 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMSMP: A Novel Deep Neural Network Quantization Framework with Row-wise Mixed Schemes and Multiple Precisions
Oct 30, 2021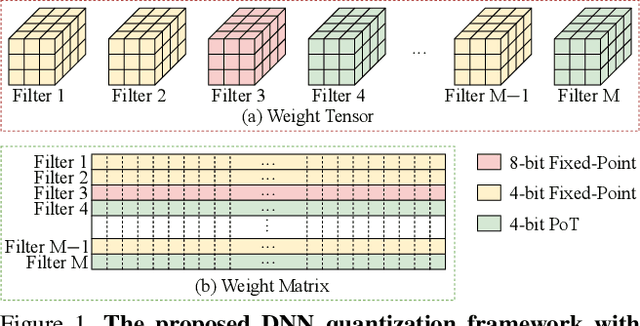
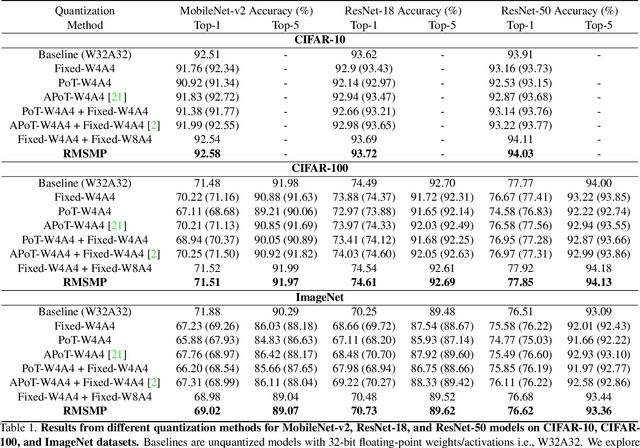
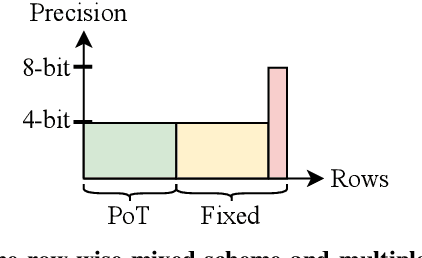
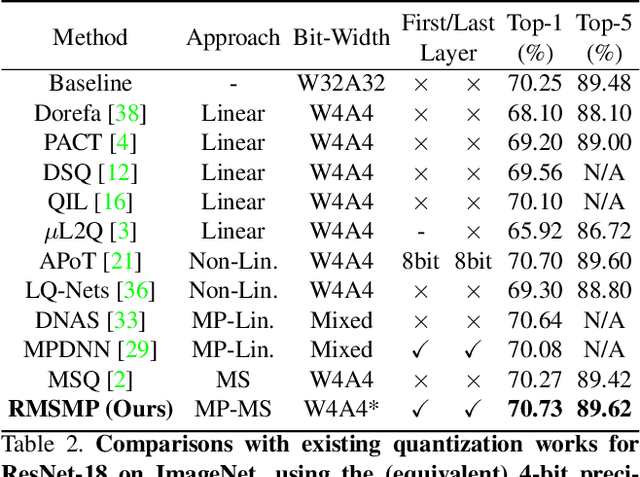
This work proposes a novel Deep Neural Network (DNN) quantization framework, namely RMSMP, with a Row-wise Mixed-Scheme and Multi-Precision approach. Specifically, this is the first effort to assign mixed quantization schemes and multiple precisions within layers -- among rows of the DNN weight matrix, for simplified operations in hardware inference, while preserving accuracy. Furthermore, this paper makes a different observation from the prior work that the quantization error does not necessarily exhibit the layer-wise sensitivity, and actually can be mitigated as long as a certain portion of the weights in every layer are in higher precisions. This observation enables layer-wise uniformality in the hardware implementation towards guaranteed inference acceleration, while still enjoying row-wise flexibility of mixed schemes and multiple precisions to boost accuracy. The candidates of schemes and precisions are derived practically and effectively with a highly hardware-informative strategy to reduce the problem search space. With the offline determined ratio of different quantization schemes and precisions for all the layers, the RMSMP quantization algorithm uses the Hessian and variance-based method to effectively assign schemes and precisions for each row. The proposed RMSMP is tested for the image classification and natural language processing (BERT) applications and achieves the best accuracy performance among state-of-the-arts under the same equivalent precisions. The RMSMP is implemented on FPGA devices, achieving 3.65x speedup in the end-to-end inference time for ResNet-18 on ImageNet, compared with the 4-bit Fixed-point baseline.
