 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextDrag: Precise Drag-Based Image Editing via Context-Preserving Token Injection and Position-Consistent Attention
Dec 09, 2025Drag-based image editing aims to modify visual content followed by user-specified drag operations. Despite existing methods having made notable progress, they still fail to fully exploit the contextual information in the reference image, including fine-grained texture details, leading to edits with limited coherence and fidelity. To address this challenge, we introduce ContextDrag, a new paradigm for drag-based editing that leverages the strong contextual modeling capability of editing models, such as FLUX-Kontext. By incorporating VAE-encoded features from the reference image, ContextDrag can leverage rich contextual cues and preserve fine-grained details, without the need for finetuning or inversion. Specifically, ContextDrag introduced a novel Context-preserving Token Injection (CTI) that injects noise-free reference features into their correct destination locations via a Latent-space Reverse Mapping (LRM) algorithm. This strategy enables precise drag control while preserving consistency in both semantics and texture details. Second, ContextDrag adopts a novel Position-Consistent Attention (PCA), which positional re-encodes the reference tokens and applies overlap-aware masking to eliminate interference from irrelevant reference features. Extensive experiments on DragBench-SR and DragBench-DR demonstrate that our approach surpasses all existing SOTA methods. Code will be publicly available.
A Bilingual, OpenWorld Video Text Dataset and End-to-end Video Text Spotter with Transformer
Dec 09, 2021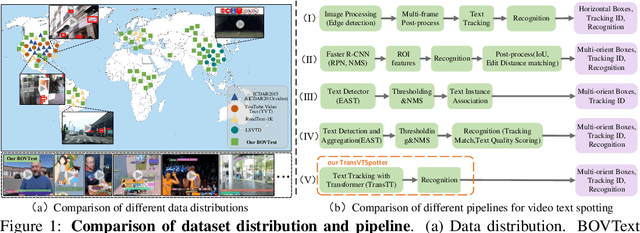
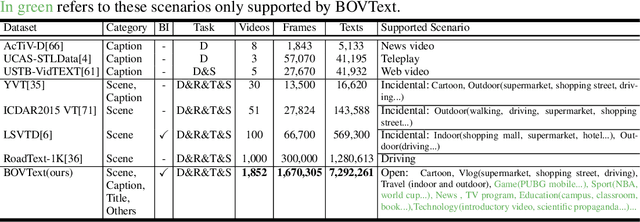

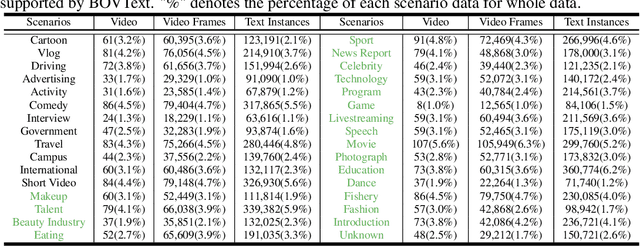
Most existing video text spotting benchmarks focus on evaluating a single language and scenario with limited data. In this work, we introduce a large-scale, Bilingual, Open World Video text benchmark dataset(BOVText). There are four features for BOVText. Firstly, we provide 2,000+ videos with more than 1,750,000+ frames, 25 times larger than the existing largest dataset with incidental text in videos. Secondly, our dataset covers 30+ open categories with a wide selection of various scenarios, e.g., Life Vlog, Driving, Movie, etc. Thirdly, abundant text types annotation (i.e., title, caption or scene text) are provided for the different representational meanings in video. Fourthly, the BOVText provides bilingual text annotation to promote multiple cultures live and communication. Besides, we propose an end-to-end video text spotting framework with Transformer, termed TransVTSpotter, which solves the multi-orient text spotting in video with a simple, but efficient attention-based query-key mechanism. It applies object features from the previous frame as a tracking query for the current frame and introduces a rotation angle prediction to fit the multiorient text instance. On ICDAR2015(video), TransVTSpotter achieves the state-of-the-art performance with 44.1% MOTA, 9 fps. The dataset and code of TransVTSpotter can be found at github:com=weijiawu=BOVText and github:com=weijiawu=TransVTSpotter, respectively.
* 20 pages, 6 figures