 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint2Insert: Video Object Insertion via Sparse Point Guidance
Feb 04, 2026This paper introduces Point2Insert, a sparse-point-based framework for flexible and user-friendly object insertion in videos, motivated by the growing popularity of accurate, low-effort object placement. Existing approaches face two major challenges: mask-based insertion methods require labor-intensive mask annotations, while instruction-based methods struggle to place objects at precise locations. Point2Insert addresses these issues by requiring only a small number of sparse points instead of dense masks, eliminating the need for tedious mask drawing. Specifically, it supports both positive and negative points to indicate regions that are suitable or unsuitable for insertion, enabling fine-grained spatial control over object locations. The training of Point2Insert consists of two stages. In Stage 1, we train an insertion model that generates objects in given regions conditioned on either sparse-point prompts or a binary mask. In Stage 2, we further train the model on paired videos synthesized by an object removal model, adapting it to video insertion. Moreover, motivated by the higher insertion success rate of mask-guided editing, we leverage a mask-guided insertion model as a teacher to distill reliable insertion behavior into the point-guided model. Extensive experiments demonstrate that Point2Insert consistently outperforms strong baselines and even surpasses models with $\times$10 more parameters.
Class Incremental Learning with Task-Specific Batch Normalization and Out-of-Distribution Detection
Nov 01, 2024



This study focuses on incremental learning for image classification, exploring how to reduce catastrophic forgetting of all learned knowledge when access to old data is restricted due to memory or privacy constraints. The challenge of incremental learning lies in achieving an optimal balance between plasticity, the ability to learn new knowledge, and stability, the ability to retain old knowledge. Based on whether the task identifier (task-ID) of an image can be obtained during the test stage, incremental learning for image classifcation is divided into two main paradigms, which are task incremental learning (TIL) and class incremental learning (CIL). The TIL paradigm has access to the task-ID, allowing it to use multiple task-specific classification heads selected based on the task-ID. Consequently, in CIL, where the task-ID is unavailable, TIL methods must predict the task-ID to extend their application to the CIL paradigm. Our previous method for TIL adds task-specific batch normalization and classification heads incrementally. This work extends the method by predicting task-ID through an "unknown" class added to each classification head. The head with the lowest "unknown" probability is selected, enabling task-ID prediction and making the method applicable to CIL. The task-specific batch normalization (BN) modules effectively adjust the distribution of output feature maps across different tasks, enhancing the model's plasticity.Moreover, since BN has much fewer parameters compared to convolutional kernels, by only modifying the BN layers as new tasks arrive, the model can effectively manage parameter growth while ensuring stability across tasks. The innovation of this study lies in the first-time introduction of task-specific BN into CIL and verifying the feasibility of extending TIL methods to CIL through task-ID prediction with state-of-the-art performance on multiple datasets.
Classifier-head Informed Feature Masking and Prototype-based Logit Smoothing for Out-of-Distribution Detection
Oct 27, 2023Out-of-distribution (OOD) detection is essential when deploying neural networks in the real world. One main challenge is that neural networks often make overconfident predictions on OOD data. In this study, we propose an effective post-hoc OOD detection method based on a new feature masking strategy and a novel logit smoothing strategy. Feature masking determines the important features at the penultimate layer for each in-distribution (ID) class based on the weights of the ID class in the classifier head and masks the rest features. Logit smoothing computes the cosine similarity between the feature vector of the test sample and the prototype of the predicted ID class at the penultimate layer and uses the similarity as an adaptive temperature factor on the logit to alleviate the network's overconfidence prediction for OOD data. With these strategies, we can reduce feature activation of OOD data and enlarge the gap in OOD score between ID and OOD data. Extensive experiments on multiple standard OOD detection benchmarks demonstrate the effectiveness of our method and its compatibility with existing methods, with new state-of-the-art performance achieved from our method. The source code will be released publicly.
