 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynSess: Dynamic Session-Level Evaluation and Optimization Framework for Role-Playing Agents
May 28, 2026Role-playing with large language models is fundamentally a session-level task, requiring agents to sustain character identity and interaction quality across extended multi-turn conversations. Yet existing evaluation and optimization methods remain largely turn-level, failing to capture long-horizon quality. We propose DynSess, a unified session-level framework for role-playing agents. DynSess-Eval scores complete dialogue sessions via rubrics targeting long-horizon behaviors. Leveraging its session-level rewards, we construct high-quality training trajectories through multi-turn lookahead search and train DynSess-Character with two complementary variants: DSPO (off-policy) and GSRPO (on-policy). Experiments show that DynSess-Eval aligns with human judgments substantially better than prior evaluators, and blind human evaluation further shows that DynSess-Character matches the strongest character model despite using substantially fewer parameters, while maintaining strong role consistency and interactive ability. Our dataset and code will be released to facilitate future research.
From Facts to Insights: A Persona-Driven Dual Memory Framework and Dataset for Role-Playing Agents
May 25, 2026While role-playing agents excel in short-term interactions, long-term conversations overwhelm context windows, motivating external memory frameworks. Current systems typically rely on persona-agnostic summarization, which records facts without persona-specific interpretation, yielding generic responses that compromise persona fidelity. To bridge this gap, we introduce RoleMemo, a dataset featuring four reasoning tasks where the factual fragments must be interpreted through the persona to reach the correct answer. Evaluation on RoleMemo exposes critical limitations of persona-agnostic frameworks. We thus propose DualMem, which decouples memory into two streams: factual cognition and persona-conditioned insight. Trained through Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), our framework with a 4B-parameter model outperforms zero-shot persona-agnostic frameworks powered by DeepSeek-V3.2 for sustained persona fidelity. Our resources are available at https://github.com/role2026/rolememo.
StoryWeaver: A Unified World Model for Knowledge-Enhanced Story Character Customization
Dec 10, 2024



Story visualization has gained increasing attention in artificial intelligence. However, existing methods still struggle with maintaining a balance between character identity preservation and text-semantics alignment, largely due to a lack of detailed semantic modeling of the story scene. To tackle this challenge, we propose a novel knowledge graph, namely Character Graph (\textbf{CG}), which comprehensively represents various story-related knowledge, including the characters, the attributes related to characters, and the relationship between characters. We then introduce StoryWeaver, an image generator that achieve Customization via Character Graph (\textbf{C-CG}), capable of consistent story visualization with rich text semantics. To further improve the multi-character generation performance, we incorporate knowledge-enhanced spatial guidance (\textbf{KE-SG}) into StoryWeaver to precisely inject character semantics into generation. To validate the effectiveness of our proposed method, extensive experiments are conducted using a new benchmark called TBC-Bench. The experiments confirm that our StoryWeaver excels not only in creating vivid visual story plots but also in accurately conveying character identities across various scenarios with considerable storage efficiency, \emph{e.g.}, achieving an average increase of +9.03\% DINO-I and +13.44\% CLIP-T. Furthermore, ablation experiments are conducted to verify the superiority of the proposed module. Codes and datasets are released at https://github.com/Aria-Zhangjl/StoryWeaver.
Character-Adapter: Prompt-Guided Region Control for High-Fidelity Character Customization
Jun 24, 2024



Customized image generation, which seeks to synthesize images with consistent characters, holds significant relevance for applications such as storytelling, portrait generation, and character design. However, previous approaches have encountered challenges in preserving characters with high-fidelity consistency due to inadequate feature extraction and concept confusion of reference characters. Therefore, we propose Character-Adapter, a plug-and-play framework designed to generate images that preserve the details of reference characters, ensuring high-fidelity consistency. Character-Adapter employs prompt-guided segmentation to ensure fine-grained regional features of reference characters and dynamic region-level adapters to mitigate concept confusion. Extensive experiments are conducted to validate the effectiveness of Character-Adapter. Both quantitative and qualitative results demonstrate that Character-Adapter achieves the state-of-the-art performance of consistent character generation, with an improvement of 24.8% compared with other methods
Let Storytelling Tell Vivid Stories: An Expressive and Fluent Multimodal Storyteller
Mar 12, 2024



