 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHokoff: Real Game Dataset from Honor of Kings and its Offline Reinforcement Learning Benchmarks
Aug 20, 2024



The advancement of Offline Reinforcement Learning (RL) and Offline Multi-Agent Reinforcement Learning (MARL) critically depends on the availability of high-quality, pre-collected offline datasets that represent real-world complexities and practical applications. However, existing datasets often fall short in their simplicity and lack of realism. To address this gap, we propose Hokoff, a comprehensive set of pre-collected datasets that covers both offline RL and offline MARL, accompanied by a robust framework, to facilitate further research. This data is derived from Honor of Kings, a recognized Multiplayer Online Battle Arena (MOBA) game known for its intricate nature, closely resembling real-life situations. Utilizing this framework, we benchmark a variety of offline RL and offline MARL algorithms. We also introduce a novel baseline algorithm tailored for the inherent hierarchical action space of the game. We reveal the incompetency of current offline RL approaches in handling task complexity, generalization and multi-task learning.
Autogenic Language Embedding for Coherent Point Tracking
Jul 30, 2024



Point tracking is a challenging task in computer vision, aiming to establish point-wise correspondence across long video sequences. Recent advancements have primarily focused on temporal modeling techniques to improve local feature similarity, often overlooking the valuable semantic consistency inherent in tracked points. In this paper, we introduce a novel approach leveraging language embeddings to enhance the coherence of frame-wise visual features related to the same object. Our proposed method, termed autogenic language embedding for visual feature enhancement, strengthens point correspondence in long-term sequences. Unlike existing visual-language schemes, our approach learns text embeddings from visual features through a dedicated mapping network, enabling seamless adaptation to various tracking tasks without explicit text annotations. Additionally, we introduce a consistency decoder that efficiently integrates text tokens into visual features with minimal computational overhead. Through enhanced visual consistency, our approach significantly improves tracking trajectories in lengthy videos with substantial appearance variations. Extensive experiments on widely-used tracking benchmarks demonstrate the superior performance of our method, showcasing notable enhancements compared to trackers relying solely on visual cues.
Foundation Model Engineering: Engineering Foundation Models Just as Engineering Software
Jul 11, 2024



By treating data and models as the source code, Foundation Models (FMs) become a new type of software. Mirroring the concept of software crisis, the increasing complexity of FMs making FM crisis a tangible concern in the coming decade, appealing for new theories and methodologies from the field of software engineering. In this paper, we outline our vision of introducing Foundation Model (FM) engineering, a strategic response to the anticipated FM crisis with principled engineering methodologies. FM engineering aims to mitigate potential issues in FM development and application through the introduction of declarative, automated, and unified programming interfaces for both data and model management, reducing the complexities involved in working with FMs by providing a more structured and intuitive process for developers. Through the establishment of FM engineering, we aim to provide a robust, automated, and extensible framework that addresses the imminent challenges, and discovering new research opportunities for the software engineering field.
Boosting Medical Image Synthesis via Registration-guided Consistency and Disentanglement Learning
Jul 10, 2024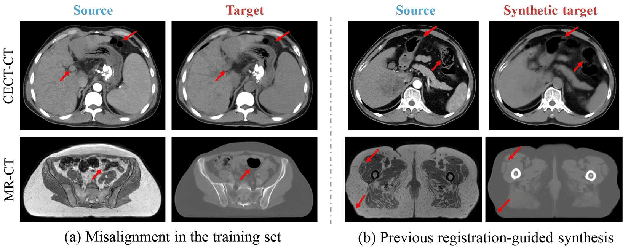
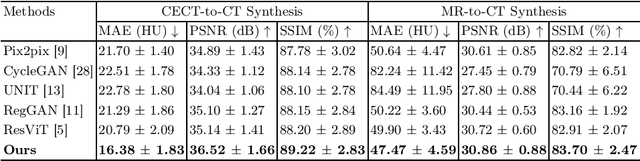
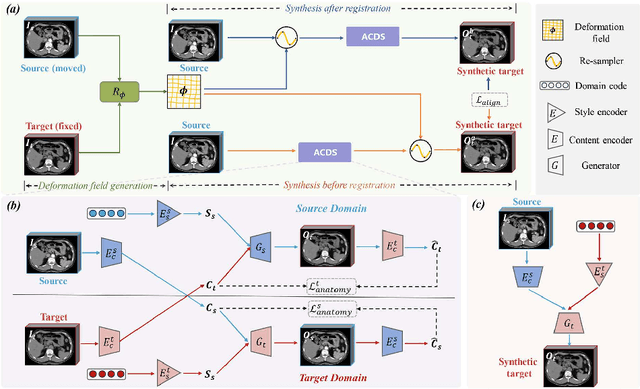