PAMI: partition input and aggregate outputs for model interpretation
Feb 08, 2023



There is an increasing demand for interpretation of model predictions especially in high-risk applications. Various visualization approaches have been proposed to estimate the part of input which is relevant to a specific model prediction. However, most approaches require model structure and parameter details in order to obtain the visualization results, and in general much effort is required to adapt each approach to multiple types of tasks particularly when model backbone and input format change over tasks. In this study, a simple yet effective visualization framework called PAMI is proposed based on the observation that deep learning models often aggregate features from local regions for model predictions. The basic idea is to mask majority of the input and use the corresponding model output as the relative contribution of the preserved input part to the original model prediction. For each input, since only a set of model outputs are collected and aggregated, PAMI does not require any model detail and can be applied to various prediction tasks with different model backbones and input formats. Extensive experiments on multiple tasks confirm the proposed method performs better than existing visualization approaches in more precisely finding class-specific input regions, and when applied to different model backbones and input formats. The source code will be released publicly.
Prompt-based Learning for Unpaired Image Captioning
May 26, 2022
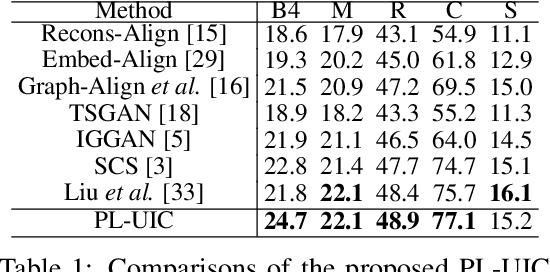
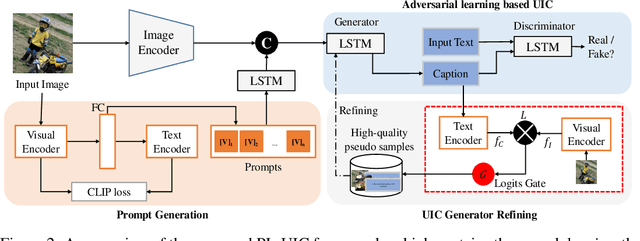
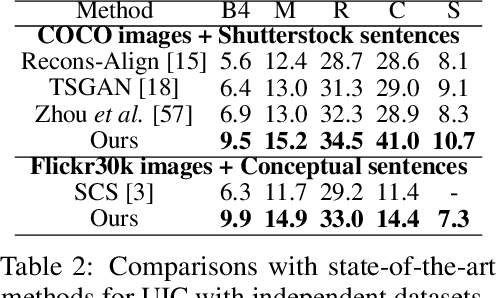
Unpaired Image Captioning (UIC) has been developed to learn image descriptions from unaligned vision-language sample pairs. Existing schemes usually adopt the visual concept reward of reinforcement learning to obtain the alignment between visual concepts and images. However, the cross-domain alignment is usually weak that severely constrains the overall performance of these existing schemes. Recent successes of Vision-Language Pre-Trained Models (VL-PTMs) have triggered the development of prompt-based learning from VL-PTMs. We present in this paper a novel scheme based on prompt to train the UIC model, making best use of the powerful generalization ability and abundant vision-language prior knowledge learned under VL-PTMs. We adopt the CLIP model for this research in unpaired image captioning. Specifically, the visual images are taken as input to the prompt generation module, which contains the pre-trained model as well as one feed-forward layer for prompt extraction. Then, the input images and generated prompts are aggregated for unpaired adversarial captioning learning. To further enhance the potential performance of the captioning, we designed a high-quality pseudo caption filter guided by the CLIP logits to measure correlations between predicted captions and the corresponding images. This allows us to improve the captioning model in a supervised learning manner. Extensive experiments on the COCO and Flickr30K datasets have been carried out to validate the superiority of the proposed model. We have achieved the state-of-the-art performance on the COCO dataset, which outperforms the best UIC model by 1.9% on the BLEU-4 metric. We expect that the proposed prompt-based UIC model will inspire a new line of research for the VL-PTMs based captioning.