Detecting Gender Bias in Transformer-based Models: A Case Study on BERT
Oct 15, 2021
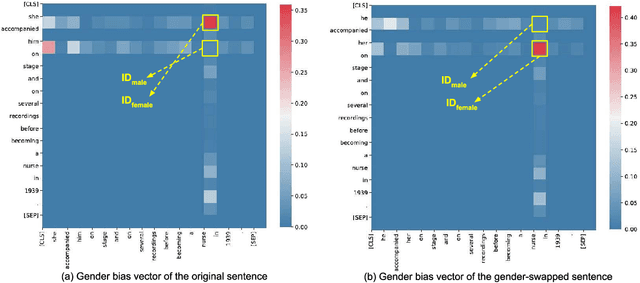
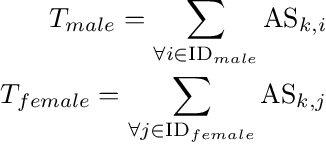
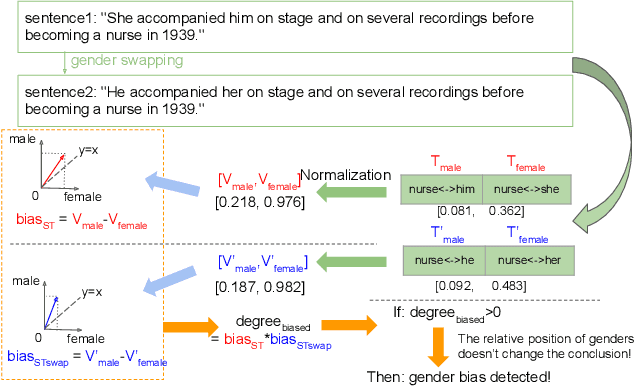
In this paper, we propose a novel gender bias detection method by utilizing attention map for transformer-based models. We 1) give an intuitive gender bias judgement method by comparing the different relation degree between the genders and the occupation according to the attention scores, 2) design a gender bias detector by modifying the attention module, 3) insert the gender bias detector into different positions of the model to present the internal gender bias flow, and 4) draw the consistent gender bias conclusion by scanning the entire Wikipedia, a BERT pretraining dataset. We observe that 1) the attention matrices, Wq and Wk introduce much more gender bias than other modules (including the embedding layer) and 2) the bias degree changes periodically inside of the model (attention matrix Q, K, V, and the remaining part of the attention layer (including the fully-connected layer, the residual connection, and the layer normalization module) enhance the gender bias while the averaged attentions reduces the bias).
RADARS: Memory Efficient Reinforcement Learning Aided Differentiable Neural Architecture Search
Sep 13, 2021



Differentiable neural architecture search (DNAS) is known for its capacity in the automatic generation of superior neural networks. However, DNAS based methods suffer from memory usage explosion when the search space expands, which may prevent them from running successfully on even advanced GPU platforms. On the other hand, reinforcement learning (RL) based methods, while being memory efficient, are extremely time-consuming. Combining the advantages of both types of methods, this paper presents RADARS, a scalable RL-aided DNAS framework that can explore large search spaces in a fast and memory-efficient manner. RADARS iteratively applies RL to prune undesired architecture candidates and identifies a promising subspace to carry out DNAS. Experiments using a workstation with 12 GB GPU memory show that on CIFAR-10 and ImageNet datasets, RADARS can achieve up to 3.41% higher accuracy with 2.5X search time reduction compared with a state-of-the-art RL-based method, while the two DNAS baselines cannot complete due to excessive memory usage or search time. To the best of the authors' knowledge, this is the first DNAS framework that can handle large search spaces with bounded memory usage.