Medical image synthesis remains challenging due to misalignment noise during training. Existing methods have attempted to address this challenge by incorporating a registration-guided module. However, these methods tend to overlook the task-specific constraints on the synthetic and registration modules, which may cause the synthetic module to still generate spatially aligned images with misaligned target images during training, regardless of the registration module's function. Therefore, this paper proposes registration-guided consistency and incorporates disentanglement learning for medical image synthesis. The proposed registration-guided consistency architecture fosters task-specificity within the synthetic and registration modules by applying identical deformation fields before and after synthesis, while enforcing output consistency through an alignment loss. Moreover, the synthetic module is designed to possess the capability of disentangling anatomical structures and specific styles across various modalities. An anatomy consistency loss is introduced to further compel the synthetic module to preserve geometrical integrity within latent spaces. Experiments conducted on both an in-house abdominal CECT-CT dataset and a publicly available pelvic MR-CT dataset have demonstrated the superiority of the proposed method.
SoftDedup: an Efficient Data Reweighting Method for Speeding Up Language Model Pre-training
Jul 09, 2024



The effectiveness of large language models (LLMs) is often hindered by duplicated data in their extensive pre-training datasets. Current approaches primarily focus on detecting and removing duplicates, which risks the loss of valuable information and neglects the varying degrees of duplication. To address this, we propose a soft deduplication method that maintains dataset integrity while selectively reducing the sampling weight of data with high commonness. Central to our approach is the concept of "data commonness", a metric we introduce to quantify the degree of duplication by measuring the occurrence probabilities of samples using an n-gram model. Empirical analysis shows that this method significantly improves training efficiency, achieving comparable perplexity scores with at least a 26% reduction in required training steps. Additionally, it enhances average few-shot downstream accuracy by 1.77% when trained for an equivalent duration. Importantly, this approach consistently improves performance, even on rigorously deduplicated datasets, indicating its potential to complement existing methods and become a standard pre-training process for LLMs.
Boosting Consistency in Story Visualization with Rich-Contextual Conditional Diffusion Models
Jul 02, 2024



