 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLips Are Lying: Spotting the Temporal Inconsistency between Audio and Visual in Lip-Syncing DeepFakes
Jan 28, 2024



In recent years, DeepFake technology has achieved unprecedented success in high-quality video synthesis, whereas these methods also pose potential and severe security threats to humanity. DeepFake can be bifurcated into entertainment applications like face swapping and illicit uses such as lip-syncing fraud. However, lip-forgery videos, which neither change identity nor have discernible visual artifacts, present a formidable challenge to existing DeepFake detection methods. Our preliminary experiments have shown that the effectiveness of the existing methods often drastically decreases or even fails when tackling lip-syncing videos. In this paper, for the first time, we propose a novel approach dedicated to lip-forgery identification that exploits the inconsistency between lip movements and audio signals. We also mimic human natural cognition by capturing subtle biological links between lips and head regions to boost accuracy. To better illustrate the effectiveness and advances of our proposed method, we curate a high-quality LipSync dataset by employing the SOTA lip generator. We hope this high-quality and diverse dataset could be well served the further research on this challenging and interesting field. Experimental results show that our approach gives an average accuracy of more than 95.3% in spotting lip-syncing videos, significantly outperforming the baselines. Extensive experiments demonstrate the capability to tackle deepfakes and the robustness in surviving diverse input transformations. Our method achieves an accuracy of up to 90.2% in real-world scenarios (e.g., WeChat video call) and shows its powerful capabilities in real scenario deployment. To facilitate the progress of this research community, we release all resources at https://github.com/AaronComo/LipFD.
Unlikelihood Tuning on Negative Samples Amazingly Improves Zero-Shot Translation
Sep 28, 2023Zero-shot translation (ZST), which is generally based on a multilingual neural machine translation model, aims to translate between unseen language pairs in training data. The common practice to guide the zero-shot language mapping during inference is to deliberately insert the source and target language IDs, e.g., <EN> for English and <DE> for German. Recent studies have shown that language IDs sometimes fail to navigate the ZST task, making them suffer from the off-target problem (non-target language words exist in the generated translation) and, therefore, difficult to apply the current multilingual translation model to a broad range of zero-shot language scenarios. To understand when and why the navigation capabilities of language IDs are weakened, we compare two extreme decoder input cases in the ZST directions: Off-Target (OFF) and On-Target (ON) cases. By contrastively visualizing the contextual word representations (CWRs) of these cases with teacher forcing, we show that 1) the CWRs of different languages are effectively distributed in separate regions when the sentence and ID are matched (ON setting), and 2) if the sentence and ID are unmatched (OFF setting), the CWRs of different languages are chaotically distributed. Our analyses suggest that although they work well in ideal ON settings, language IDs become fragile and lose their navigation ability when faced with off-target tokens, which commonly exist during inference but are rare in training scenarios. In response, we employ unlikelihood tuning on the negative (OFF) samples to minimize their probability such that the language IDs can discriminate between the on- and off-target tokens during training. Experiments spanning 40 ZST directions show that our method reduces the off-target ratio by -48.0% on average, leading to a +9.1 BLEU improvement with only an extra +0.3% tuning cost.
Prompt-Learning for Cross-Lingual Relation Extraction
Apr 20, 2023Relation Extraction (RE) is a crucial task in Information Extraction, which entails predicting relationships between entities within a given sentence. However, extending pre-trained RE models to other languages is challenging, particularly in real-world scenarios where Cross-Lingual Relation Extraction (XRE) is required. Despite recent advancements in Prompt-Learning, which involves transferring knowledge from Multilingual Pre-trained Language Models (PLMs) to diverse downstream tasks, there is limited research on the effective use of multilingual PLMs with prompts to improve XRE. In this paper, we present a novel XRE algorithm based on Prompt-Tuning, referred to as Prompt-XRE. To evaluate its effectiveness, we design and implement several prompt templates, including hard, soft, and hybrid prompts, and empirically test their performance on competitive multilingual PLMs, specifically mBART. Our extensive experiments, conducted on the low-resource ACE05 benchmark across multiple languages, demonstrate that our Prompt-XRE algorithm significantly outperforms both vanilla multilingual PLMs and other existing models, achieving state-of-the-art performance in XRE. To further show the generalization of our Prompt-XRE on larger data scales, we construct and release a new XRE dataset- WMT17-EnZh XRE, containing 0.9M English-Chinese pairs extracted from WMT 2017 parallel corpus. Experiments on WMT17-EnZh XRE also show the effectiveness of our Prompt-XRE against other competitive baselines. The code and newly constructed dataset are freely available at \url{https://github.com/HSU-CHIA-MING/Prompt-XRE}.
