 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVLTA-VQA: Decoupled Vision-Language Modeling with Text-Guided Adaptation for Blind Video Quality Assessment
Apr 16, 2025



Inspired by the dual-stream theory of the human visual system (HVS) - where the ventral stream is responsible for object recognition and detail analysis, while the dorsal stream focuses on spatial relationships and motion perception - an increasing number of video quality assessment (VQA) works built upon this framework are proposed. Recent advancements in large multi-modal models, notably Contrastive Language-Image Pretraining (CLIP), have motivated researchers to incorporate CLIP into dual-stream-based VQA methods. This integration aims to harness the model's superior semantic understanding capabilities to replicate the object recognition and detail analysis in ventral stream, as well as spatial relationship analysis in dorsal stream. However, CLIP is originally designed for images and lacks the ability to capture temporal and motion information inherent in videos. %Furthermore, existing feature fusion strategies in no-reference video quality assessment (NR-VQA) often rely on fixed weighting schemes, which fail to adaptively adjust feature importance. To address the limitation, this paper propose a Decoupled Vision-Language Modeling with Text-Guided Adaptation for Blind Video Quality Assessment (DVLTA-VQA), which decouples CLIP's visual and textual components, and integrates them into different stages of the NR-VQA pipeline.
A Comprehensive Survey of Reward Models: Taxonomy, Applications, Challenges, and Future
Apr 12, 2025Reward Model (RM) has demonstrated impressive potential for enhancing Large Language Models (LLM), as RM can serve as a proxy for human preferences, providing signals to guide LLMs' behavior in various tasks. In this paper, we provide a comprehensive overview of relevant research, exploring RMs from the perspectives of preference collection, reward modeling, and usage. Next, we introduce the applications of RMs and discuss the benchmarks for evaluation. Furthermore, we conduct an in-depth analysis of the challenges existing in the field and dive into the potential research directions. This paper is dedicated to providing beginners with a comprehensive introduction to RMs and facilitating future studies. The resources are publicly available at github\footnote{https://github.com/JLZhong23/awesome-reward-models}.
CrackSQL: A Hybrid SQL Dialect Translation System Powered by Large Language Models
