 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Disentanglement for Referring Multi-Object Tracking
Mar 14, 2025



As a significant application of multi-source information fusion in intelligent transportation perception systems, Referring Multi-Object Tracking (RMOT) involves localizing and tracking specific objects in video sequences based on language references. However, existing RMOT approaches often treat language descriptions as holistic embeddings and struggle to effectively integrate the rich semantic information contained in language expressions with visual features. This limitation is especially apparent in complex scenes requiring comprehensive understanding of both static object attributes and spatial motion information. In this paper, we propose a Cognitive Disentanglement for Referring Multi-Object Tracking (CDRMT) framework that addresses these challenges. It adapts the "what" and "where" pathways from human visual processing system to RMOT tasks. Specifically, our framework comprises three collaborative components: (1)The Bidirectional Interactive Fusion module first establishes cross-modal connections while preserving modality-specific characteristics; (2) Building upon this foundation, the Progressive Semantic-Decoupled Query Learning mechanism hierarchically injects complementary information into object queries, progressively refining object understanding from coarse to fine-grained semantic levels; (3) Finally, the Structural Consensus Constraint enforces bidirectional semantic consistency between visual features and language descriptions, ensuring that tracked objects faithfully reflect the referring expression. Extensive experiments on different benchmark datasets demonstrate that CDRMT achieves substantial improvements over state-of-the-art methods, with average gains of 6.0% in HOTA score on Refer-KITTI and 3.2% on Refer-KITTI-V2. Our approach advances the state-of-the-art in RMOT while simultaneously providing new insights into multi-source information fusion.
Machine learning for modelling unstructured grid data in computational physics: a review
Feb 13, 2025
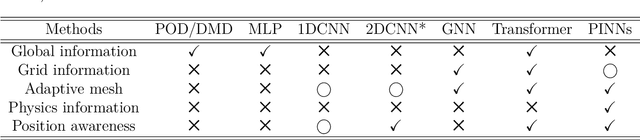
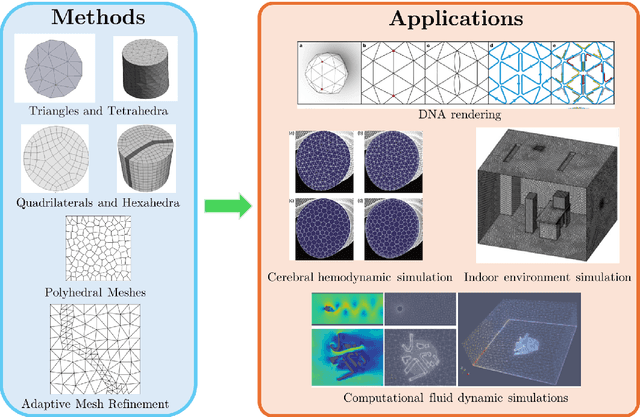

Unstructured grid data are essential for modelling complex geometries and dynamics in computational physics. Yet, their inherent irregularity presents significant challenges for conventional machine learning (ML) techniques. This paper provides a comprehensive review of advanced ML methodologies designed to handle unstructured grid data in high-dimensional dynamical systems. Key approaches discussed include graph neural networks, transformer models with spatial attention mechanisms, interpolation-integrated ML methods, and meshless techniques such as physics-informed neural networks. These methodologies have proven effective across diverse fields, including fluid dynamics and environmental simulations. This review is intended as a guidebook for computational scientists seeking to apply ML approaches to unstructured grid data in their domains, as well as for ML researchers looking to address challenges in computational physics. It places special focus on how ML methods can overcome the inherent limitations of traditional numerical techniques and, conversely, how insights from computational physics can inform ML development. To support benchmarking, this review also provides a summary of open-access datasets of unstructured grid data in computational physics. Finally, emerging directions such as generative models with unstructured data, reinforcement learning for mesh generation, and hybrid physics-data-driven paradigms are discussed to inspire future advancements in this evolving field.
Fuzzy Granule Density-Based Outlier Detection with Multi-Scale Granular Balls
Jan 06, 2025