Hybrid Multimodal Fusion for Humor Detection
Sep 24, 2022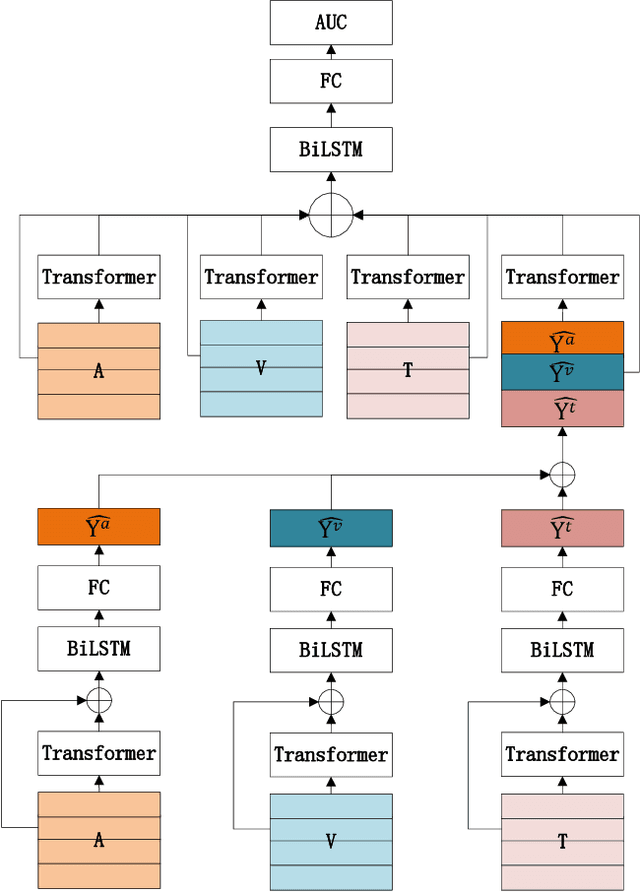
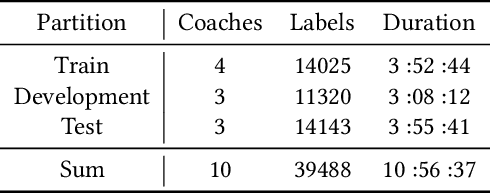
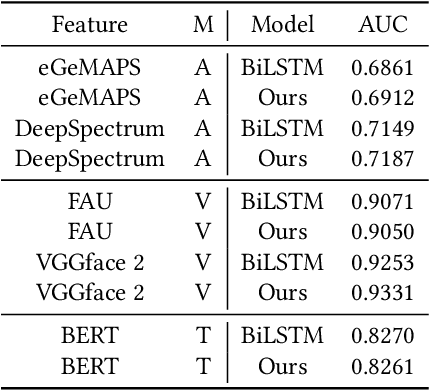
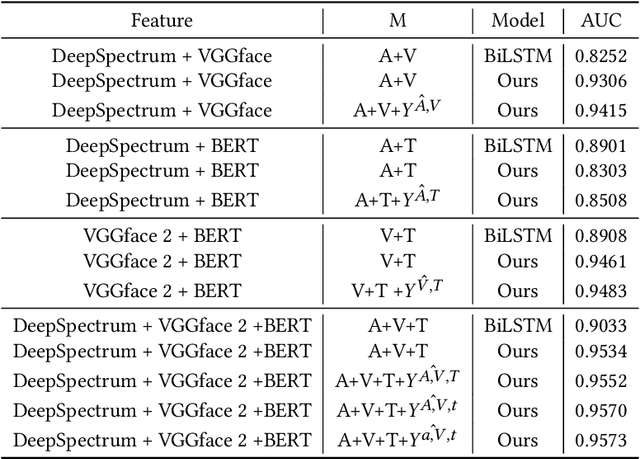
In this paper, we present our solution to the MuSe-Humor sub-challenge of the Multimodal Emotional Challenge (MuSe) 2022. The goal of the MuSe-Humor sub-challenge is to detect humor and calculate AUC from audiovisual recordings of German football Bundesliga press conferences. It is annotated for humor displayed by the coaches. For this sub-challenge, we first build a discriminant model using the transformer module and BiLSTM module, and then propose a hybrid fusion strategy to use the prediction results of each modality to improve the performance of the model. Our experiments demonstrate the effectiveness of our proposed model and hybrid fusion strategy on multimodal fusion, and the AUC of our proposed model on the test set is 0.8972.