Apr 01, 2025Dialect translation plays a key role in enabling seamless interaction across heterogeneous database systems. However, translating SQL queries between different dialects (e.g., from PostgreSQL to MySQL) remains a challenging task due to syntactic discrepancies and subtle semantic variations. Existing approaches including manual rewriting, rule-based systems, and large language model (LLM)-based techniques often involve high maintenance effort (e.g., crafting custom translation rules) or produce unreliable results (e.g., LLM generates non-existent functions), especially when handling complex queries. In this demonstration, we present CrackSQL, the first hybrid SQL dialect translation system that combines rule and LLM-based methods to overcome these limitations. CrackSQL leverages the adaptability of LLMs to minimize manual intervention, while enhancing translation accuracy by segmenting lengthy complex SQL via functionality-based query processing. To further improve robustness, it incorporates a novel cross-dialect syntax embedding model for precise syntax alignment, as well as an adaptive local-to-global translation strategy that effectively resolves interdependent query operations. CrackSQL supports three translation modes and offers multiple deployment and access options including a web console interface, a PyPI package, and a command-line prompt, facilitating adoption across a variety of real-world use cases
FeatInsight: An Online ML Feature Management System on 4Paradigm Sage-Studio Platform
Apr 01, 2025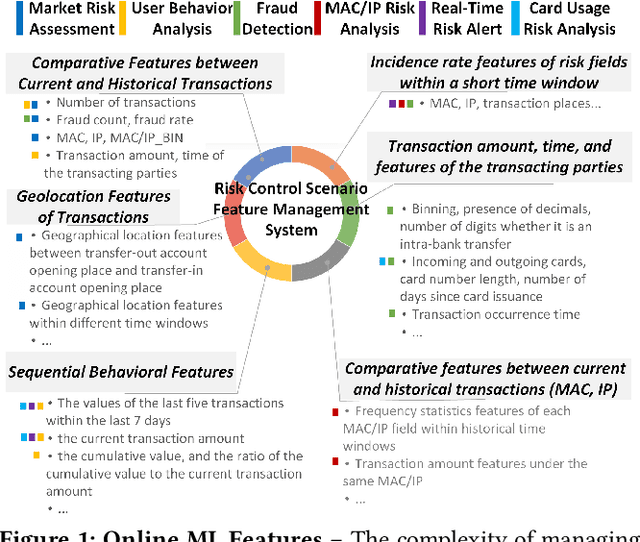
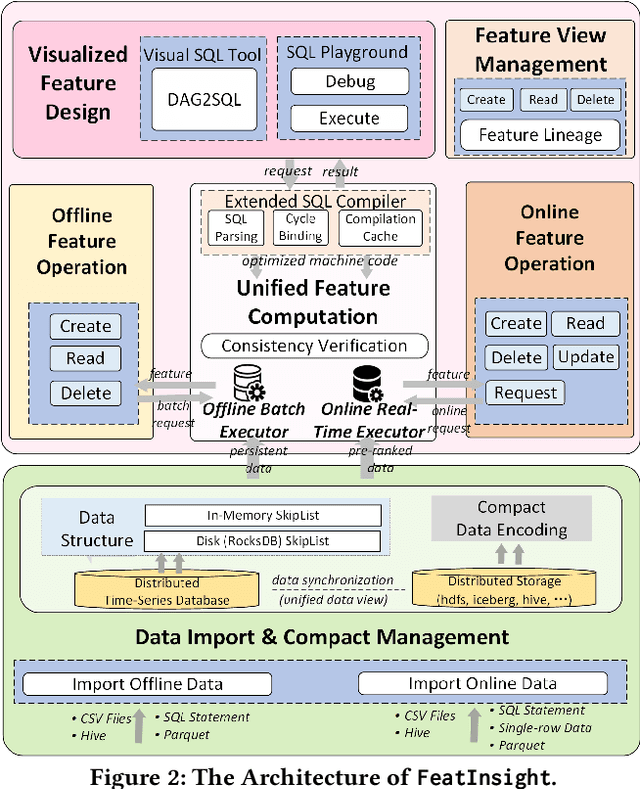
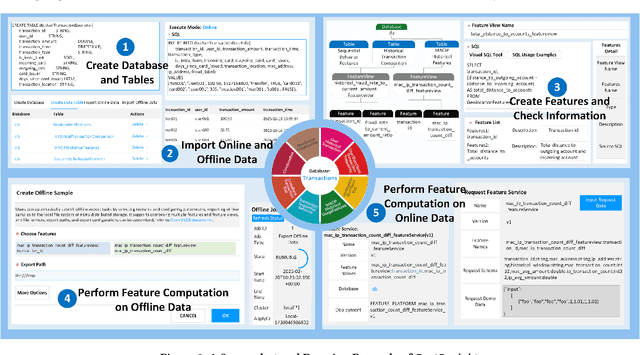
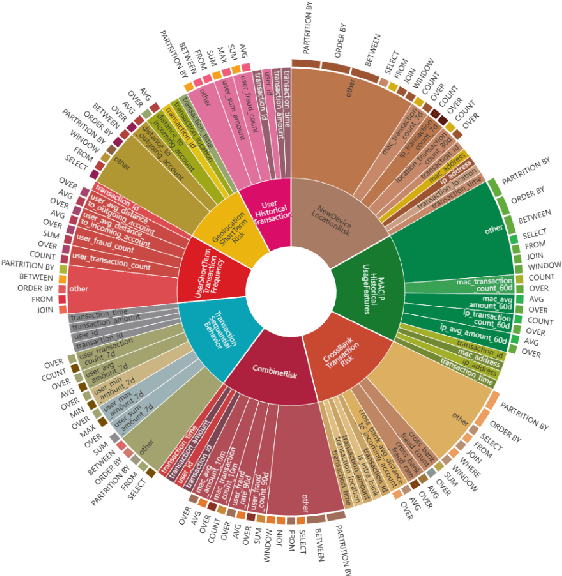
Feature management is essential for many online machine learning applications and can often become the performance bottleneck (e.g., taking up to 70% of the overall latency in sales prediction service). Improper feature configurations (e.g., introducing too many irrelevant features) can severely undermine the model's generalization capabilities. However, managing online ML features is challenging due to (1) large-scale, complex raw data (e.g., the 2018 PHM dataset contains 17 tables and dozens to hundreds of columns), (2) the need for high-performance, consistent computation of interdependent features with complex patterns, and (3) the requirement for rapid updates and deployments to accommodate real-time data changes. In this demo, we present FeatInsight, a system that supports the entire feature lifecycle, including feature design, storage, visualization, computation, verification, and lineage management. FeatInsight (with OpenMLDB as the execution engine) has been deployed in over 100 real-world scenarios on 4Paradigm's Sage Studio platform, handling up to a trillion-dimensional feature space and enabling millisecond-level feature updates. We demonstrate how FeatInsight enhances feature design efficiency (e.g., for online product recommendation) and improve feature computation performance (e.g., for online fraud detection). The code is available at https://github.com/4paradigm/FeatInsight.
InteractEdit: Zero-Shot Editing of Human-Object Interactions in Images
Mar 12, 2025