Exploration of Quantum Neural Architecture by Mixing Quantum Neuron Designs
Sep 08, 2021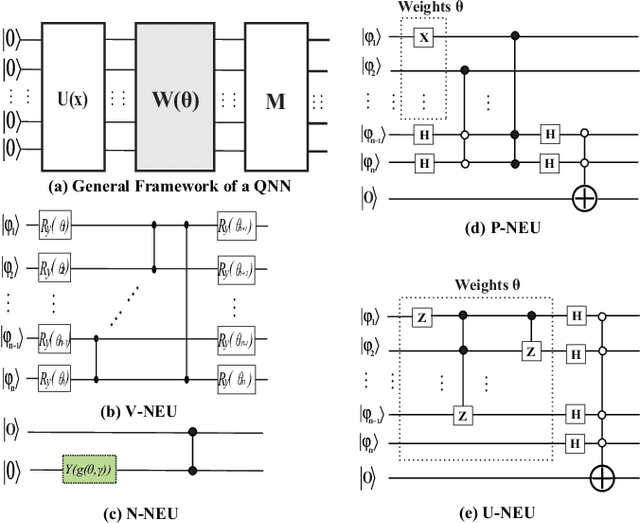

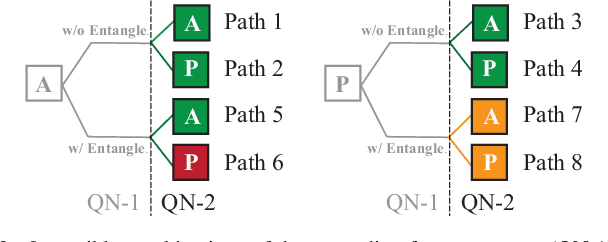
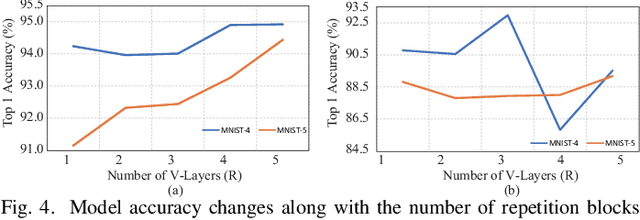
With the constant increase of the number of quantum bits (qubits) in the actual quantum computers, implementing and accelerating the prevalent deep learning on quantum computers are becoming possible. Along with this trend, there emerge quantum neural architectures based on different designs of quantum neurons. A fundamental question in quantum deep learning arises: what is the best quantum neural architecture? Inspired by the design of neural architectures for classical computing which typically employs multiple types of neurons, this paper makes the very first attempt to mix quantum neuron designs to build quantum neural architectures. We observe that the existing quantum neuron designs may be quite different but complementary, such as neurons from variation quantum circuits (VQC) and Quantumflow. More specifically, VQC can apply real-valued weights but suffer from being extended to multiple layers, while QuantumFlow can build a multi-layer network efficiently, but is limited to use binary weights. To take their respective advantages, we propose to mix them together and figure out a way to connect them seamlessly without additional costly measurement. We further investigate the design principles to mix quantum neurons, which can provide guidance for quantum neural architecture exploration in the future. Experimental results demonstrate that the identified quantum neural architectures with mixed quantum neurons can achieve 90.62% of accuracy on the MNIST dataset, compared with 52.77% and 69.92% on the VQC and QuantumFlow, respectively.