Vega-MT: The JD Explore Academy Translation System for WMT22
Sep 21, 2022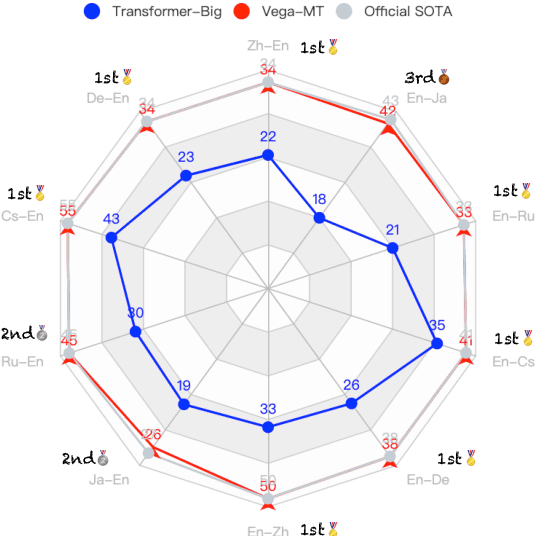
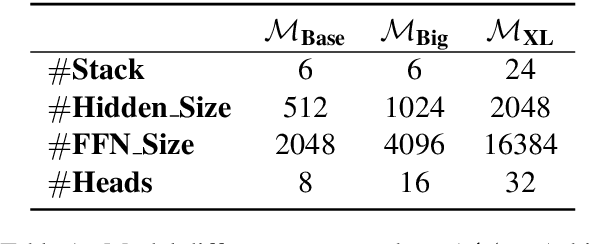
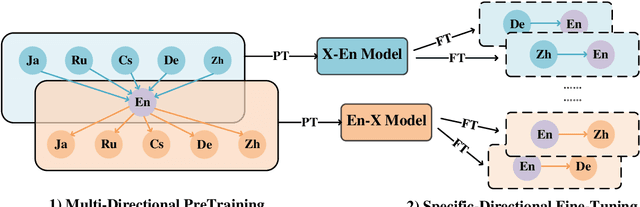

We describe the JD Explore Academy's submission of the WMT 2022 shared general translation task. We participated in all high-resource tracks and one medium-resource track, including Chinese-English, German-English, Czech-English, Russian-English, and Japanese-English. We push the limit of our previous work -- bidirectional training for translation by scaling up two main factors, i.e. language pairs and model sizes, namely the \textbf{Vega-MT} system. As for language pairs, we scale the "bidirectional" up to the "multidirectional" settings, covering all participating languages, to exploit the common knowledge across languages, and transfer them to the downstream bilingual tasks. As for model sizes, we scale the Transformer-Big up to the extremely large model that owns nearly 4.7 Billion parameters, to fully enhance the model capacity for our Vega-MT. Also, we adopt the data augmentation strategies, e.g. cycle translation for monolingual data, and bidirectional self-training for bilingual and monolingual data, to comprehensively exploit the bilingual and monolingual data. To adapt our Vega-MT to the general domain test set, generalization tuning is designed. Based on the official automatic scores of constrained systems, in terms of the sacreBLEU shown in Figure-1, we got the 1st place on {Zh-En (33.5), En-Zh (49.7), De-En (33.7), En-De (37.8), Cs-En (54.9), En-Cs (41.4) and En-Ru (32.7)}, 2nd place on {Ru-En (45.1) and Ja-En (25.6)}, and 3rd place on {En-Ja(41.5)}, respectively; W.R.T the COMET, we got the 1st place on {Zh-En (45.1), En-Zh (61.7), De-En (58.0), En-De (63.2), Cs-En (74.7), Ru-En (64.9), En-Ru (69.6) and En-Ja (65.1)}, 2nd place on {En-Cs (95.3) and Ja-En (40.6)}, respectively. Models will be released to facilitate the MT community through GitHub and OmniForce Platform.
