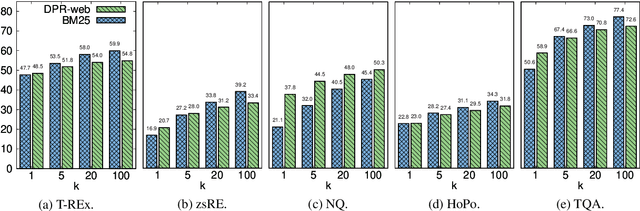
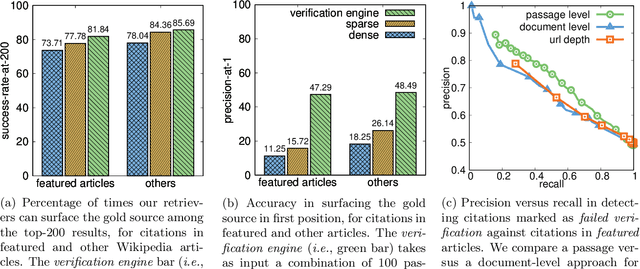
In order to address the increasing demands of real-world applications, the research for knowledge-intensive NLP (KI-NLP) should advance by capturing the challenges of a truly open-domain environment: web scale knowledge, lack of structure, inconsistent quality, and noise. To this end, we propose a new setup for evaluating existing KI-NLP tasks in which we generalize the background corpus to a universal web snapshot. We repurpose KILT, a standard KI-NLP benchmark initially developed for Wikipedia, and ask systems to use a subset of CCNet - the Sphere corpus - as a knowledge source. In contrast to Wikipedia, Sphere is orders of magnitude larger and better reflects the full diversity of knowledge on the Internet. We find that despite potential gaps of coverage, challenges of scale, lack of structure and lower quality, retrieval from Sphere enables a state-of-the-art retrieve-and-read system to match and even outperform Wikipedia-based models on several KILT tasks - even if we aggressively filter content that looks like Wikipedia. We also observe that while a single dense passage index over Wikipedia can outperform a sparse BM25 version, on Sphere this is not yet possible. To facilitate further research into this area, and minimise the community's reliance on proprietary black box search engines, we will share our indices, evaluation metrics and infrastructure.
Investigating Entity Knowledge in BERT with Simple Neural End-To-End Entity Linking
Mar 11, 2020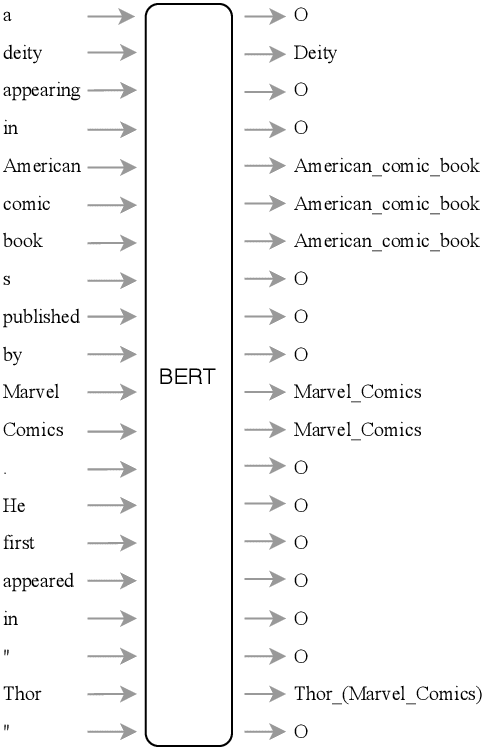
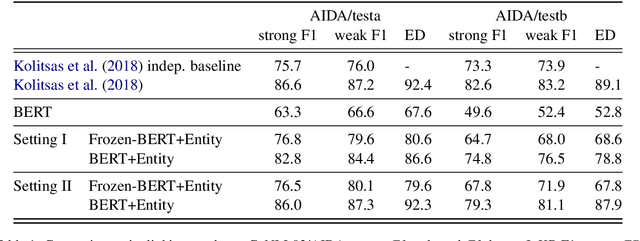

A typical architecture for end-to-end entity linking systems consists of three steps: mention detection, candidate generation and entity disambiguation. In this study we investigate the following questions: (a) Can all those steps be learned jointly with a model for contextualized text-representations, i.e. BERT (Devlin et al., 2019)? (b) How much entity knowledge is already contained in pretrained BERT? (c) Does additional entity knowledge improve BERT's performance in downstream tasks? To this end, we propose an extreme simplification of the entity linking setup that works surprisingly well: simply cast it as a per token classification over the entire entity vocabulary (over 700K classes in our case). We show on an entity linking benchmark that (i) this model improves the entity representations over plain BERT, (ii) that it outperforms entity linking architectures that optimize the tasks separately and (iii) that it only comes second to the current state-of-the-art that does mention detection and entity disambiguation jointly. Additionally, we investigate the usefulness of entity-aware token-representations in the text-understanding benchmark GLUE, as well as the question answering benchmarks SQUAD V2 and SWAG and also the EN-DE WMT14 machine translation benchmark. To our surprise, we find that most of those benchmarks do not benefit from additional entity knowledge, except for a task with very small training data, the RTE task in GLUE, which improves by 2%.