Can Noise on Qubits Be Learned in Quantum Neural Network? A Case Study on QuantumFlow
Sep 08, 2021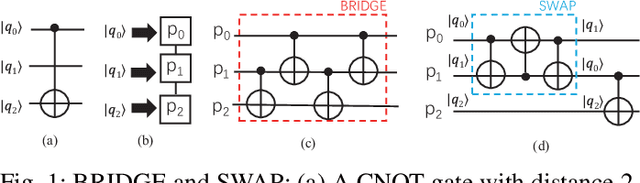
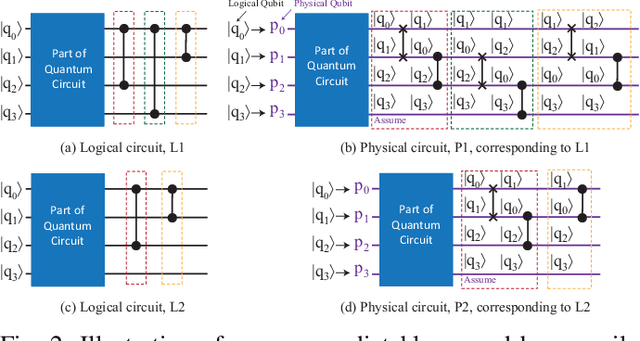
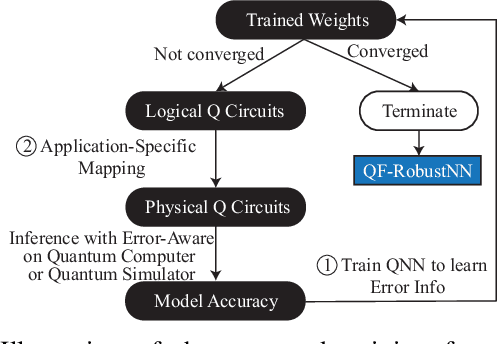
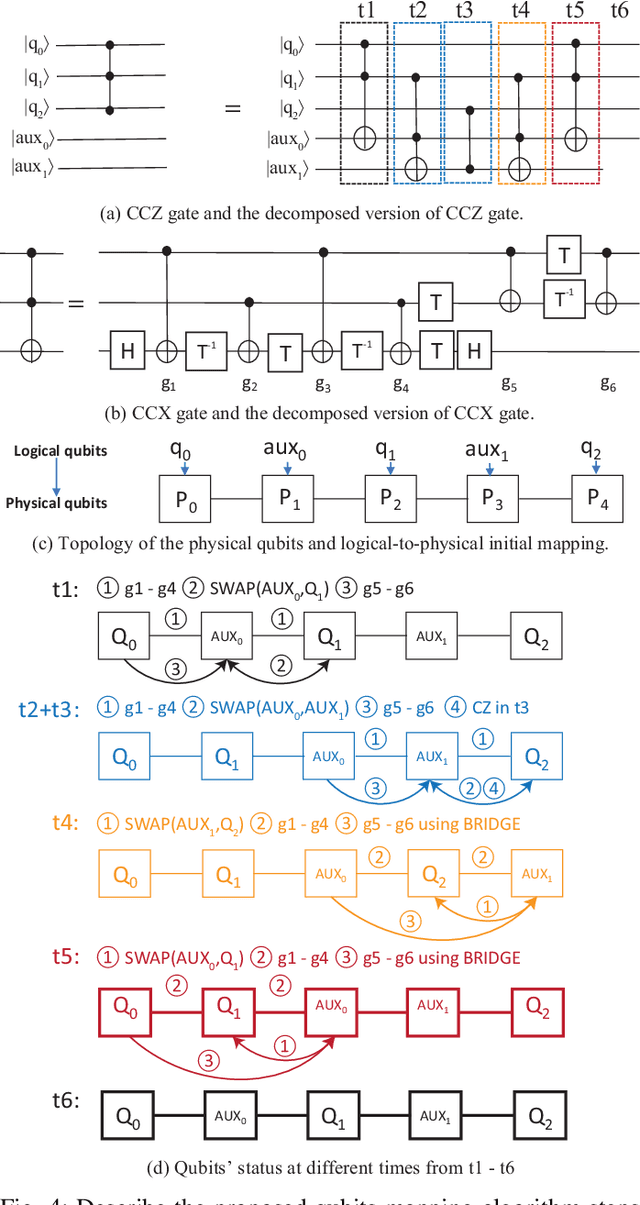
In the noisy intermediate-scale quantum (NISQ) era, one of the key questions is how to deal with the high noise level existing in physical quantum bits (qubits). Quantum error correction is promising but requires an extensive number (e.g., over 1,000) of physical qubits to create one "perfect" qubit, exceeding the capacity of the existing quantum computers. This paper aims to tackle the noise issue from another angle: instead of creating perfect qubits for general quantum algorithms, we investigate the potential to mitigate the noise issue for dedicate algorithms. Specifically, this paper targets quantum neural network (QNN), and proposes to learn the errors in the training phase, so that the identified QNN model can be resilient to noise. As a result, the implementation of QNN needs no or a small number of additional physical qubits, which is more realistic for the near-term quantum computers. To achieve this goal, an application-specific compiler is essential: on the one hand, the error cannot be learned if the mapping from logical qubits to physical qubits exists randomness; on the other hand, the compiler needs to be efficient so that the lengthy training procedure can be completed in a reasonable time. In this paper, we utilize the recent QNN framework, QuantumFlow, as a case study. Experimental results show that the proposed approach can optimize QNN models for different errors in qubits, achieving up to 28% accuracy improvement compared with the model obtained by the error-agnostic training.
A Compression-Compilation Framework for On-mobile Real-time BERT Applications
Jun 06, 2021


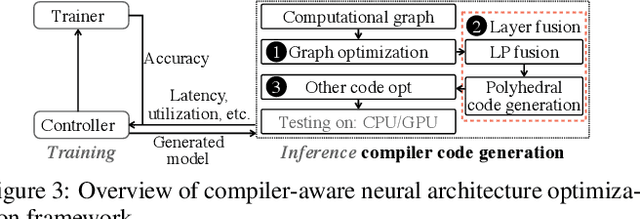