On the Complementarity between Pre-Training and Random-Initialization for Resource-Rich Machine Translation
Sep 15, 2022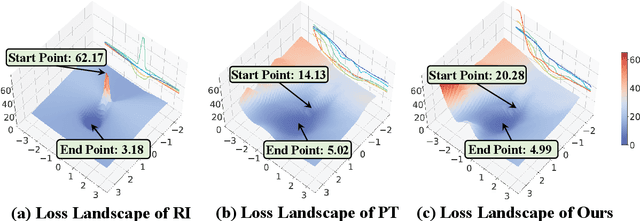
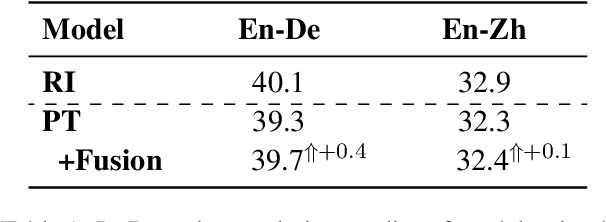
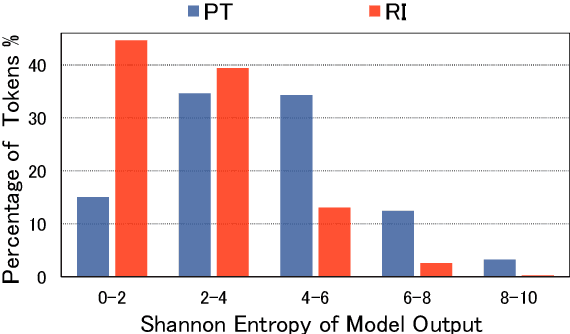
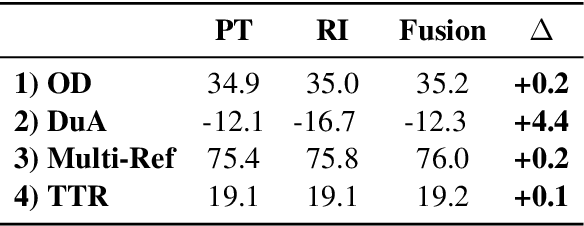
Pre-Training (PT) of text representations has been successfully applied to low-resource Neural Machine Translation (NMT). However, it usually fails to achieve notable gains (sometimes, even worse) on resource-rich NMT on par with its Random-Initialization (RI) counterpart. We take the first step to investigate the complementarity between PT and RI in resource-rich scenarios via two probing analyses, and find that: 1) PT improves NOT the accuracy, but the generalization by achieving flatter loss landscapes than that of RI; 2) PT improves NOT the confidence of lexical choice, but the negative diversity by assigning smoother lexical probability distributions than that of RI. Based on these insights, we propose to combine their complementarities with a model fusion algorithm that utilizes optimal transport to align neurons between PT and RI. Experiments on two resource-rich translation benchmarks, WMT'17 English-Chinese (20M) and WMT'19 English-German (36M), show that PT and RI could be nicely complementary to each other, achieving substantial improvements considering both translation accuracy, generalization, and negative diversity. Probing tools and code are released at: https://github.com/zanchangtong/PTvsRI.