Storytelling aims to generate reasonable and vivid narratives based on an ordered image stream. The fidelity to the image story theme and the divergence of story plots attract readers to keep reading. Previous works iteratively improved the alignment of multiple modalities but ultimately resulted in the generation of simplistic storylines for image streams. In this work, we propose a new pipeline, termed LLaMS, to generate multimodal human-level stories that are embodied in expressiveness and consistency. Specifically, by fully exploiting the commonsense knowledge within the LLM, we first employ a sequence data auto-enhancement strategy to enhance factual content expression and leverage a textual reasoning architecture for expressive story generation and prediction. Secondly, we propose SQ-Adatpter module for story illustration generation which can maintain sequence consistency. Numerical results are conducted through human evaluation to verify the superiority of proposed LLaMS. Evaluations show that LLaMS achieves state-of-the-art storytelling performance and 86% correlation and 100% consistency win rate as compared with previous SOTA methods. Furthermore, ablation experiments are conducted to verify the effectiveness of proposed sequence data enhancement and SQ-Adapter.
Towards Efficient Diffusion-Based Image Editing with Instant Attention Masks
Jan 23, 2024



Diffusion-based Image Editing (DIE) is an emerging research hot-spot, which often applies a semantic mask to control the target area for diffusion-based editing. However, most existing solutions obtain these masks via manual operations or off-line processing, greatly reducing their efficiency. In this paper, we propose a novel and efficient image editing method for Text-to-Image (T2I) diffusion models, termed Instant Diffusion Editing(InstDiffEdit). In particular, InstDiffEdit aims to employ the cross-modal attention ability of existing diffusion models to achieve instant mask guidance during the diffusion steps. To reduce the noise of attention maps and realize the full automatics, we equip InstDiffEdit with a training-free refinement scheme to adaptively aggregate the attention distributions for the automatic yet accurate mask generation. Meanwhile, to supplement the existing evaluations of DIE, we propose a new benchmark called Editing-Mask to examine the mask accuracy and local editing ability of existing methods. To validate InstDiffEdit, we also conduct extensive experiments on ImageNet and Imagen, and compare it with a bunch of the SOTA methods. The experimental results show that InstDiffEdit not only outperforms the SOTA methods in both image quality and editing results, but also has a much faster inference speed, i.e., +5 to +6 times.
Beyond First Impressions: Integrating Joint Multi-modal Cues for Comprehensive 3D Representation
Aug 06, 2023



In recent years, 3D representation learning has turned to 2D vision-language pre-trained models to overcome data scarcity challenges. However, existing methods simply transfer 2D alignment strategies, aligning 3D representations with single-view 2D images and coarse-grained parent category text. These approaches introduce information degradation and insufficient synergy issues, leading to performance loss. Information degradation arises from overlooking the fact that a 3D representation should be equivalent to a series of multi-view images and more fine-grained subcategory text. Insufficient synergy neglects the idea that a robust 3D representation should align with the joint vision-language space, rather than independently aligning with each modality. In this paper, we propose a multi-view joint modality modeling approach, termed JM3D, to obtain a unified representation for point cloud, text, and image. Specifically, a novel Structured Multimodal Organizer (SMO) is proposed to address the information degradation issue, which introduces contiguous multi-view images and hierarchical text to enrich the representation of vision and language modalities. A Joint Multi-modal Alignment (JMA) is designed to tackle the insufficient synergy problem, which models the joint modality by incorporating language knowledge into the visual modality. Extensive experiments on ModelNet40 and ScanObjectNN demonstrate the effectiveness of our proposed method, JM3D, which achieves state-of-the-art performance in zero-shot 3D classification. JM3D outperforms ULIP by approximately 4.3% on PointMLP and achieves an improvement of up to 6.5% accuracy on PointNet++ in top-1 accuracy for zero-shot 3D classification on ModelNet40. The source code and trained models for all our experiments are publicly available at https://github.com/Mr-Neko/JM3D.
Structure-CLIP: Enhance Multi-modal Language Representations with Structure Knowledge
May 06, 2023Large-scale vision-language pre-training has shown promising advances on various downstream tasks and achieved significant performance in multi-modal understanding and generation tasks. However, existing methods often perform poorly on image-text matching tasks that require a detailed semantics understanding of the text. Although there have been some works on this problem, they do not sufficiently exploit the structural knowledge present in sentences to enhance multi-modal language representations, which leads to poor performance. In this paper, we present an end-to-end framework Structure-CLIP, which integrates latent detailed semantics from the text to enhance fine-grained semantic representations. Specifically, (1) we use scene graphs in order to pay more attention to the detailed semantic learning in the text and fully explore structured knowledge between fine-grained semantics, and (2) we utilize the knowledge-enhanced framework with the help of the scene graph to make full use of representations of structured knowledge. To verify the effectiveness of our proposed method, we pre-trained our models with the aforementioned approach and conduct experiments on different downstream tasks. Numerical results show that Structure-CLIP can often achieve state-of-the-art performance on both VG-Attribution and VG-Relation datasets. Extensive experiments show its components are effective and its predictions are interpretable, which proves that our proposed method can enhance detailed semantic representation well.
ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph
Jun 30, 2020