Transformer-based deep learning models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. In this paper, we propose a compression-compilation co-design framework that can guarantee the identified model to meet both resource and real-time specifications of mobile devices. Our framework applies a compiler-aware neural architecture optimization method (CANAO), which can generate the optimal compressed model that balances both accuracy and latency. We are able to achieve up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss. We present two types of BERT applications on mobile devices: Question Answering (QA) and Text Generation. Both can be executed in real-time with latency as low as 45ms. Videos for demonstrating the framework can be found on https://www.youtube.com/watch?v=_WIRvK_2PZI
Dancing along Battery: Enabling Transformer with Run-time Reconfigurability on Mobile Devices
Feb 12, 2021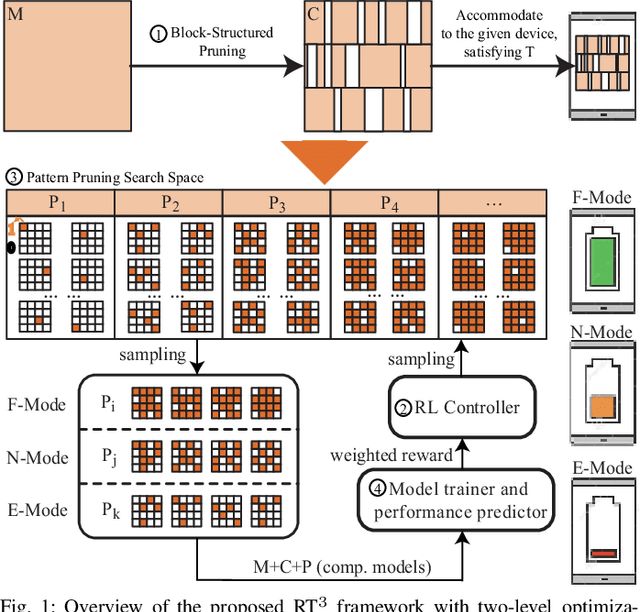
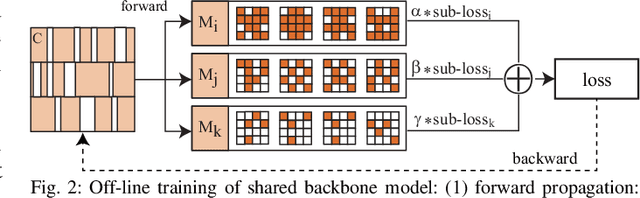
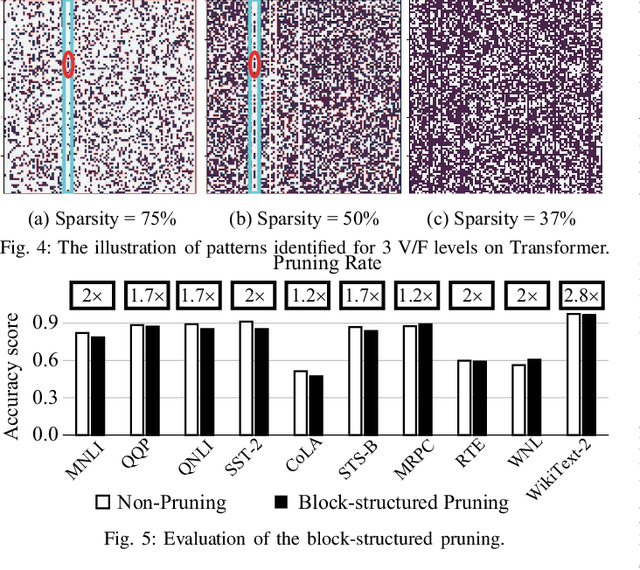

A pruning-based AutoML framework for run-time reconfigurability, namely RT3, is proposed in this work. This enables Transformer-based large Natural Language Processing (NLP) models to be efficiently executed on resource-constrained mobile devices and reconfigured (i.e., switching models for dynamic hardware conditions) at run-time. Such reconfigurability is the key to save energy for battery-powered mobile devices, which widely use dynamic voltage and frequency scaling (DVFS) technique for hardware reconfiguration to prolong battery life. In this work, we creatively explore a hybrid block-structured pruning (BP) and pattern pruning (PP) for Transformer-based models and first attempt to combine hardware and software reconfiguration to maximally save energy for battery-powered mobile devices. Specifically, RT3 integrates two-level optimizations: First, it utilizes an efficient BP as the first-step compression for resource-constrained mobile devices; then, RT3 heuristically generates a shrunken search space based on the first level optimization and searches multiple pattern sets with diverse sparsity for PP via reinforcement learning to support lightweight software reconfiguration, which