SATS: Self-Attention Transfer for Continual Semantic Segmentation
Mar 15, 2022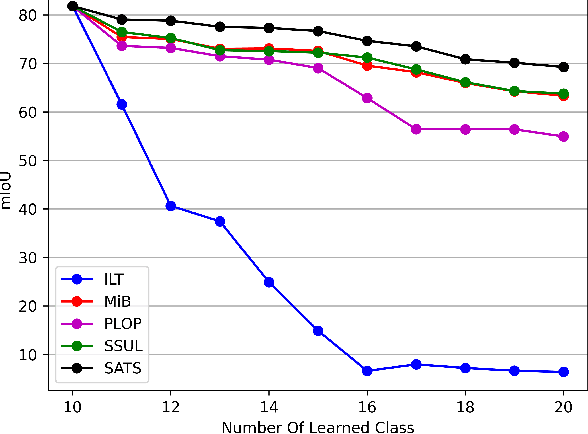
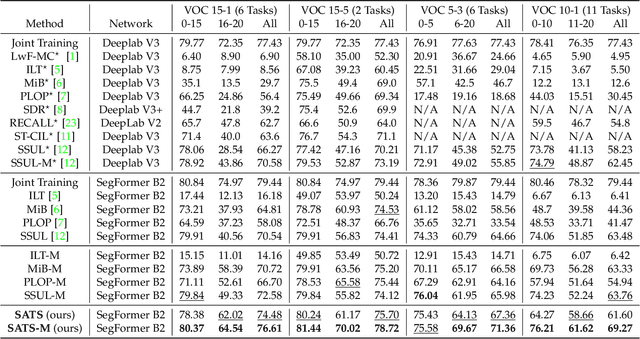
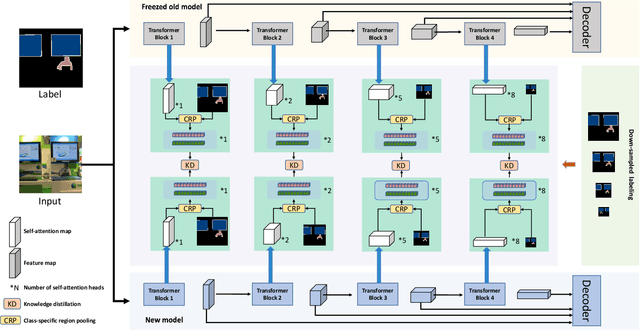
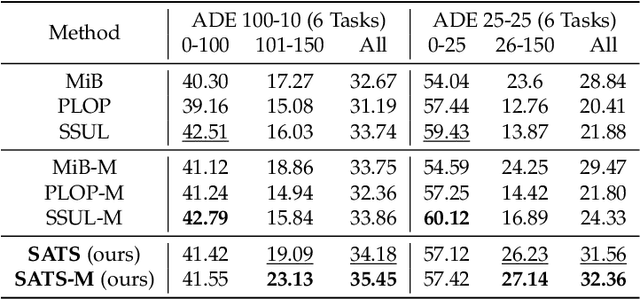
Continually learning to segment more and more types of image regions is a desired capability for many intelligent systems. However, such continual semantic segmentation suffers from the same catastrophic forgetting issue as in continual classification learning. While multiple knowledge distillation strategies originally for continual classification have been well adapted to continual semantic segmentation, they only consider transferring old knowledge based on the outputs from one or more layers of deep fully convolutional networks. Different from existing solutions, this study proposes to transfer a new type of information relevant to knowledge, i.e. the relationships between elements (Eg. pixels or small local regions) within each image which can capture both within-class and between-class knowledge. The relationship information can be effectively obtained from the self-attention maps in a Transformer-style segmentation model. Considering that pixels belonging to the same class in each image often share similar visual properties, a class-specific region pooling is applied to provide more efficient relationship information for knowledge transfer. Extensive evaluations on multiple public benchmarks support that the proposed self-attention transfer method can further effectively alleviate the catastrophic forgetting issue, and its flexible combination with one or more widely adopted strategies significantly outperforms state-of-the-art solu