Outlier detection refers to the identification of anomalous samples that deviate significantly from the distribution of normal data and has been extensively studied and used in a variety of practical tasks. However, most unsupervised outlier detection methods are carefully designed to detect specified outliers, while real-world data may be entangled with different types of outliers. In this study, we propose a fuzzy rough sets-based multi-scale outlier detection method to identify various types of outliers. Specifically, a novel fuzzy rough sets-based method that integrates relative fuzzy granule density is first introduced to improve the capability of detecting local outliers. Then, a multi-scale view generation method based on granular-ball computing is proposed to collaboratively identify group outliers at different levels of granularity. Moreover, reliable outliers and inliers determined by the three-way decision are used to train a weighted support vector machine to further improve the performance of outlier detection. The proposed method innovatively transforms unsupervised outlier detection into a semi-supervised classification problem and for the first time explores the fuzzy rough sets-based outlier detection from the perspective of multi-scale granular balls, allowing for high adaptability to different types of outliers. Extensive experiments carried out on both artificial and UCI datasets demonstrate that the proposed outlier detection method significantly outperforms the state-of-the-art methods, improving the results by at least 8.48% in terms of the Area Under the ROC Curve (AUROC) index. { The source codes are released at \url{https://github.com/Xiaofeng-Tan/MGBOD}. }
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024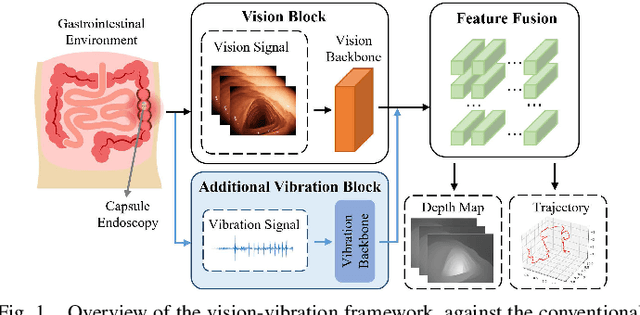
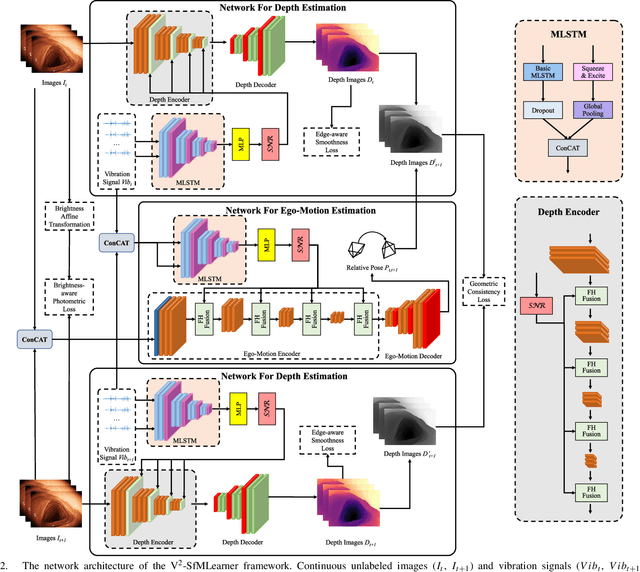
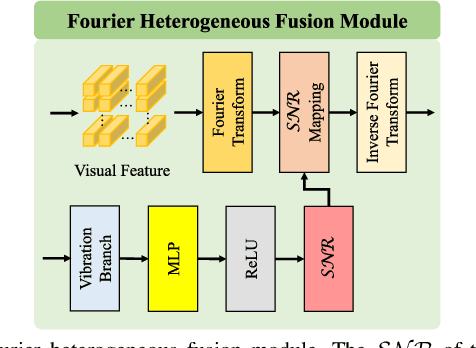
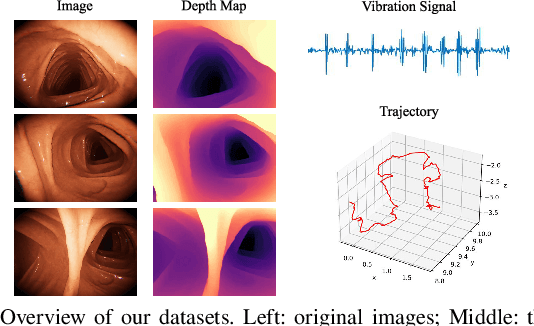
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.
Visual-Semantic Graph Matching Net for Zero-Shot Learning
Nov 18, 2024Zero-shot learning (ZSL) aims to leverage additional semantic information to recognize unseen classes. To transfer knowledge from seen to unseen classes, most ZSL methods often learn a shared embedding space by simply aligning visual embeddings with semantic prototypes. However, methods trained under this paradigm often struggle to learn robust embedding space because they align the two modalities in an isolated manner among classes, which ignore the crucial class relationship during the alignment process. To address the aforementioned challenges, this paper proposes a Visual-Semantic Graph Matching Net, termed as VSGMN, which leverages semantic relationships among classes to aid in visual-semantic embedding. VSGMN employs a Graph Build Network (GBN) and a Graph Matching Network (GMN) to achieve two-stage visual-semantic alignment. Specifically, GBN first utilizes an embedding-based approach to build visual and semantic graphs in the semantic space and align the embedding with its prototype for first-stage alignment. Additionally, to supplement unseen class relations in these graphs, GBN also build the unseen class nodes based on semantic relationships. In the second stage, GMN continuously integrates neighbor and cross-graph information into the constructed graph nodes, and aligns the node relationships between the two graphs under the class relationship constraint. Extensive experiments on three benchmark datasets demonstrate that VSGMN achieves superior performance in both conventional and generalized ZSL scenarios. The implementation of our VSGMN and experimental results are available at github: https://github.com/dbwfd/VSGMN
M2EF-NNs: Multimodal Multi-instance Evidence Fusion Neural Networks for Cancer Survival Prediction
Aug 08, 2024Accurate cancer survival prediction is crucial for assisting clinical doctors in formulating treatment plans. Multimodal data, including histopathological images and genomic data, offer complementary and comprehensive information that can greatly enhance the accuracy of this task. However, the current methods, despite yielding promising results, suffer from two notable limitations: they do not effectively utilize global context and disregard modal uncertainty. In this study, we put forward a neural network model called M2EF-NNs, which leverages multimodal and multi-instance evidence fusion techniques for accurate cancer survival prediction. Specifically, to capture global information in the images, we use a pre-trained Vision Transformer (ViT) model to obtain patch feature embeddings of histopathological images. Then, we introduce a multimodal attention module that uses genomic embeddings as queries and learns the co-attention mapping between genomic and histopathological images to achieve an early interaction fusion of multimodal information and better capture their correlations. Subsequently, we are the first to apply the Dempster-Shafer evidence theory (DST) to cancer survival prediction. We parameterize the distribution of class probabilities using the processed multimodal features and introduce subjective logic to estimate the uncertainty associated with different modalities. By combining with the Dempster-Shafer theory, we can dynamically adjust the weights of class probabilities after multimodal fusion to achieve trusted survival prediction. Finally, Experimental validation on the TCGA datasets confirms the significant improvements achieved by our proposed method in cancer survival prediction and enhances the reliability of the model.
Granular-Balls based Fuzzy Twin Support Vector Machine for Classification
Aug 01, 2024