* Published at CoNLL 2019
OPIEC: An Open Information Extraction Corpus
Apr 28, 2019
Open information extraction (OIE) systems extract relations and their arguments from natural language text in an unsupervised manner. The resulting extractions are a valuable resource for downstream tasks such as knowledge base construction, open question answering, or event schema induction. In this paper, we release, describe, and analyze an OIE corpus called OPIEC, which was extracted from the text of English Wikipedia. OPIEC complements the available OIE resources: It is the largest OIE corpus publicly available to date (over 340M triples) and contains valuable metadata such as provenance information, confidence scores, linguistic annotations, and semantic annotations including spatial and temporal information. We analyze the OPIEC corpus by comparing its content with knowledge bases such as DBpedia or YAGO, which are also based on Wikipedia. We found that most of the facts between entities present in OPIEC cannot be found in DBpedia and/or YAGO, that OIE facts often differ in the level of specificity compared to knowledge base facts, and that OIE open relations are generally highly polysemous. We believe that the OPIEC corpus is a valuable resource for future research on automated knowledge base construction.
* In Proceedings of the Conference of Automatic Knowledge Base Construction (AKBC) 2019
A Relational Tucker Decomposition for Multi-Relational Link Prediction
Feb 03, 2019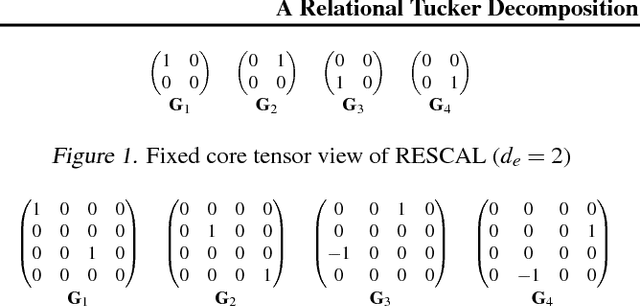

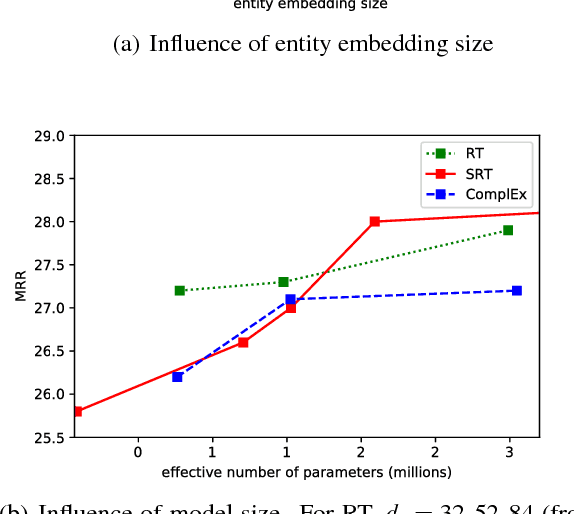
We propose the Relational Tucker3 (RT) decomposition for multi-relational link prediction in knowledge graphs. We show that many existing knowledge graph embedding models are special cases of the RT decomposition with certain predefined sparsity patterns in its components. In contrast to these prior models, RT decouples the sizes of entity and relation embeddings, allows parameter sharing across relations, and does not make use of a predefined sparsity pattern. We use the RT decomposition as a tool to explore whether it is possible and beneficial to automatically learn sparsity patterns, and whether dense models can outperform sparse models (using the same number of parameters). Our experiments indicate that---depending on the dataset--both questions can be answered affirmatively.
