 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation
Nov 18, 2022



We introduce GENIUS: a conditional text generation model using sketches as input, which can fill in the missing contexts for a given sketch (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large-scale textual corpus with a novel reconstruction from sketch objective using an extreme and selective masking strategy, enabling it to generate diverse and high-quality texts given sketches. Comparison with other competitive conditional language models (CLMs) reveals the superiority of GENIUS's text generation quality. We further show that GENIUS can be used as a strong and ready-to-use data augmentation tool for various natural language processing (NLP) tasks. Most existing textual data augmentation methods are either too conservative, by making small changes to the original text, or too aggressive, by creating entirely new samples. With GENIUS, we propose GeniusAug, which first extracts the target-aware sketches from the original training set and then generates new samples based on the sketches. Empirical experiments on 6 text classification datasets show that GeniusAug significantly improves the models' performance in both in-distribution (ID) and out-of-distribution (OOD) settings. We also demonstrate the effectiveness of GeniusAug on named entity recognition (NER) and machine reading comprehension (MRC) tasks. (Code and models are publicly available at https://github.com/microsoft/SCGLab and https://github.com/beyondguo/genius)
Soft-Labeled Contrastive Pre-training for Function-level Code Representation
Oct 18, 2022
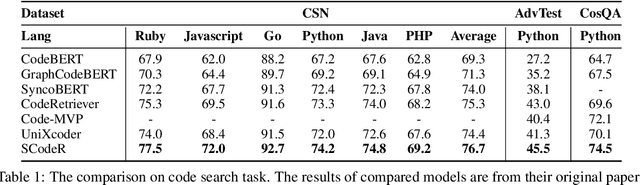
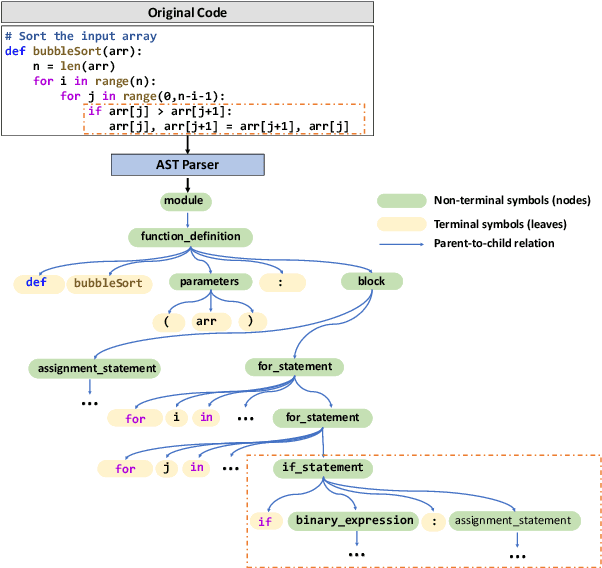
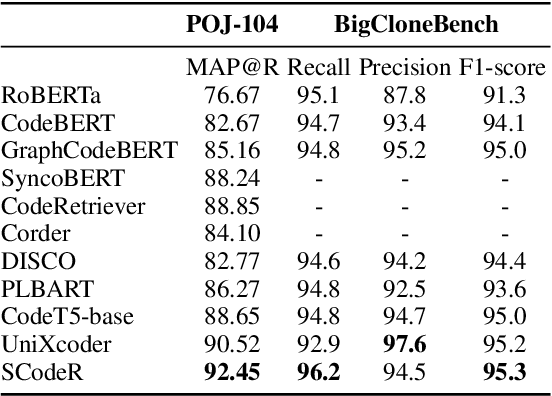
Code contrastive pre-training has recently achieved significant progress on code-related tasks. In this paper, we present \textbf{SCodeR}, a \textbf{S}oft-labeled contrastive pre-training framework with two positive sample construction methods to learn functional-level \textbf{Code} \textbf{R}epresentation. Considering the relevance between codes in a large-scale code corpus, the soft-labeled contrastive pre-training can obtain fine-grained soft-labels through an iterative adversarial manner and use them to learn better code representation. The positive sample construction is another key for contrastive pre-training. Previous works use transformation-based methods like variable renaming to generate semantically equal positive codes. However, they usually result in the generated code with a highly similar surface form, and thus mislead the model to focus on superficial code structure instead of code semantics. To encourage SCodeR to capture semantic information from the code, we utilize code comments and abstract syntax sub-trees of the code to build positive samples. We conduct experiments on four code-related tasks over seven datasets. Extensive experimental results show that SCodeR achieves new state-of-the-art performance on all of them, which illustrates the effectiveness of the proposed pre-training method.