The twin support vector machine (TWSVM) classifier has attracted increasing attention because of its low computational complexity. However, its performance tends to degrade when samples are affected by noise. The granular-ball fuzzy support vector machine (GBFSVM) classifier partly alleviates the adverse effects of noise, but it relies solely on the distance between the granular-ball's center and the class center to design the granular-ball membership function. In this paper, we first introduce the granular-ball twin support vector machine (GBTWSVM) classifier, which integrates granular-ball computing (GBC) with the twin support vector machine (TWSVM) classifier. By replacing traditional point inputs with granular-balls, we demonstrate how to derive a pair of non-parallel hyperplanes for the GBTWSVM classifier by solving a quadratic programming problem. Subsequently, we design the membership and non-membership functions of granular-balls using Pythagorean fuzzy sets to differentiate the contributions of granular-balls in various regions. Additionally, we develop the granular-ball fuzzy twin support vector machine (GBFTSVM) classifier by incorporating GBC with the fuzzy twin support vector machine (FTSVM) classifier. We demonstrate how to derive a pair of non-parallel hyperplanes for the GBFTSVM classifier by solving a quadratic programming problem. We also design algorithms for the GBTSVM classifier and the GBFTSVM classifier. Finally, the superior classification performance of the GBTWSVM classifier and the GBFTSVM classifier on 20 benchmark datasets underscores their scalability, efficiency, and robustness in tackling classification tasks.
FMDNN: A Fuzzy-guided Multi-granular Deep Neural Network for Histopathological Image Classification
Jul 22, 2024