Viewpoint-Aware Loss with Angular Regularization for Person Re-Identification
Dec 03, 2019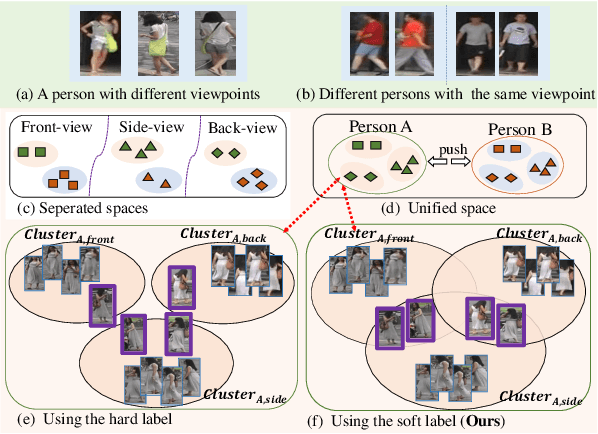
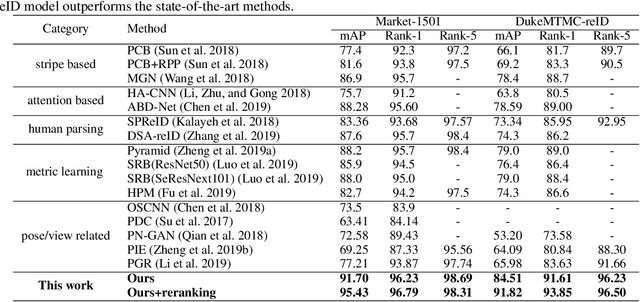
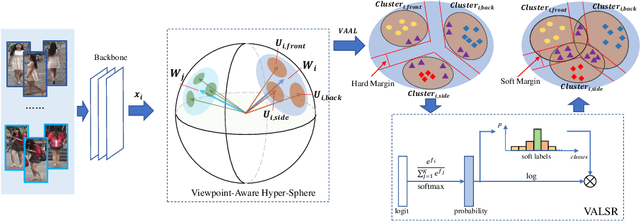
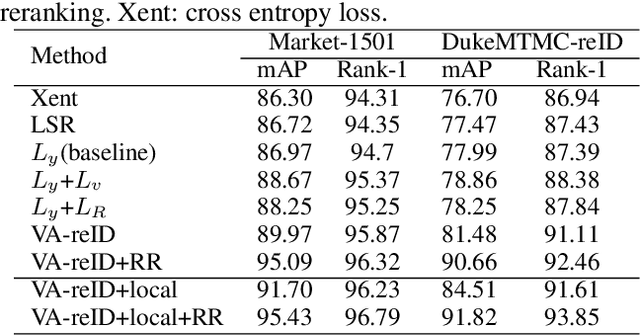
Although great progress in supervised person re-identification (Re-ID) has been made recently, due to the viewpoint variation of a person, Re-ID remains a massive visual challenge. Most existing viewpoint-based person Re-ID methods project images from each viewpoint into separated and unrelated sub-feature spaces. They only model the identity-level distribution inside an individual viewpoint but ignore the underlying relationship between different viewpoints. To address this problem, we propose a novel approach, called \textit{Viewpoint-Aware Loss with Angular Regularization }(\textbf{VA-reID}). Instead of one subspace for each viewpoint, our method projects the feature from different viewpoints into a unified hypersphere and effectively models the feature distribution on both the identity-level and the viewpoint-level. In addition, rather than modeling different viewpoints as hard labels used for conventional viewpoint classification, we introduce viewpoint-aware adaptive label smoothing regularization (VALSR) that assigns the adaptive soft label to feature representation. VALSR can effectively solve the ambiguity of the viewpoint cluster label assignment. Extensive experiments on the Market1501 and DukeMTMC-reID datasets demonstrated that our method outperforms the state-of-the-art supervised Re-ID methods.