Less is More: Task-aware Layer-wise Distillation for Language Model Compression
Oct 05, 2022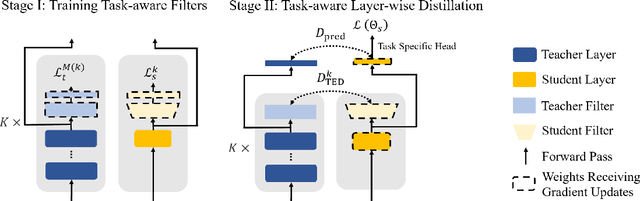
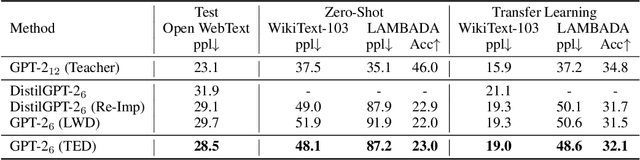
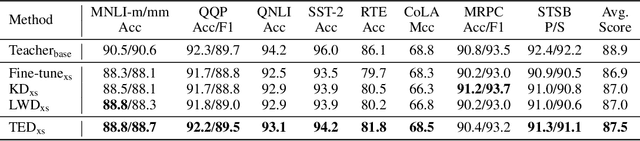
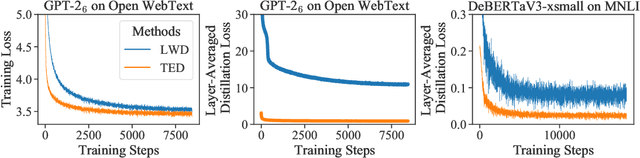
Layer-wise distillation is a powerful tool to compress large models (i.e. teacher models) into small ones (i.e., student models). The student distills knowledge from the teacher by mimicking the hidden representations of the teacher at every intermediate layer. However, layer-wise distillation is difficult. Since the student has a smaller model capacity than the teacher, it is often under-fitted. Furthermore, the hidden representations of the teacher contain redundant information that the student does not necessarily need for the target task's learning. To address these challenges, we propose a novel Task-aware layEr-wise Distillation (TED). TED designs task-aware filters to align the hidden representations of the student and the teacher at each layer. The filters select the knowledge that is useful for the target task from the hidden representations. As such, TED reduces the knowledge gap between the two models and helps the student to fit better on the target task. We evaluate TED in two scenarios: continual pre-training and fine-tuning. TED demonstrates significant and consistent improvements over existing distillation methods in both scenarios.
CodeT: Code Generation with Generated Tests
Jul 21, 2022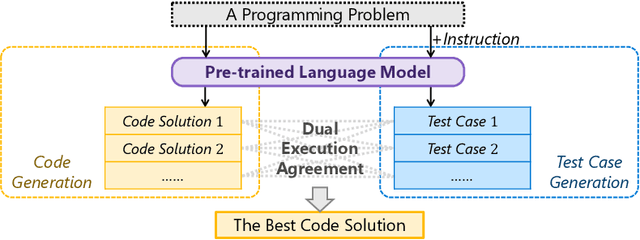
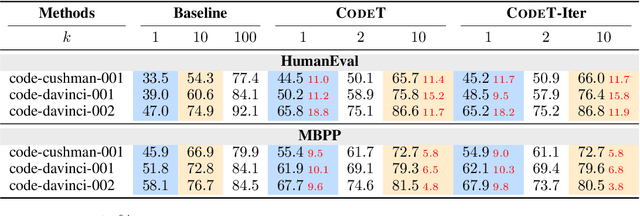

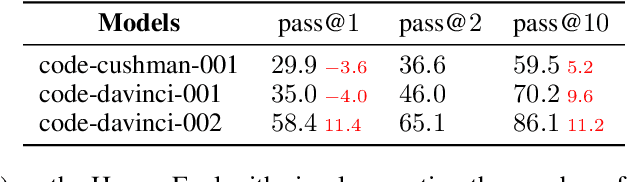
Given a programming problem, pre-trained language models such as Codex have demonstrated the ability to generate multiple different code solutions via sampling. However, selecting a correct or best solution from those samples still remains a challenge. While an easy way to verify the correctness of a code solution is through executing test cases, producing high-quality test cases is prohibitively expensive. In this paper, we explore the use of pre-trained language models to automatically generate test cases, calling our method CodeT: Code generation with generated Tests. CodeT executes the code solutions using the generated test cases, and then chooses the best solution based on a dual execution agreement with both the generated test cases and other generated solutions. We evaluate CodeT on five different pre-trained models with both HumanEval and MBPP benchmarks. Extensive experimental results demonstrate CodeT can achieve significant, consistent, and surprising improvements over previous methods. For example, CodeT improves the pass@1 on HumanEval to 65.8%, an increase of absolute 18.8% on the code-davinci-002 model, and an absolute 20+% improvement over previous state-of-the-art results.