This paper presents InteractEdit, a novel framework for zero-shot Human-Object Interaction (HOI) editing, addressing the challenging task of transforming an existing interaction in an image into a new, desired interaction while preserving the identities of the subject and object. Unlike simpler image editing scenarios such as attribute manipulation, object replacement or style transfer, HOI editing involves complex spatial, contextual, and relational dependencies inherent in humans-objects interactions. Existing methods often overfit to the source image structure, limiting their ability to adapt to the substantial structural modifications demanded by new interactions. To address this, InteractEdit decomposes each scene into subject, object, and background components, then employs Low-Rank Adaptation (LoRA) and selective fine-tuning to preserve pretrained interaction priors while learning the visual identity of the source image. This regularization strategy effectively balances interaction edits with identity consistency. We further introduce IEBench, the most comprehensive benchmark for HOI editing, which evaluates both interaction editing and identity preservation. Our extensive experiments show that InteractEdit significantly outperforms existing methods, establishing a strong baseline for future HOI editing research and unlocking new possibilities for creative and practical applications. Code will be released upon publication.
Enhancing Multi-Hop Fact Verification with Structured Knowledge-Augmented Large Language Models
Mar 11, 2025



The rapid development of social platforms exacerbates the dissemination of misinformation, which stimulates the research in fact verification. Recent studies tend to leverage semantic features to solve this problem as a single-hop task. However, the process of verifying a claim requires several pieces of evidence with complicated inner logic and relations to verify the given claim in real-world situations. Recent studies attempt to improve both understanding and reasoning abilities to enhance the performance, but they overlook the crucial relations between entities that benefit models to understand better and facilitate the prediction. To emphasize the significance of relations, we resort to Large Language Models (LLMs) considering their excellent understanding ability. Instead of other methods using LLMs as the predictor, we take them as relation extractors, for they do better in understanding rather than reasoning according to the experimental results. Thus, to solve the challenges above, we propose a novel Structured Knowledge-Augmented LLM-based Network (LLM-SKAN) for multi-hop fact verification. Specifically, we utilize an LLM-driven Knowledge Extractor to capture fine-grained information, including entities and their complicated relations. Besides, we leverage a Knowledge-Augmented Relation Graph Fusion module to interact with each node and learn better claim-evidence representations comprehensively. The experimental results on four common-used datasets demonstrate the effectiveness and superiority of our model.