Rethinking Temporal Fusion for Video-based Person Re-identification on Semantic and Time Aspect
Nov 28, 2019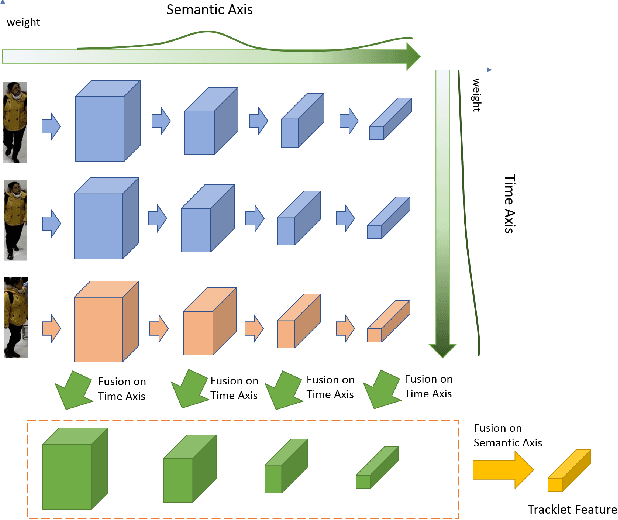
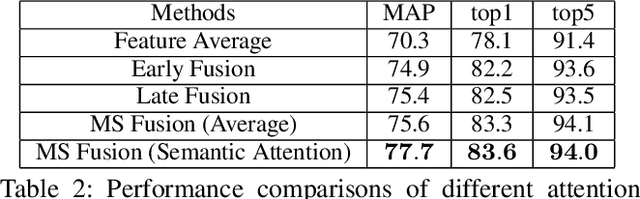
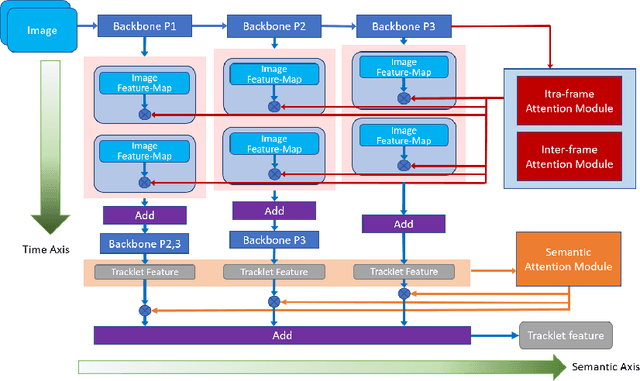
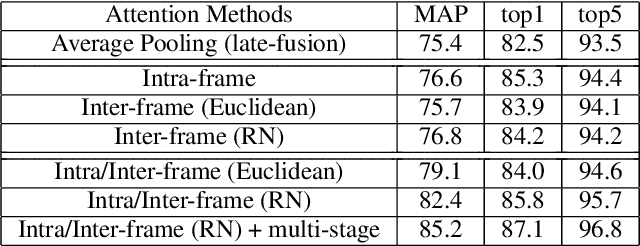
Recently, the research interest of person re-identification (ReID) has gradually turned to video-based methods, which acquire a person representation by aggregating frame features of an entire video. However, existing video-based ReID methods do not consider the semantic difference brought by the outputs of different network stages, which potentially compromises the information richness of the person features. Furthermore, traditional methods ignore important relationship among frames, which causes information redundancy in fusion along the time axis. To address these issues, we propose a novel general temporal fusion framework to aggregate frame features on both semantic aspect and time aspect. As for the semantic aspect, a multi-stage fusion network is explored to fuse richer frame features at multiple semantic levels, which can effectively reduce the information loss caused by the traditional single-stage fusion. While, for the time axis, the existing intra-frame attention method is improved by adding a novel inter-frame attention module, which effectively reduces the information redundancy in temporal fusion by taking the relationship among frames into consideration. The experimental results show that our approach can effectively improve the video-based re-identification accuracy, achieving the state-of-the-art performance.