Bridging Cross-Lingual Gaps During Leveraging the Multilingual Sequence-to-Sequence Pretraining for Text Generation
Apr 16, 2022
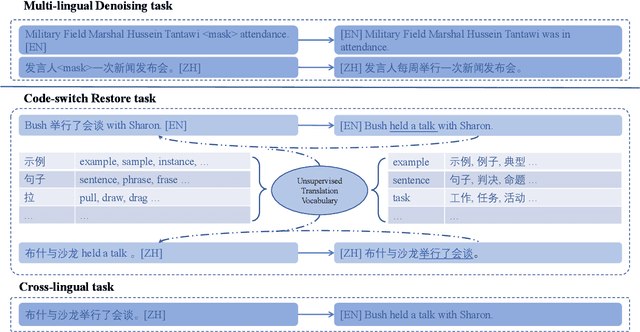
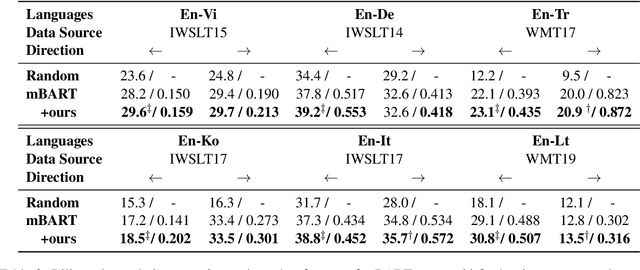
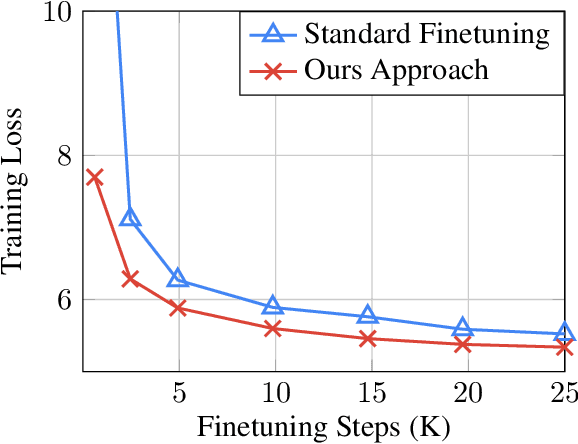
For multilingual sequence-to-sequence pretrained language models (multilingual Seq2Seq PLMs), e.g. mBART, the self-supervised pretraining task is trained on a wide range of monolingual languages, e.g. 25 languages from commoncrawl, while the downstream cross-lingual tasks generally progress on a bilingual language subset, e.g. English-German, making there exists the cross-lingual data discrepancy, namely \textit{domain discrepancy}, and cross-lingual learning objective discrepancy, namely \textit{task discrepancy}, between the pretrain and finetune stages. To bridge the above cross-lingual domain and task gaps, we extend the vanilla pretrain-finetune pipeline with extra code-switching restore task. Specifically, the first stage employs the self-supervised code-switching restore task as a pretext task, allowing the multilingual Seq2Seq PLM to acquire some in-domain alignment information. And for the second stage, we continuously fine-tune the model on labeled data normally. Experiments on a variety of cross-lingual NLG tasks, including 12 bilingual translation tasks, 36 zero-shot translation tasks, and cross-lingual summarization tasks show our model outperforms the strong baseline mBART consistently. Comprehensive analyses indicate our approach could narrow the cross-lingual sentence representation distance and improve low-frequency word translation with trivial computational cost.