Recent research showcases the considerable potential of conditional diffusion models for generating consistent stories. However, current methods, which predominantly generate stories in an autoregressive and excessively caption-dependent manner, often underrate the contextual consistency and relevance of frames during sequential generation. To address this, we propose a novel Rich-contextual Conditional Diffusion Models (RCDMs), a two-stage approach designed to enhance story generation's semantic consistency and temporal consistency. Specifically, in the first stage, the frame-prior transformer diffusion model is presented to predict the frame semantic embedding of the unknown clip by aligning the semantic correlations between the captions and frames of the known clip. The second stage establishes a robust model with rich contextual conditions, including reference images of the known clip, the predicted frame semantic embedding of the unknown clip, and text embeddings of all captions. By jointly injecting these rich contextual conditions at the image and feature levels, RCDMs can generate semantic and temporal consistency stories. Moreover, RCDMs can generate consistent stories with a single forward inference compared to autoregressive models. Our qualitative and quantitative results demonstrate that our proposed RCDMs outperform in challenging scenarios. The code and model will be available at https://github.com/muzishen/RCDMs.
An eight-neuron network for quadruped locomotion with hip-knee joint control
Jun 19, 2024The gait generator, which is capable of producing rhythmic signals for coordinating multiple joints, is an essential component in the quadruped robot locomotion control framework. The biological counterpart of the gait generator is the Central Pattern Generator (abbreviated as CPG), a small neural network consisting of interacting neurons. Inspired by this architecture, researchers have designed artificial neural networks composed of simulated neurons or oscillator equations. Despite the widespread application of these designed CPGs in various robot locomotion controls, some issues remain unaddressed, including: (1) Simplistic network designs often overlook the symmetry between signal and network structure, resulting in fewer gait patterns than those found in nature. (2) Due to minimal architectural consideration, quadruped control CPGs typically consist of only four neurons, which restricts the network's direct control to leg phases rather than joint coordination. (3) Gait changes are achieved by varying the neuron couplings or the assignment between neurons and legs, rather than through external stimulation. We apply symmetry theory to design an eight-neuron network, composed of Stein neuronal models, capable of achieving five gaits and coordinated control of the hip-knee joints. We validate the signal stability of this network as a gait generator through numerical simulations, which reveal various results and patterns encountered during gait transitions using neuronal stimulation. Based on these findings, we have developed several successful gait transition strategies through neuronal stimulations. Using a commercial quadruped robot model, we demonstrate the usability and feasibility of this network by implementing motion control and gait transitions.
WindowMixer: Intra-Window and Inter-Window Modeling for Time Series Forecasting
Jun 14, 2024Time series forecasting (TSF) is crucial in fields like economic forecasting, weather prediction, traffic flow analysis, and public health surveillance. Real-world time series data often include noise, outliers, and missing values, making accurate forecasting challenging. Traditional methods model point-to-point relationships, which limits their ability to capture complex temporal patterns and increases their susceptibility to noise.To address these issues, we introduce the WindowMixer model, built on an all-MLP framework. WindowMixer leverages the continuous nature of time series by examining temporal variations from a window-based perspective. It decomposes time series into trend and seasonal components, handling them individually. For trends, a fully connected (FC) layer makes predictions. For seasonal components, time windows are projected to produce window tokens, processed by Intra-Window-Mixer and Inter-Window-Mixer modules. The Intra-Window-Mixer models relationships within each window, while the Inter-Window-Mixer models relationships between windows. This approach captures intricate patterns and long-range dependencies in the data.Experiments show WindowMixer consistently outperforms existing methods in both long-term and short-term forecasting tasks.
Tokenize features, enhancing tables: the FT-TABPFN model for tabular classification
Jun 11, 2024Traditional methods for tabular classification usually rely on supervised learning from scratch, which requires extensive training data to determine model parameters. However, a novel approach called Prior-Data Fitted Networks (TabPFN) has changed this paradigm. TabPFN uses a 12-layer transformer trained on large synthetic datasets to learn universal tabular representations. This method enables fast and accurate predictions on new tasks with a single forward pass and no need for additional training. Although TabPFN has been successful on small datasets, it generally shows weaker performance when dealing with categorical features. To overcome this limitation, we propose FT-TabPFN, which is an enhanced version of TabPFN that includes a novel Feature Tokenization layer to better handle classification features. By fine-tuning it for downstream tasks, FT-TabPFN not only expands the functionality of the original model but also significantly improves its applicability and accuracy in tabular classification. Our full source code is available for community use and development.
V-Express: Conditional Dropout for Progressive Training of Portrait Video Generation
Jun 04, 2024


In the field of portrait video generation, the use of single images to generate portrait videos has become increasingly prevalent. A common approach involves leveraging generative models to enhance adapters for controlled generation. However, control signals (e.g., text, audio, reference image, pose, depth map, etc.) can vary in strength. Among these, weaker conditions often struggle to be effective due to interference from stronger conditions, posing a challenge in balancing these conditions. In our work on portrait video generation, we identified audio signals as particularly weak, often overshadowed by stronger signals such as facial pose and reference image. However, direct training with weak signals often leads to difficulties in convergence. To address this, we propose V-Express, a simple method that balances different control signals through the progressive training and the conditional dropout operation. Our method gradually enables effective control by weak conditions, thereby achieving generation capabilities that simultaneously take into account the facial pose, reference image, and audio. The experimental results demonstrate that our method can effectively generate portrait videos controlled by audio. Furthermore, a potential solution is provided for the simultaneous and effective use of conditions of varying strengths.