OmniTab: Pretraining with Natural and Synthetic Data for Few-shot Table-based Question Answering
Jul 08, 2022
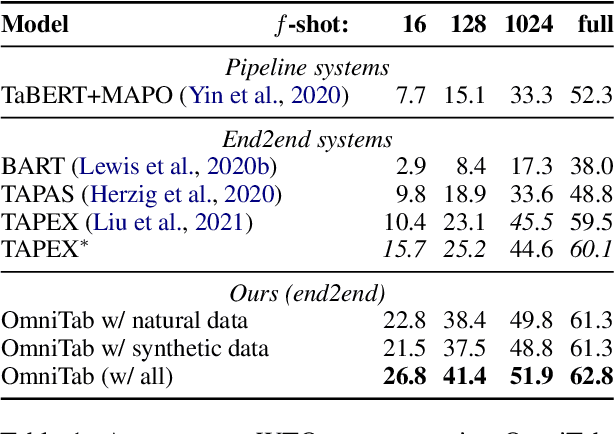
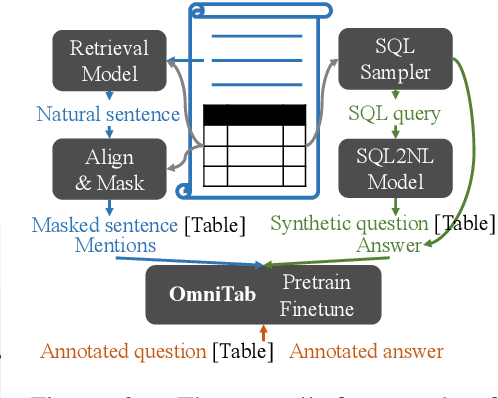
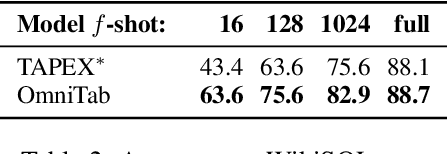
The information in tables can be an important complement to text, making table-based question answering (QA) systems of great value. The intrinsic complexity of handling tables often adds an extra burden to both model design and data annotation. In this paper, we aim to develop a simple table-based QA model with minimal annotation effort. Motivated by the fact that table-based QA requires both alignment between questions and tables and the ability to perform complicated reasoning over multiple table elements, we propose an omnivorous pretraining approach that consumes both natural and synthetic data to endow models with these respective abilities. Specifically, given freely available tables, we leverage retrieval to pair them with relevant natural sentences for mask-based pretraining, and synthesize NL questions by converting SQL sampled from tables for pretraining with a QA loss. We perform extensive experiments in both few-shot and full settings, and the results clearly demonstrate the superiority of our model OmniTab, with the best multitasking approach achieving an absolute gain of 16.2% and 2.7% in 128-shot and full settings respectively, also establishing a new state-of-the-art on WikiTableQuestions. Detailed ablations and analyses reveal different characteristics of natural and synthetic data, shedding light on future directions in omnivorous pretraining. Code, pretraining data, and pretrained models are available at https://github.com/jzbjyb/OmniTab.