Selecting task with optimal transport self-supervised learning for few-shot classification
Apr 01, 2022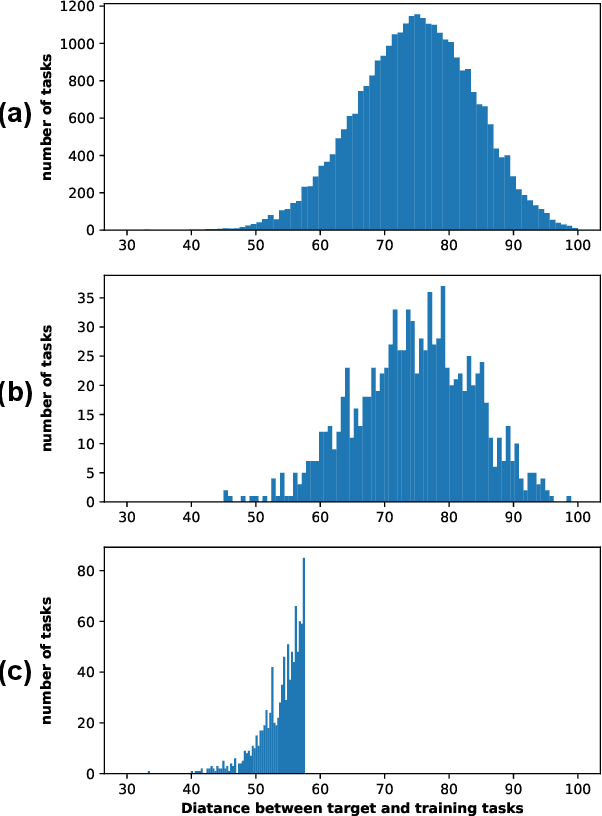
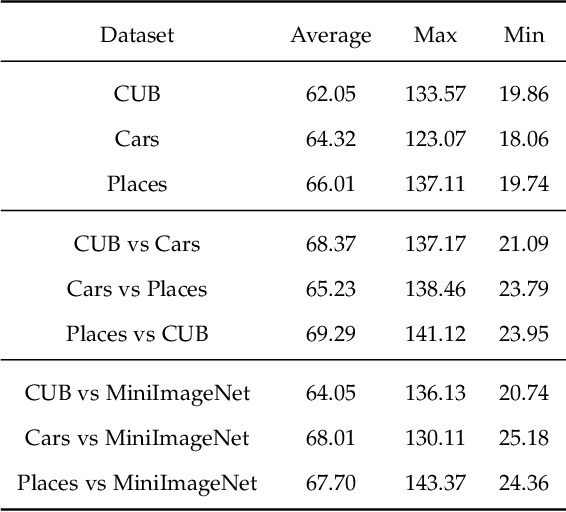


Few-Shot classification aims at solving problems that only a few samples are available in the training process. Due to the lack of samples, researchers generally employ a set of training tasks from other domains to assist the target task, where the distribution between assistant tasks and the target task is usually different. To reduce the distribution gap, several lines of methods have been proposed, such as data augmentation and domain alignment. However, one common drawback of these algorithms is that they ignore the similarity task selection before training. The fundamental problem is to push the auxiliary tasks close to the target task. In this paper, we propose a novel task selecting algorithm, named Optimal Transport Task Selecting (OTTS), to construct a training set by selecting similar tasks for Few-Shot learning. Specifically, the OTTS measures the task similarity by calculating the optimal transport distance and completes the model training via a self-supervised strategy. By utilizing the selected tasks with OTTS, the training process of Few-Shot learning become more stable and effective. Other proposed methods including data augmentation and domain alignment can be used in the meantime with OTTS. We conduct extensive experiments on a variety of datasets, including MiniImageNet, CIFAR, CUB, Cars, and Places, to evaluate the effectiveness of OTTS. Experimental results validate that our OTTS outperforms the typical baselines, i.e., MAML, matchingnet, protonet, by a large margin (averagely 1.72\% accuracy improvement).
CSN: Component-Supervised Network for Few-Shot Classification
Mar 15, 2022
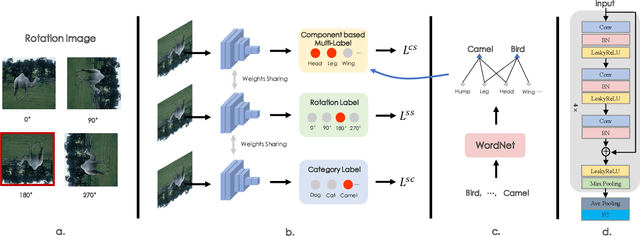

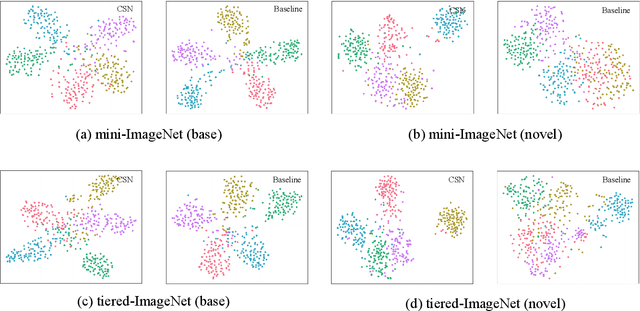
The few-shot classification (FSC) task has been a hot research topic in recent years. It aims to address the classification problem with insufficient labeled data on a cross-category basis. Typically, researchers pre-train a feature extractor with base data, then use it to extract the features of novel data and recognize them. Notably, the novel set only has a few annotated samples and has entirely different categories from the base set, which leads to that the pre-trained feature extractor can not adapt to the novel data flawlessly. We dub this problem as Feature-Extractor-Maladaptive (FEM) problem. Starting from the root cause of this problem, this paper presents a new scheme, Component-Supervised Network (CSN), to improve the performance of FSC. We believe that although the categories of base and novel sets are different, the composition of the sample's components is similar. For example, both cat and dog contain leg and head components. Actually, such entity components are intra-class stable. They have fine cross-category versatility and new category generalization. Therefore, we refer to WordNet, a dictionary commonly used in natural language processing, to collect component information of samples and construct a component-based auxiliary task to improve the adaptability of the feature extractor. We conduct experiments on two benchmark datasets (mini-ImageNet and tiered-ImageNet), the improvements of $0.9\%$-$5.8\%$ compared with state-of-the-arts have evaluated the efficiency of our CSN.