Pedestrian re-identification based on Tree branch network with local and global learning
Mar 31, 2019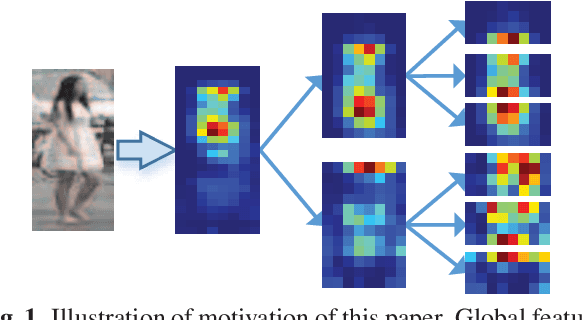
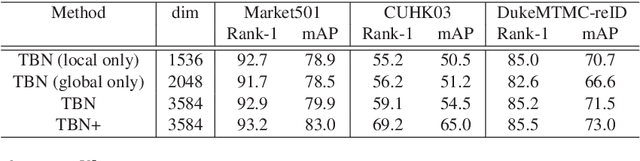
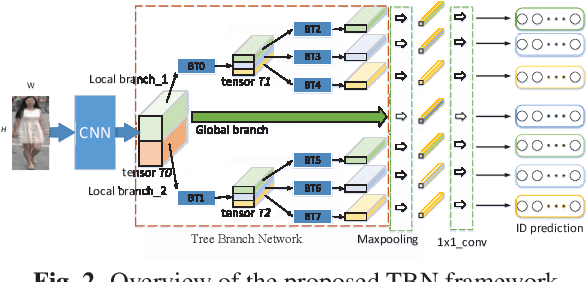
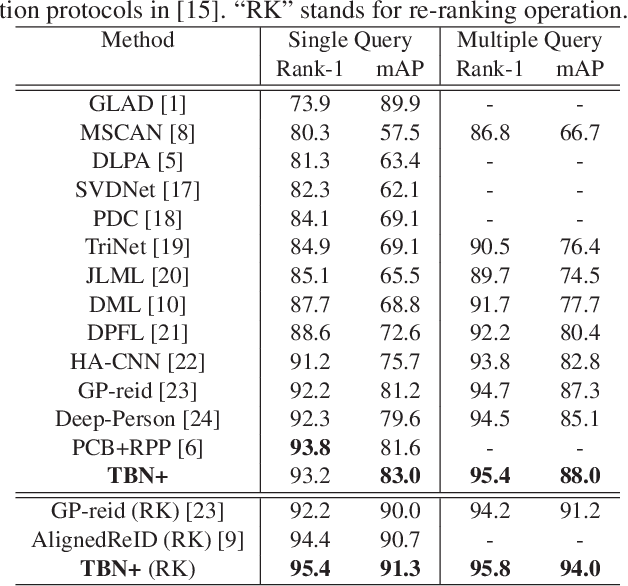
Deep part-based methods in recent literature have revealed the great potential of learning local part-level representation for pedestrian image in the task of person re-identification. However, global features that capture discriminative holistic information of human body are usually ignored or not well exploited. This motivates us to investigate joint learning global and local features from pedestrian images. Specifically, in this work, we propose a novel framework termed tree branch network (TBN) for person re-identification. Given a pedestrain image, the feature maps generated by the backbone CNN, are partitioned recursively into several pieces, each of which is followed by a bottleneck structure that learns finer-grained features for each level in the hierarchical tree-like framework. In this way, representations are learned in a coarse-to-fine manner and finally assembled to produce more discriminative image descriptions. Experimental results demonstrate the effectiveness of the global and local feature learning method in the proposed TBN framework. We also show significant improvement in performance over state-of-the-art methods on three public benchmarks: Market-1501, CUHK-03 and DukeMTMC.
