 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeCodec: An End-to-end Learned Compression Framework for Spiking Camera
Jun 25, 2023



Recently, the bio-inspired spike camera with continuous motion recording capability has attracted tremendous attention due to its ultra high temporal resolution imaging characteristic. Such imaging feature results in huge data storage and transmission burden compared to that of traditional camera, raising severe challenge and imminent necessity in compression for spike camera captured content. Existing lossy data compression methods could not be applied for compressing spike streams efficiently due to integrate-and-fire characteristic and binarized data structure. Considering the imaging principle and information fidelity of spike cameras, we introduce an effective and robust representation of spike streams. Based on this representation, we propose a novel learned spike compression framework using scene recovery, variational auto-encoder plus spike simulator. To our knowledge, it is the first data-trained model for efficient and robust spike stream compression. Extensive experimental results show that our method outperforms the conventional and learning-based codecs, contributing a strong baseline for learned spike data compression.
Diffusion-Based 3D Human Pose Estimation with Multi-Hypothesis Aggregation
Mar 21, 2023



In this paper, a novel Diffusion-based 3D Pose estimation (D3DP) method with Joint-wise reProjection-based Multi-hypothesis Aggregation (JPMA) is proposed for probabilistic 3D human pose estimation. On the one hand, D3DP generates multiple possible 3D pose hypotheses for a single 2D observation. It gradually diffuses the ground truth 3D poses to a random distribution, and learns a denoiser conditioned on 2D keypoints to recover the uncontaminated 3D poses. The proposed D3DP is compatible with existing 3D pose estimators and supports users to balance efficiency and accuracy during inference through two customizable parameters. On the other hand, JPMA is proposed to assemble multiple hypotheses generated by D3DP into a single 3D pose for practical use. It reprojects 3D pose hypotheses to the 2D camera plane, selects the best hypothesis joint-by-joint based on the reprojection errors, and combines the selected joints into the final pose. The proposed JPMA conducts aggregation at the joint level and makes use of the 2D prior information, both of which have been overlooked by previous approaches. Extensive experiments on Human3.6M and MPI-INF-3DHP datasets show that our method outperforms the state-of-the-art deterministic and probabilistic approaches by 1.5% and 8.9%, respectively. Code is available at https://github.com/paTRICK-swk/D3DP.
Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey
Feb 20, 2023With the urgent demand for generalized deep models, many pre-trained big models are proposed, such as BERT, ViT, GPT, etc. Inspired by the success of these models in single domains (like computer vision and natural language processing), the multi-modal pre-trained big models have also drawn more and more attention in recent years. In this work, we give a comprehensive survey of these models and hope this paper could provide new insights and helps fresh researchers to track the most cutting-edge works. Specifically, we firstly introduce the background of multi-modal pre-training by reviewing the conventional deep learning, pre-training works in natural language process, computer vision, and speech. Then, we introduce the task definition, key challenges, and advantages of multi-modal pre-training models (MM-PTMs), and discuss the MM-PTMs with a focus on data, objectives, network architectures, and knowledge enhanced pre-training. After that, we introduce the downstream tasks used for the validation of large-scale MM-PTMs, including generative, classification, and regression tasks. We also give visualization and analysis of the model parameters and results on representative downstream tasks. Finally, we point out possible research directions for this topic that may benefit future works. In addition, we maintain a continuously updated paper list for large-scale pre-trained multi-modal big models: https://github.com/wangxiao5791509/MultiModal_BigModels_Survey
Learning to Compress Unmanned Aerial Vehicle (UAV) Captured Video: Benchmark and Analysis
Jan 15, 2023



During the past decade, the Unmanned-Aerial-Vehicles (UAVs) have attracted increasing attention due to their flexible, extensive, and dynamic space-sensing capabilities. The volume of video captured by UAVs is exponentially growing along with the increased bitrate generated by the advancement of the sensors mounted on UAVs, bringing new challenges for on-device UAV storage and air-ground data transmission. Most existing video compression schemes were designed for natural scenes without consideration of specific texture and view characteristics of UAV videos. In this work, we first contribute a detailed analysis of the current state of the field of UAV video coding. Then we propose to establish a novel task for learned UAV video coding and construct a comprehensive and systematic benchmark for such a task, present a thorough review of high quality UAV video datasets and benchmarks, and contribute extensive rate-distortion efficiency comparison of learned and conventional codecs after. Finally, we discuss the challenges of encoding UAV videos. It is expected that the benchmark will accelerate the research and development in video coding on drone platforms.
SMR: Satisfied Machine Ratio Modeling for Machine Recognition-Oriented Image and Video Compression
Nov 13, 2022