Where Does the Performance Improvement Come From? - A Reproducibility Concern about Image-Text Retrieval
Mar 08, 2022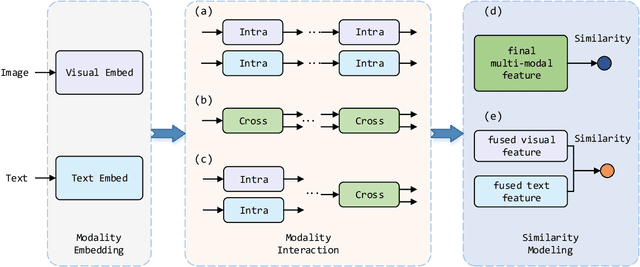
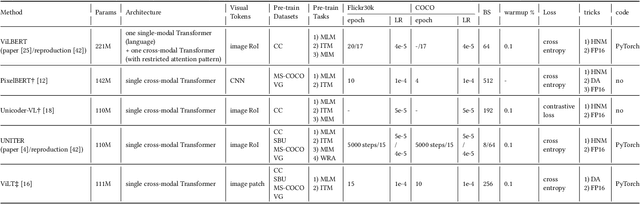
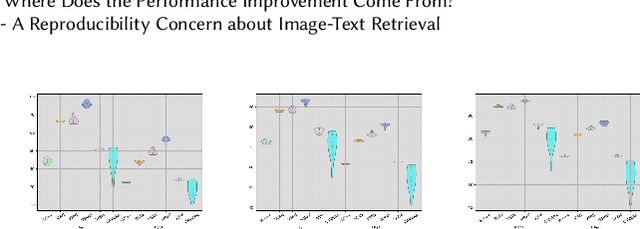
This paper seeks to provide the information retrieval community with some reflections on the current improvements of retrieval learning through the analysis of the reproducibility aspects of image-text retrieval models. For the latter part of the past decade, image-text retrieval has gradually become a major research direction in the field of information retrieval because of the growth of multi-modal data. Many researchers use benchmark datasets like MS-COCO and Flickr30k to train and assess the performance of image-text retrieval algorithms. Research in the past has mostly focused on performance, with several state-of-the-art methods being proposed in various ways. According to their claims, these approaches achieve better modal interactions and thus better multimodal representations with greater precision. In contrast to those previous works, we focus on the repeatability of the approaches and the overall examination of the elements that lead to improved performance by pretrained and nonpretrained models in retrieving images and text. To be more specific, we first examine the related reproducibility concerns and why the focus is on image-text retrieval tasks, and then we systematically summarize the current paradigm of image-text retrieval models and the stated contributions of those approaches. Second, we analyze various aspects of the reproduction of pretrained and nonpretrained retrieval models. Based on this, we conducted ablation experiments and obtained some influencing factors that affect retrieval recall more than the improvement claimed in the original paper. Finally, we also present some reflections and issues that should be considered by the retrieval community in the future. Our code is freely available at https://github.com/WangFei-2019/Image-text-Retrieval.