Joint Generator-Ranker Learning for Natural Language Generation
Jun 28, 2022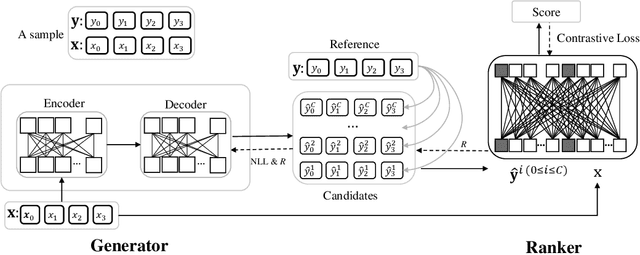
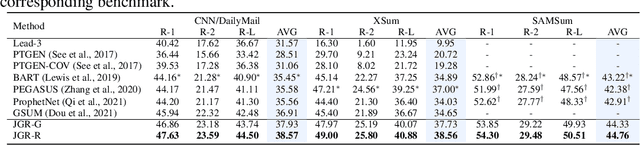

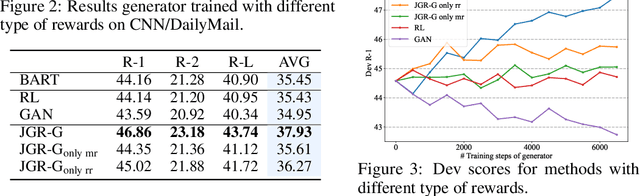
Due to exposure bias, most existing natural language generation (NLG) models trained by maximizing the likelihood objective predict poor text results during the inference stage. In this paper, to tackle this problem, we revisit the generate-then-rank framework and propose a joint generator-ranker (JGR) training algorithm for text generation tasks. In JGR, the generator model is trained by maximizing two objectives: the likelihood of the training corpus and the expected reward given by the ranker model. Meanwhile, the ranker model takes input samples from the generator model and learns to distinguish good samples from the generation pool. The generator and ranker models are alternately optimized till convergence. In the empirical study, the proposed JGR model achieves new state-of-the-art performance on five public benchmarks covering three popular generation tasks: summarization, question generation, and response generation. We will make code, data, and models available at https://github.com/microsoft/AdvNLG.
PLATON: Pruning Large Transformer Models with Upper Confidence Bound of Weight Importance
Jun 25, 2022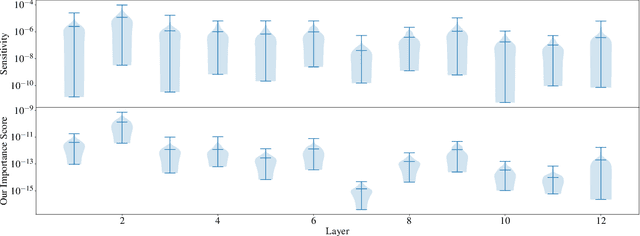
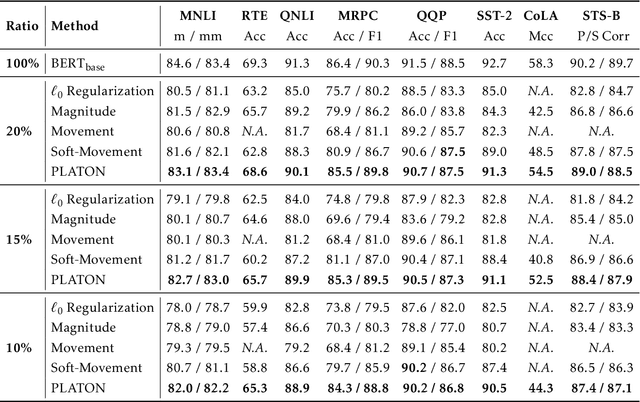
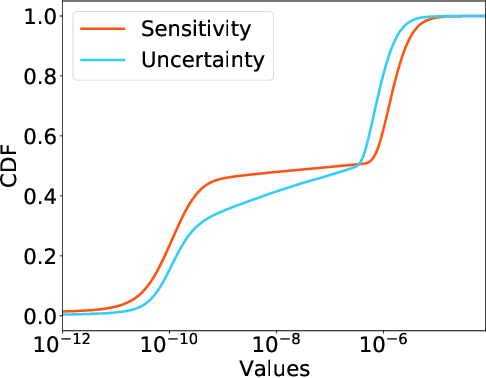
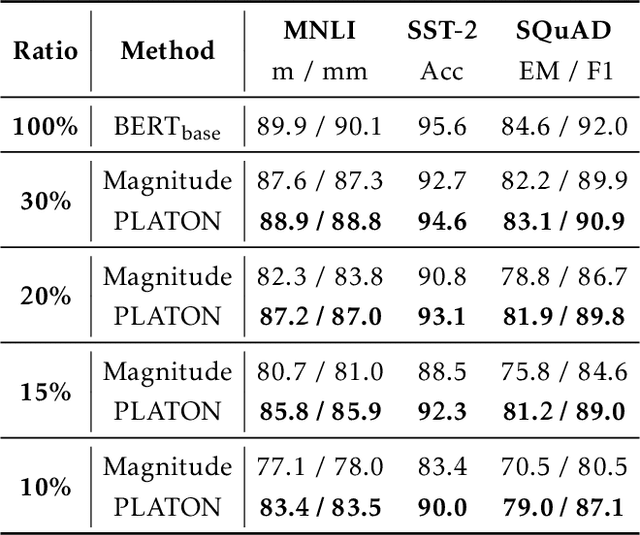
Large Transformer-based models have exhibited superior performance in various natural language processing and computer vision tasks. However, these models contain enormous amounts of parameters, which restrict their deployment to real-world applications. To reduce the model size, researchers prune these models based on the weights' importance scores. However, such scores are usually estimated on mini-batches during training, which incurs large variability/uncertainty due to mini-batch sampling and complicated training dynamics. As a result, some crucial weights could be pruned by commonly used pruning methods because of such uncertainty, which makes training unstable and hurts generalization. To resolve this issue, we propose PLATON, which captures the uncertainty of importance scores by upper confidence bound (UCB) of importance estimation. In particular, for the weights with low importance scores but high uncertainty, PLATON tends to retain them and explores their capacity. We conduct extensive experiments with several Transformer-based models on natural language understanding, question answering and image classification to validate the effectiveness of PLATON. Results demonstrate that PLATON manifests notable improvement under different sparsity levels. Our code is publicly available at https://github.com/QingruZhang/PLATON.