Tons of images and videos are fed into machines for visual recognition all the time. Like human vision system (HVS), machine vision system (MVS) is sensitive to image quality, as quality degradation leads to information loss and recognition failure. In recent years, MVS-targeted image processing, particularly image and video compression, has emerged. However, existing methods only target an individual machine rather than the general machine community, thus cannot satisfy every type of machine. Moreover, the MVS characteristics are not well leveraged, which limits compression efficiency. In this paper, we introduce a new concept, Satisfied Machine Ratio (SMR), to address these issues. SMR statistically measures the image quality from the machine's perspective by collecting and combining satisfaction scores from a large quantity and variety of machine subjects, where such scores are obtained with MVS characteristics considered properly. We create the first large-scale SMR dataset that contains over 22 million annotated images for SMR studies. Furthermore, a deep learning-based model is proposed to predict the SMR for any given compressed image or video frame. Extensive experiments show that using the SMR model can significantly improve the performance of machine recognition-oriented image and video compression. And the SMR model generalizes well to unseen machines, compression frameworks, and datasets.
Deep Lossy Plus Residual Coding for Lossless and Near-lossless Image Compression
Sep 11, 2022
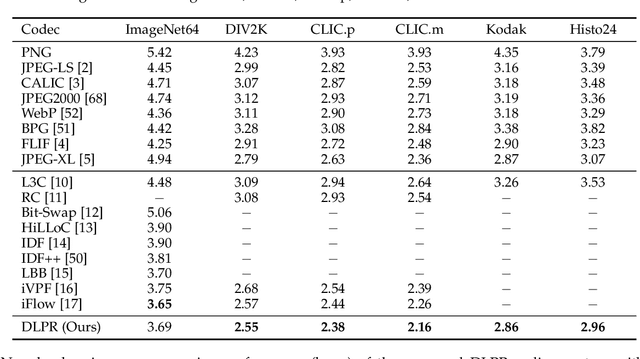
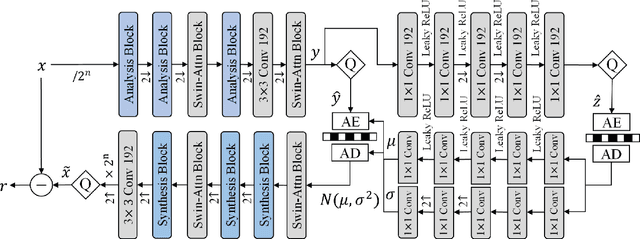
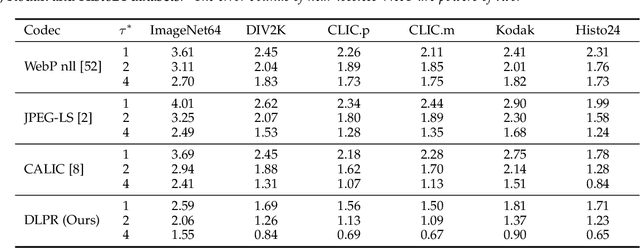
Lossless and near-lossless image compression is of paramount importance to professional users in many technical fields, such as medicine, remote sensing, precision engineering and scientific research. But despite rapidly growing research interests in learning-based image compression, no published method offers both lossless and near-lossless modes. In this paper, we propose a unified and powerful deep lossy plus residual (DLPR) coding framework for both lossless and near-lossless image compression. In the lossless mode, the DLPR coding system first performs lossy compression and then lossless coding of residuals. We solve the joint lossy and residual compression problem in the approach of VAEs, and add autoregressive context modeling of the residuals to enhance lossless compression performance. In the near-lossless mode, we quantize the original residuals to satisfy a given $\ell_\infty$ error bound, and propose a scalable near-lossless compression scheme that works for variable $\ell_\infty$ bounds instead of training multiple networks. To expedite the DLPR coding, we increase the degree of algorithm parallelization by a novel design of coding context, and accelerate the entropy coding with adaptive residual interval. Experimental results demonstrate that the DLPR coding system achieves both the state-of-the-art lossless and near-lossless image compression performance with competitive coding speed.
Cross Modal Compression: Towards Human-comprehensible Semantic Compression
Sep 06, 2022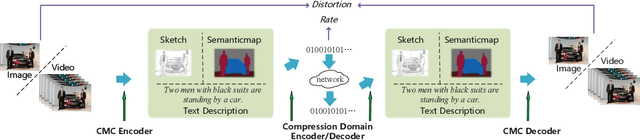
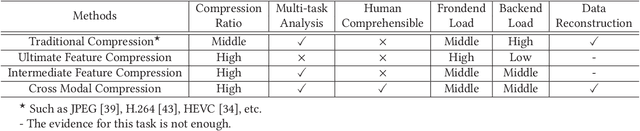
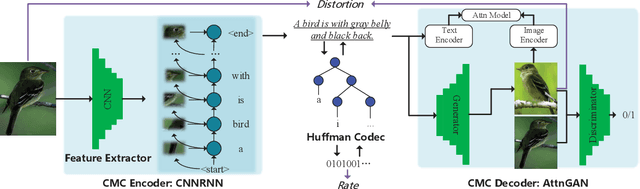