Accelerating Large Scale Knowledge Distillation via Dynamic Importance Sampling
Dec 03, 2018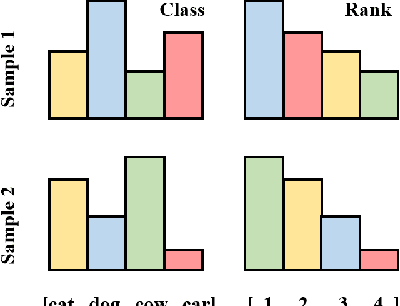
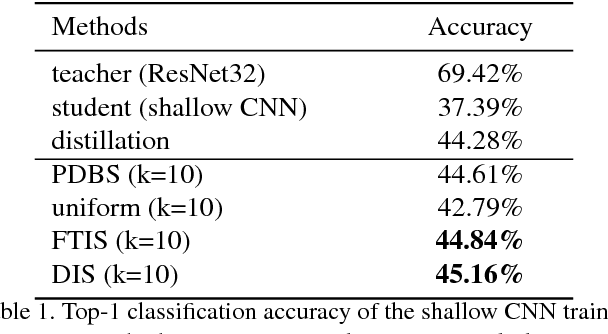
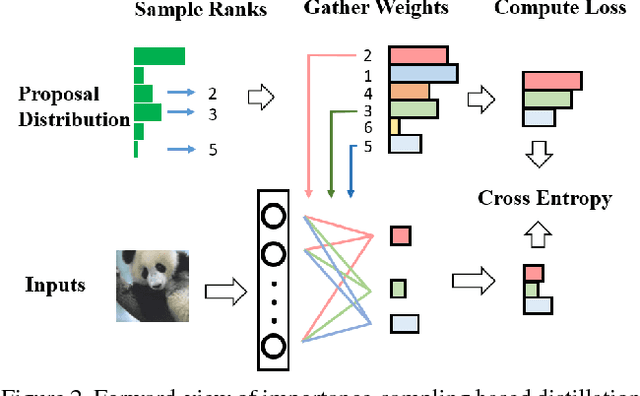
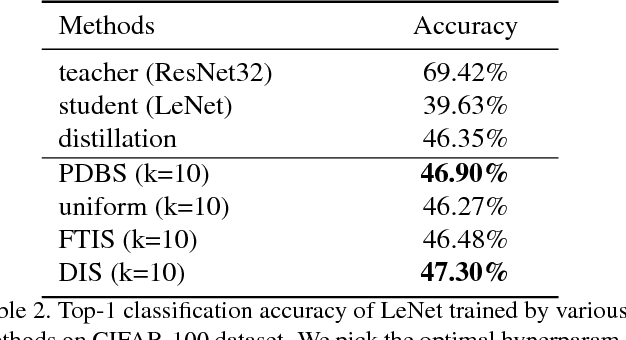
Knowledge distillation is an effective technique that transfers knowledge from a large teacher model to a shallow student. However, just like massive classification, large scale knowledge distillation also imposes heavy computational costs on training models of deep neural networks, as the softmax activations at the last layer involve computing probabilities over numerous classes. In this work, we apply the idea of importance sampling which is often used in Neural Machine Translation on large scale knowledge distillation. We present a method called dynamic importance sampling, where ranked classes are sampled from a dynamic distribution derived from the interaction between the teacher and student in full distillation. We highlight the utility of our proposal prior which helps the student capture the main information in the loss function. Our approach manages to reduce the computational cost at training time while maintaining the competitive performance on CIFAR-100 and Market-1501 person re-identification datasets.