corresponds to available frequency levels of DVFS (i.e., hardware reconfiguration). At run-time, RT3 can switch the lightweight pattern sets within 45ms to guarantee the required real-time constraint at different frequency levels. Results further show that RT3 can prolong battery life over 4x improvement with less than 1% accuracy loss for Transformer and 1.5% score decrease for DistilBERT.
When Machine Learning Meets Quantum Computers: A Case Study
Dec 18, 2020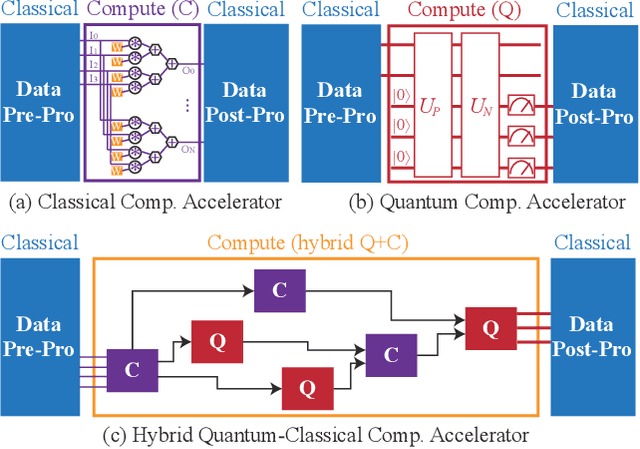
Along with the development of AI democratization, the machine learning approach, in particular neural networks, has been applied to wide-range applications. In different application scenarios, the neural network will be accelerated on the tailored computing platform. The acceleration of neural networks on classical computing platforms, such as CPU, GPU, FPGA, ASIC, has been widely studied; however, when the scale of the application consistently grows up, the memory bottleneck becomes obvious, widely known as memory-wall. In response to such a challenge, advanced quantum computing, which can represent 2^N states with N quantum bits (qubits), is regarded as a promising solution. It is imminent to know how to design the quantum circuit for accelerating neural networks. Most recently, there are initial works studying how to map neural networks to actual quantum processors. To better understand the state-of-the-art design and inspire new design methodology, this paper carries out a case study to demonstrate an end-to-end implementation. On the neural network side, we employ the multilayer perceptron to complete image classification tasks using the standard and widely used MNIST dataset. On the quantum computing side, we target IBM Quantum processors, which can be programmed and simulated by using IBM Qiskit. This work targets the acceleration of the inference phase of a trained neural network on the quantum processor. Along with the case study, we will demonstrate the typical procedure for mapping neural networks to quantum circuits.