Traditional image/video compression aims to reduce the transmission/storage cost with signal fidelity as high as possible. However, with the increasing demand for machine analysis and semantic monitoring in recent years, semantic fidelity rather than signal fidelity is becoming another emerging concern in image/video compression. With the recent advances in cross modal translation and generation, in this paper, we propose the cross modal compression~(CMC), a semantic compression framework for visual data, to transform the high redundant visual data~(such as image, video, etc.) into a compact, human-comprehensible domain~(such as text, sketch, semantic map, attributions, etc.), while preserving the semantic. Specifically, we first formulate the CMC problem as a rate-distortion optimization problem. Secondly, we investigate the relationship with the traditional image/video compression and the recent feature compression frameworks, showing the difference between our CMC and these prior frameworks. Then we propose a novel paradigm for CMC to demonstrate its effectiveness. The qualitative and quantitative results show that our proposed CMC can achieve encouraging reconstructed results with an ultrahigh compression ratio, showing better compression performance than the widely used JPEG baseline.
Towards Hybrid-Optimization Video Coding
Jul 12, 2022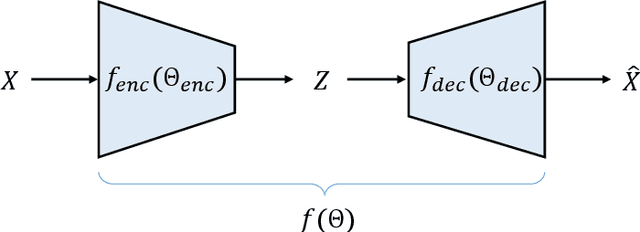

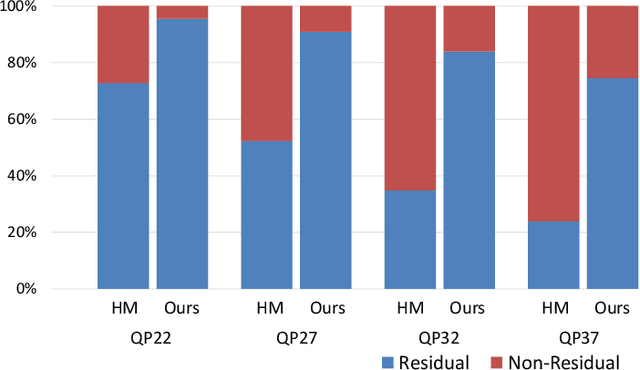
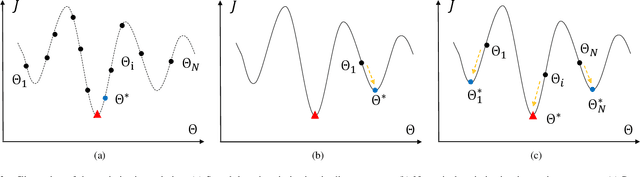
Video coding is a mathematical optimization problem of rate and distortion essentially. To solve this complex optimization problem, two popular video coding frameworks have been developed: block-based hybrid video coding and end-to-end learned video coding. If we rethink video coding from the perspective of optimization, we find that the existing two frameworks represent two directions of optimization solutions. Block-based hybrid coding represents the discrete optimization solution because those irrelevant coding modes are discrete in mathematics. It searches for the best one among multiple starting points (i.e. modes). However, the search is not efficient enough. On the other hand, end-to-end learned coding represents the continuous optimization solution because the gradient descent is based on a continuous function. It optimizes a group of model parameters efficiently by the numerical algorithm. However, limited by only one starting point, it is easy to fall into the local optimum. To better solve the optimization problem, we propose to regard video coding as a hybrid of the discrete and continuous optimization problem, and use both search and numerical algorithm to solve it. Our idea is to provide multiple discrete starting points in the global space and optimize the local optimum around each point by numerical algorithm efficiently. Finally, we search for the global optimum among those local optimums. Guided by the hybrid optimization idea, we design a hybrid optimization video coding framework, which is built on continuous deep networks entirely and also contains some discrete modes. We conduct a comprehensive set of experiments. Compared to the continuous optimization framework, our method outperforms pure learned video coding methods. Meanwhile, compared to the discrete optimization framework, our method achieves comparable performance to HEVC reference software HM16.10 in PSNR.
STIP: A SpatioTemporal Information-Preserving and Perception-Augmented Model for High-Resolution Video Prediction
Jun 09, 2022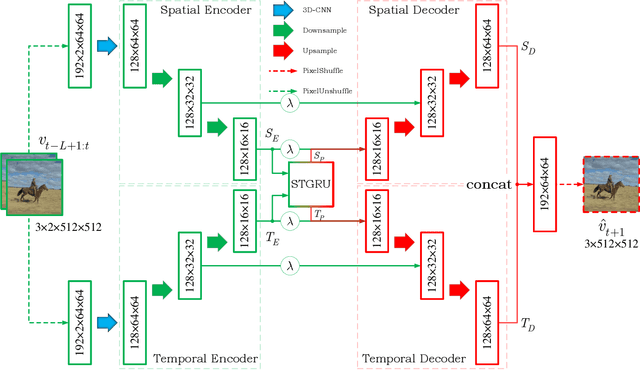
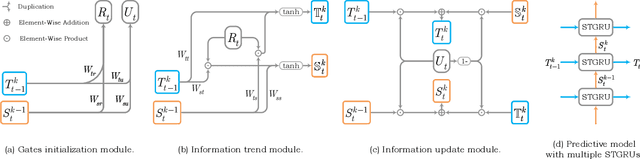
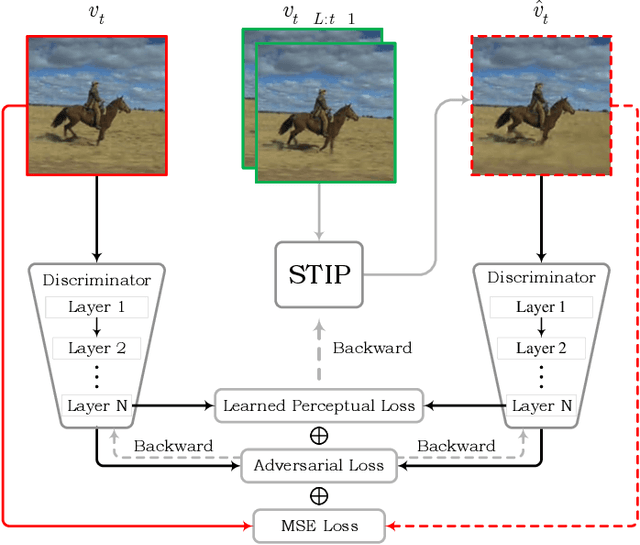