An Information-theoretic Multi-task Representation Learning Framework for Natural Language Understanding
Mar 06, 2025



This paper proposes a new principled multi-task representation learning framework (InfoMTL) to extract noise-invariant sufficient representations for all tasks. It ensures sufficiency of shared representations for all tasks and mitigates the negative effect of redundant features, which can enhance language understanding of pre-trained language models (PLMs) under the multi-task paradigm. Firstly, a shared information maximization principle is proposed to learn more sufficient shared representations for all target tasks. It can avoid the insufficiency issue arising from representation compression in the multi-task paradigm. Secondly, a task-specific information minimization principle is designed to mitigate the negative effect of potential redundant features in the input for each task. It can compress task-irrelevant redundant information and preserve necessary information relevant to the target for multi-task prediction. Experiments on six classification benchmarks show that our method outperforms 12 comparative multi-task methods under the same multi-task settings, especially in data-constrained and noisy scenarios. Extensive experiments demonstrate that the learned representations are more sufficient, data-efficient, and robust.
Physical Depth-aware Early Accident Anticipation: A Multi-dimensional Visual Feature Fusion Framework
Feb 19, 2025Early accident anticipation from dashcam videos is a highly desirable yet challenging task for improving the safety of intelligent vehicles. Existing advanced accident anticipation approaches commonly model the interaction among traffic agents (e.g., vehicles, pedestrians, etc.) in the coarse 2D image space, which may not adequately capture their true positions and interactions. To address this limitation, we propose a physical depth-aware learning framework that incorporates the monocular depth features generated by a large model named Depth-Anything to introduce more fine-grained spatial 3D information. Furthermore, the proposed framework also integrates visual interaction features and visual dynamic features from traffic scenes to provide a more comprehensive perception towards the scenes. Based on these multi-dimensional visual features, the framework captures early indicators of accidents through the analysis of interaction relationships between objects in sequential frames. Additionally, the proposed framework introduces a reconstruction adjacency matrix for key traffic participants that are occluded, mitigating the impact of occluded objects on graph learning and maintaining the spatio-temporal continuity. Experimental results on public datasets show that the proposed framework attains state-of-the-art performance, highlighting the effectiveness of incorporating visual depth features and the superiority of the proposed framework.
DSMoE: Matrix-Partitioned Experts with Dynamic Routing for Computation-Efficient Dense LLMs
Feb 18, 2025As large language models continue to scale, computational costs and resource consumption have emerged as significant challenges. While existing sparsification methods like pruning reduce computational overhead, they risk losing model knowledge through parameter removal. This paper proposes DSMoE (Dynamic Sparse Mixture-of-Experts), a novel approach that achieves sparsification by partitioning pre-trained FFN layers into computational blocks. We implement adaptive expert routing using sigmoid activation and straight-through estimators, enabling tokens to flexibly access different aspects of model knowledge based on input complexity. Additionally, we introduce a sparsity loss term to balance performance and computational efficiency. Extensive experiments on LLaMA models demonstrate that under equivalent computational constraints, DSMoE achieves superior performance compared to existing pruning and MoE approaches across language modeling and downstream tasks, particularly excelling in generation tasks. Analysis reveals that DSMoE learns distinctive layerwise activation patterns, providing new insights for future MoE architecture design.
Pragmatics in the Era of Large Language Models: A Survey on Datasets, Evaluation, Opportunities and Challenges
Feb 17, 2025Understanding pragmatics-the use of language in context-is crucial for developing NLP systems capable of interpreting nuanced language use. Despite recent advances in language technologies, including large language models, evaluating their ability to handle pragmatic phenomena such as implicatures and references remains challenging. To advance pragmatic abilities in models, it is essential to understand current evaluation trends and identify existing limitations. In this survey, we provide a comprehensive review of resources designed for evaluating pragmatic capabilities in NLP, categorizing datasets by the pragmatics phenomena they address. We analyze task designs, data collection methods, evaluation approaches, and their relevance to real-world applications. By examining these resources in the context of modern language models, we highlight emerging trends, challenges, and gaps in existing benchmarks. Our survey aims to clarify the landscape of pragmatic evaluation and guide the development of more comprehensive and targeted benchmarks, ultimately contributing to more nuanced and context-aware NLP models.