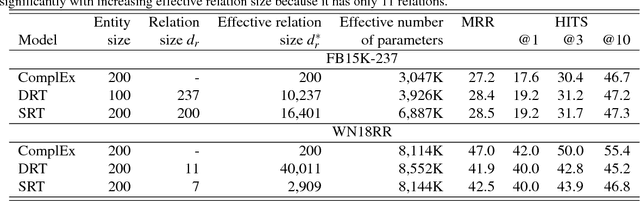
Do Embedding Models Perform Well for Knowledge Base Completion?
Nov 06, 2018
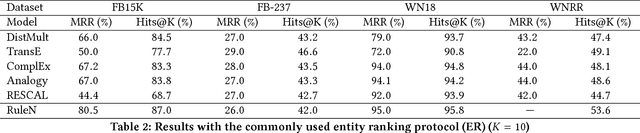
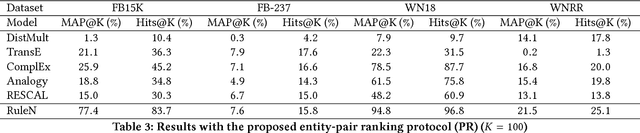
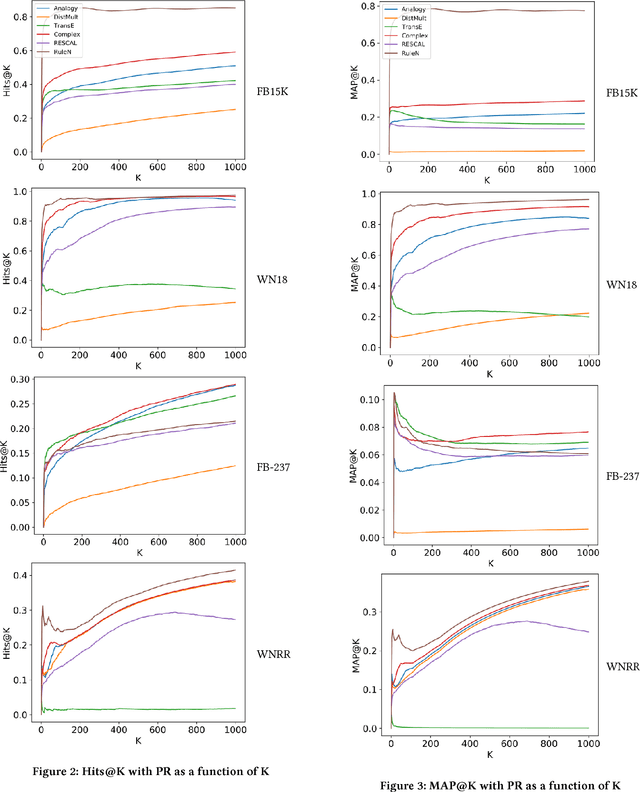
In this work, we put into question the effectiveness of the evaluation methods currently used to measure the performance of latent factor models for the task of knowledge base completion. We argue that by focusing on a small subset of possible facts in the knowledge base, current evaluation practices are better suited for question answering tasks, rather than knowledge base completion, where it is also important to avoid the addition of incorrect facts into the knowledge base. We illustrate our point by showing how models with limited expressiveness achieve state-of-the-art performance, even while adding many incorrect (even nonsensical) facts to a knowledge base. Finally, we show that when using a simple evaluation procedure designed to also penalize the addition of incorrect facts, the general and relative performance of all models looks very different than previously seen. This indicates the need for more powerful latent factor models for the task of knowledge base completion.