DNA: Differentiable Network-Accelerator Co-Search
Oct 28, 2020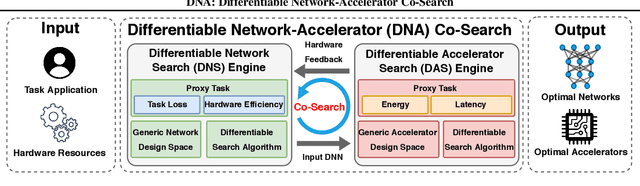

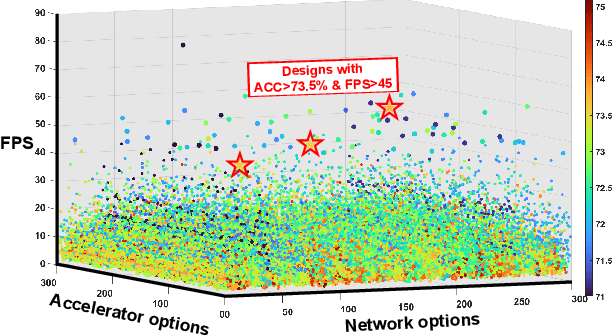
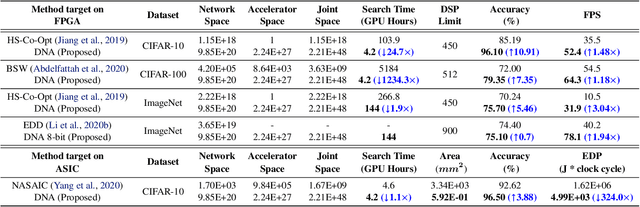
Powerful yet complex deep neural networks (DNNs) have fueled a booming demand for efficient DNN solutions to bring DNN-powered intelligence into numerous applications. Jointly optimizing the networks and their accelerators are promising in providing optimal performance. However, the great potential of such solutions have yet to be unleashed due to the challenge of simultaneously exploring the vast and entangled, yet different design spaces of the networks and their accelerators. To this end, we propose DNA, a Differentiable Network-Accelerator co-search framework for automatically searching for matched networks and accelerators to maximize both the task accuracy and acceleration efficiency. Specifically, DNA integrates two enablers: (1) a generic design space for DNN accelerators that is applicable to both FPGA- and ASIC-based DNN accelerators and compatible with DNN frameworks such as PyTorch to enable algorithmic exploration for more efficient DNNs and their accelerators; and (2) a joint DNN network and accelerator co-search algorithm that enables simultaneously searching for optimal DNN structures and their accelerators' micro-architectures and mapping methods to maximize both the task accuracy and acceleration efficiency. Experiments and ablation studies based on FPGA measurements and ASIC synthesis show that the matched networks and accelerators generated by DNA consistently outperform state-of-the-art (SOTA) DNNs and DNN accelerators (e.g., 3.04x better FPS with a 5.46% higher accuracy on ImageNet), while requiring notably reduced search time (up to 1234.3x) over SOTA co-exploration methods, when evaluated over ten SOTA baselines on three datasets. All codes will be released upon acceptance.