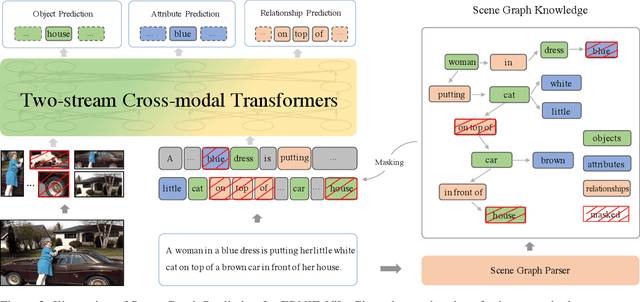
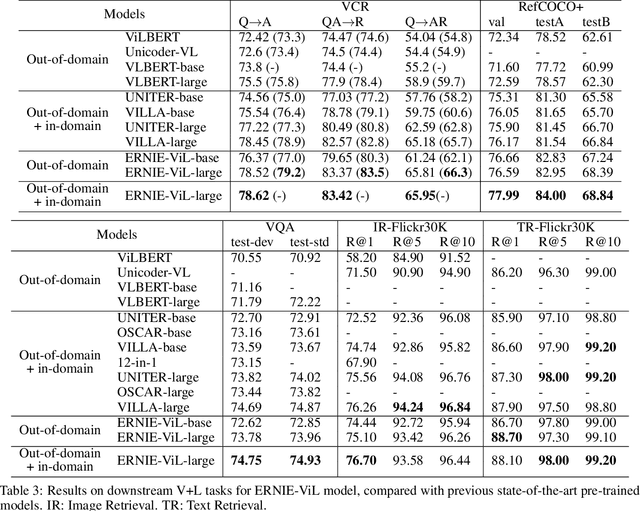
We propose a knowledge-enhanced approach, ERNIE-ViL, to learn joint representations of vision and language. ERNIE-ViL tries to construct the detailed semantic connections (objects, attributes of objects and relationships between objects in visual scenes) across vision and language, which are essential to vision-language cross-modal tasks. Incorporating knowledge from scene graphs, ERNIE-ViL constructs Scene Graph Prediction tasks, i.e., Object Prediction, Attribute Prediction and Relationship Prediction in the pre-training phase. More specifically, these prediction tasks are implemented by predicting nodes of different types in the scene graph parsed from the sentence. Thus, ERNIE-ViL can model the joint representation characterizing the alignments of the detailed semantics across vision and language. Pre-trained on two large image-text alignment datasets (Conceptual Captions and SBU), ERNIE-ViL learns better and more robust joint representations. It achieves state-of-the-art performance on 5 vision-language downstream tasks after fine-tuning ERNIE-ViL. Furthermore, it ranked the 1st place on the VCR leader-board with an absolute improvement of 3.7\%.