CERT: Continual Pre-Training on Sketches for Library-Oriented Code Generation
Jun 14, 2022
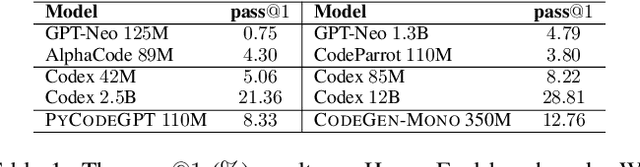

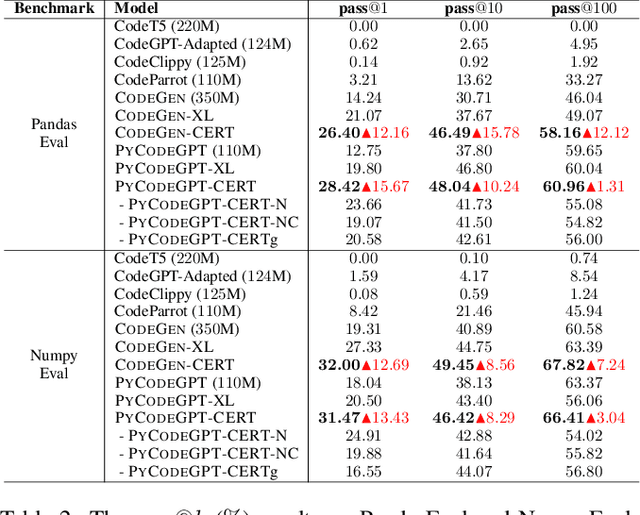
Code generation is a longstanding challenge, aiming to generate a code snippet based on a natural language description. Usually, expensive text-code paired data is essential for training a code generation model. Recently, thanks to the success of pre-training techniques, large language models are trained on large-scale unlabelled code corpora and perform well in code generation. In this paper, we investigate how to leverage an unlabelled code corpus to train a model for library-oriented code generation. Since it is a common practice for programmers to reuse third-party libraries, in which case the text-code paired data are harder to obtain due to the huge number of libraries. We observe that library-oriented code snippets are more likely to share similar code sketches. Hence, we present CERT with two steps: a sketcher generates the sketch, then a generator fills the details in the sketch. Both the sketcher and the generator are continually pre-trained upon a base model using unlabelled data. Furthermore, we craft two benchmarks named PandasEval and NumpyEval to evaluate library-oriented code generation. Experimental results demonstrate the impressive performance of CERT. For example, it surpasses the base model by an absolute 15.67% improvement in terms of pass@1 on PandasEval. Our work is available at https://github.com/microsoft/PyCodeGPT.