MSP: An FPGA-Specific Mixed-Scheme, Multi-Precision Deep Neural Network Quantization Framework
Sep 16, 2020
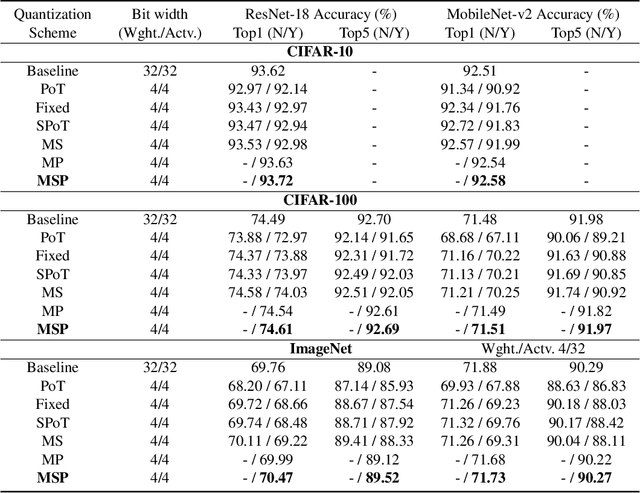
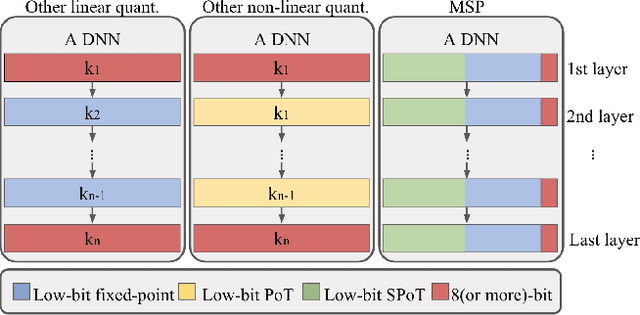
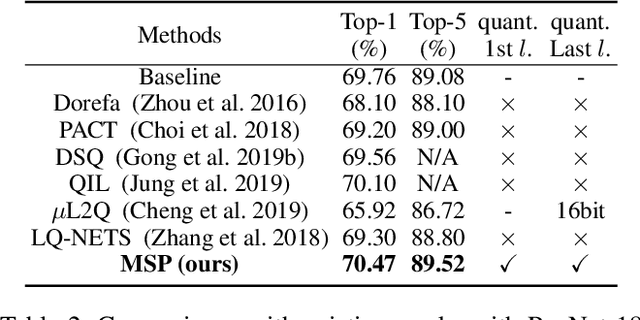
With the tremendous success of deep learning, there exists imminent need to deploy deep learning models onto edge devices. To tackle the limited computing and storage resources in edge devices, model compression techniques have been widely used to trim deep neural network (DNN) models for on-device inference execution. This paper targets the commonly used FPGA (field programmable gate array) devices as the hardware platforms for DNN edge computing. We focus on the DNN quantization as the main model compression technique, since DNN quantization has been of great importance for the implementations of DNN models on the hardware platforms. The novelty of this work comes in twofold: (i) We propose a mixed-scheme DNN quantization method that incorporates both the linear and non-linear number systems for quantization, with the aim to boost the utilization of the heterogeneous computing resources, i.e., LUTs (look up tables) and DSPs (digital signal processors) on an FPGA. Note that all the existing (single-scheme) quantization methods can only utilize one type of resources (either LUTs or DSPs for the MAC (multiply-accumulate) operations in deep learning computations. (ii) We use a quantization method that supports multiple precisions along the intra-layer dimension, while the existing quantization methods apply multi-precision quantization along the inter-layer dimension. The intra-layer multi-precision method can uniform the hardware configurations for different layers to reduce computation overhead and at the same time preserve the model accuracy as the inter-layer approach.