Histopathological image classification constitutes a pivotal task in computer-aided diagnostics. The precise identification and categorization of histopathological images are of paramount significance for early disease detection and treatment. In the diagnostic process of pathologists, a multi-tiered approach is typically employed to assess abnormalities in cell regions at different magnifications. However, feature extraction is often performed at a single granularity, overlooking the multi-granular characteristics of cells. To address this issue, we propose the Fuzzy-guided Multi-granularity Deep Neural Network (FMDNN). Inspired by the multi-granular diagnostic approach of pathologists, we perform feature extraction on cell structures at coarse, medium, and fine granularity, enabling the model to fully harness the information in histopathological images. We incorporate the theory of fuzzy logic to address the challenge of redundant key information arising during multi-granular feature extraction. Cell features are described from different perspectives using multiple fuzzy membership functions, which are fused to create universal fuzzy features. A fuzzy-guided cross-attention module guides universal fuzzy features toward multi-granular features. We propagate these features through an encoder to all patch tokens, aiming to achieve enhanced classification accuracy and robustness. In experiments on multiple public datasets, our model exhibits a significant improvement in accuracy over commonly used classification methods for histopathological image classification and shows commendable interpretability.
* This paper has been accepted by IEEE Transactions on Fuzzy Systems for publication. Permission from IEEE must be obtained for all other uses, in any current or future media. The final version is available at [doi: 10.1109/TFUZZ.2024.3410929]
Cascaded two-stage feature clustering and selection via separability and consistency in fuzzy decision systems
Jul 22, 2024



Feature selection is a vital technique in machine learning, as it can reduce computational complexity, improve model performance, and mitigate the risk of overfitting. However, the increasing complexity and dimensionality of datasets pose significant challenges in the selection of features. Focusing on these challenges, this paper proposes a cascaded two-stage feature clustering and selection algorithm for fuzzy decision systems. In the first stage, we reduce the search space by clustering relevant features and addressing inter-feature redundancy. In the second stage, a clustering-based sequentially forward selection method that explores the global and local structure of data is presented. We propose a novel metric for assessing the significance of features, which considers both global separability and local consistency. Global separability measures the degree of intra-class cohesion and inter-class separation based on fuzzy membership, providing a comprehensive understanding of data separability. Meanwhile, local consistency leverages the fuzzy neighborhood rough set model to capture uncertainty and fuzziness in the data. The effectiveness of our proposed algorithm is evaluated through experiments conducted on 18 public datasets and a real-world schizophrenia dataset. The experiment results demonstrate our algorithm's superiority over benchmarking algorithms in both classification accuracy and the number of selected features.
* This paper has been accepted by IEEE Transactions on Fuzzy Systems for publication. Permission from IEEE must be obtained for all other uses, in any current or future media. The final version is available at [10.1109/TFUZZ.2024.3420963]
FDiff-Fusion:Denoising diffusion fusion network based on fuzzy learning for 3D medical image segmentation
Jul 22, 2024



In recent years, the denoising diffusion model has achieved remarkable success in image segmentation modeling. With its powerful nonlinear modeling capabilities and superior generalization performance, denoising diffusion models have gradually been applied to medical image segmentation tasks, bringing new perspectives and methods to this field. However, existing methods overlook the uncertainty of segmentation boundaries and the fuzziness of regions, resulting in the instability and inaccuracy of the segmentation results. To solve this problem, a denoising diffusion fusion network based on fuzzy learning for 3D medical image segmentation (FDiff-Fusion) is proposed in this paper. By integrating the denoising diffusion model into the classical U-Net network, this model can effectively extract rich semantic information from input medical images, thus providing excellent pixel-level representation for medical image segmentation. ... Finally, to validate the effectiveness of FDiff-Fusion, we compare it with existing advanced segmentation networks on the BRATS 2020 brain tumor dataset and the BTCV abdominal multi-organ dataset. The results show that FDiff-Fusion significantly improves the Dice scores and HD95 distance on these two datasets, demonstrating its superiority in medical image segmentation tasks.
* This paper has been accepted by Information Fusion. Permission from Elsevier must be obtained for all other uses, in any current or future media. The final version is available at [doi:10.1016/J.INFFUS.2024.102540]