On the Advance of Making Language Models Better Reasoners
Jun 07, 2022
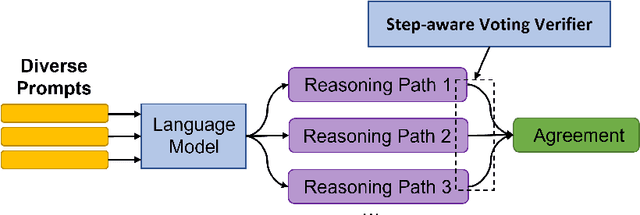
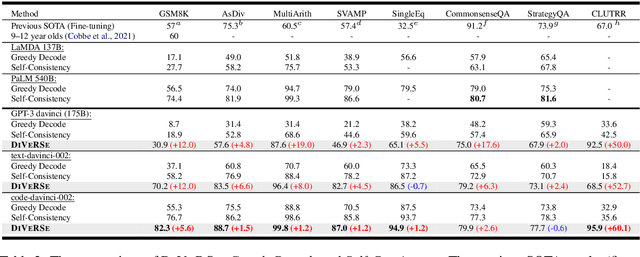

Large language models such as GPT-3 and PaLM have shown remarkable performance in few-shot learning. However, they still struggle with reasoning tasks such as the arithmetic benchmark GSM8K. Recent advances deliberately guide the language model to generate a chain of reasoning steps before producing the final answer, successfully boosting the GSM8K benchmark from 17.9% to 58.1% in terms of problem solving rate. In this paper, we propose a new approach, DiVeRSe (Diverse Verifier on Reasoning Step), to further advance their reasoning capability. DiVeRSe first explores different prompts to enhance the diversity in reasoning paths. Second, DiVeRSe introduces a verifier to distinguish good answers from bad answers for a better weighted voting. Finally, DiVeRSe verifies the correctness of each single step rather than all the steps in a whole. We conduct extensive experiments using the latest language model code-davinci-002 and demonstrate that DiVeRSe can achieve new state-of-the-art performance on six out of eight reasoning benchmarks (e.g., GSM8K 74.4% to 83.2%), outperforming the PaLM model with 540B parameters.
Diffusion-GAN: Training GANs with Diffusion
Jun 05, 2022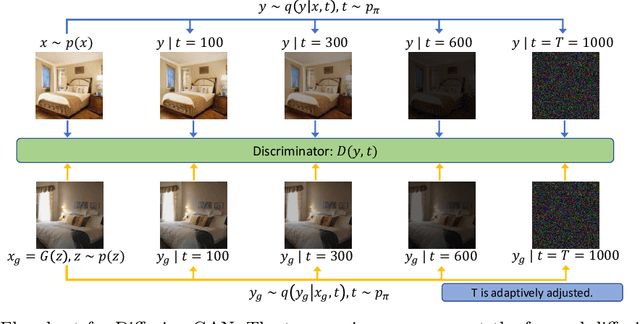
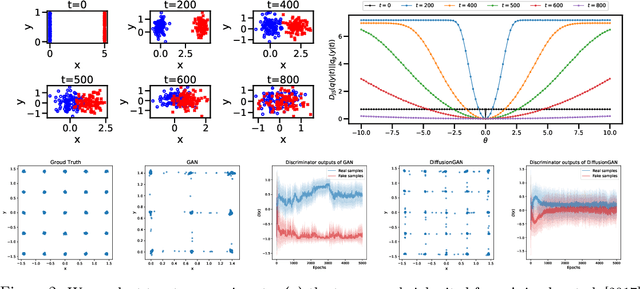

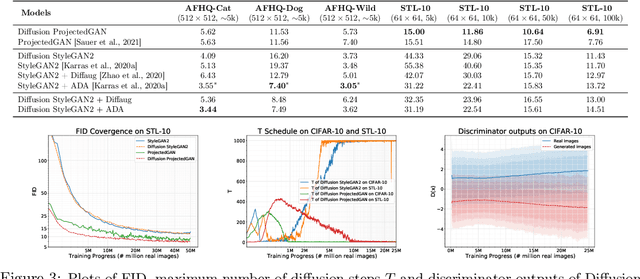
For stable training of generative adversarial networks (GANs), injecting instance noise into the input of the discriminator is considered as a theoretically sound solution, which, however, has not yet delivered on its promise in practice. This paper introduces Diffusion-GAN that employs a Gaussian mixture distribution, defined over all the diffusion steps of a forward diffusion chain, to inject instance noise. A random sample from the mixture, which is diffused from an observed or generated data, is fed as the input to the discriminator. The generator is updated by backpropagating its gradient through the forward diffusion chain, whose length is adaptively adjusted to control the maximum noise-to-data ratio allowed at each training step. Theoretical analysis verifies the soundness of the proposed Diffusion-GAN, which provides model- and domain-agnostic differentiable augmentation. A rich set of experiments on diverse datasets show that Diffusion-GAN can provide stable and data-efficient GAN training, bringing consistent performance improvement over strong GAN baselines for synthesizing photo-realistic images.