Although significant achievements have been achieved by recurrent neural network (RNN) based video prediction methods, their performance in datasets with high resolutions is still far from satisfactory because of the information loss problem and the perception-insensitive mean square error (MSE) based loss functions. In this paper, we propose a Spatiotemporal Information-Preserving and Perception-Augmented Model (STIP) to solve the above two problems. To solve the information loss problem, the proposed model aims to preserve the spatiotemporal information for videos during the feature extraction and the state transitions, respectively. Firstly, a Multi-Grained Spatiotemporal Auto-Encoder (MGST-AE) is designed based on the X-Net structure. The proposed MGST-AE can help the decoders recall multi-grained information from the encoders in both the temporal and spatial domains. In this way, more spatiotemporal information can be preserved during the feature extraction for high-resolution videos. Secondly, a Spatiotemporal Gated Recurrent Unit (STGRU) is designed based on the standard Gated Recurrent Unit (GRU) structure, which can efficiently preserve spatiotemporal information during the state transitions. The proposed STGRU can achieve more satisfactory performance with a much lower computation load compared with the popular Long Short-Term (LSTM) based predictive memories. Furthermore, to improve the traditional MSE loss functions, a Learned Perceptual Loss (LP-loss) is further designed based on the Generative Adversarial Networks (GANs), which can help obtain a satisfactory trade-off between the objective quality and the perceptual quality. Experimental results show that the proposed STIP can predict videos with more satisfactory visual quality compared with a variety of state-of-the-art methods. Source code has been available at \url{https://github.com/ZhengChang467/STIPHR}.
Hierarchical Similarity Learning for Aliasing Suppression Image Super-Resolution
Jun 07, 2022



As a highly ill-posed issue, single image super-resolution (SISR) has been widely investigated in recent years. The main task of SISR is to recover the information loss caused by the degradation procedure. According to the Nyquist sampling theory, the degradation leads to aliasing effect and makes it hard to restore the correct textures from low-resolution (LR) images. In practice, there are correlations and self-similarities among the adjacent patches in the natural images. This paper considers the self-similarity and proposes a hierarchical image super-resolution network (HSRNet) to suppress the influence of aliasing. We consider the SISR issue in the optimization perspective, and propose an iterative solution pattern based on the half-quadratic splitting (HQS) method. To explore the texture with local image prior, we design a hierarchical exploration block (HEB) and progressive increase the receptive field. Furthermore, multi-level spatial attention (MSA) is devised to obtain the relations of adjacent feature and enhance the high-frequency information, which acts as a crucial role for visual experience. Experimental result shows HSRNet achieves better quantitative and visual performance than other works, and remits the aliasing more effectively.