 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal ultra-scale learning with tri-modalities of renal biopsy images for glomerular multi-disease auxiliary diagnosis
Dec 17, 2025



Constructing a multi-modal automatic classification model based on three types of renal biopsy images can assist pathologists in glomerular multi-disease identification. However, the substantial scale difference between transmission electron microscopy (TEM) image features at the nanoscale and optical microscopy (OM) or immunofluorescence microscopy (IM) images at the microscale poses a challenge for existing multi-modal and multi-scale models in achieving effective feature fusion and improving classification accuracy. To address this issue, we propose a cross-modal ultra-scale learning network (CMUS-Net) for the auxiliary diagnosis of multiple glomerular diseases. CMUS-Net utilizes multiple ultrastructural information to bridge the scale difference between nanometer and micrometer images. Specifically, we introduce a sparse multi-instance learning module to aggregate features from TEM images. Furthermore, we design a cross-modal scale attention module to facilitate feature interaction, enhancing pathological semantic information. Finally, multiple loss functions are combined, allowing the model to weigh the importance among different modalities and achieve precise classification of glomerular diseases. Our method follows the conventional process of renal biopsy pathology diagnosis and, for the first time, performs automatic classification of multiple glomerular diseases including IgA nephropathy (IgAN), membranous nephropathy (MN), and lupus nephritis (LN) based on images from three modalities and two scales. On an in-house dataset, CMUS-Net achieves an ACC of 95.37+/-2.41%, an AUC of 99.05+/-0.53%, and an F1-score of 95.32+/-2.41%. Extensive experiments demonstrate that CMUS-Net outperforms other well-known multi-modal or multi-scale methods and show its generalization capability in staging MN. Code is available at https://github.com/SMU-GL-Group/MultiModal_lkx/tree/main.
Unleashing Diffusion and State Space Models for Medical Image Segmentation
Jun 15, 2025



Existing segmentation models trained on a single medical imaging dataset often lack robustness when encountering unseen organs or tumors. Developing a robust model capable of identifying rare or novel tumor categories not present during training is crucial for advancing medical imaging applications. We propose DSM, a novel framework that leverages diffusion and state space models to segment unseen tumor categories beyond the training data. DSM utilizes two sets of object queries trained within modified attention decoders to enhance classification accuracy. Initially, the model learns organ queries using an object-aware feature grouping strategy to capture organ-level visual features. It then refines tumor queries by focusing on diffusion-based visual prompts, enabling precise segmentation of previously unseen tumors. Furthermore, we incorporate diffusion-guided feature fusion to improve semantic segmentation performance. By integrating CLIP text embeddings, DSM captures category-sensitive classes to improve linguistic transfer knowledge, thereby enhancing the model's robustness across diverse scenarios and multi-label tasks. Extensive experiments demonstrate the superior performance of DSM in various tumor segmentation tasks. Code is available at https://github.com/Rows21/KMax-Mamba.
Boosting Medical Image Synthesis via Registration-guided Consistency and Disentanglement Learning
Jul 10, 2024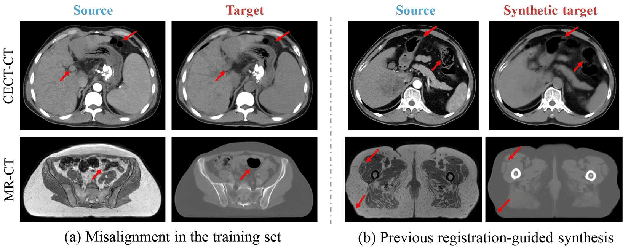
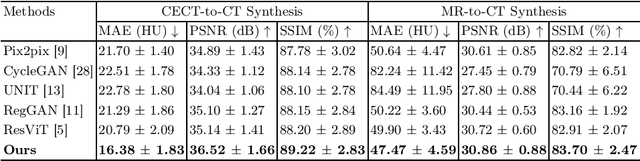
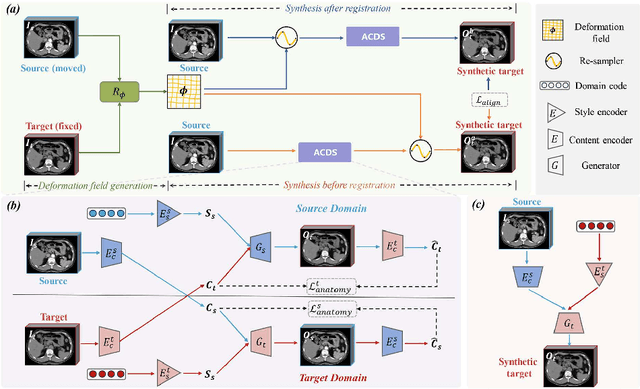

Medical image synthesis remains challenging due to misalignment noise during training. Existing methods have attempted to address this challenge by incorporating a registration-guided module. However, these methods tend to overlook the task-specific constraints on the synthetic and registration modules, which may cause the synthetic module to still generate spatially aligned images with misaligned target images during training, regardless of the registration module's function. Therefore, this paper proposes registration-guided consistency and incorporates disentanglement learning for medical image synthesis. The proposed registration-guided consistency architecture fosters task-specificity within the synthetic and registration modules by applying identical deformation fields before and after synthesis, while enforcing output consistency through an alignment loss. Moreover, the synthetic module is designed to possess the capability of disentangling anatomical structures and specific styles across various modalities. An anatomy consistency loss is introduced to further compel the synthetic module to preserve geometrical integrity within latent spaces. Experiments conducted on both an in-house abdominal CECT-CT dataset and a publicly available pelvic MR-CT dataset have demonstrated the superiority of the proposed method.
DoseDiff: Distance-aware Diffusion Model for Dose Prediction in Radiotherapy
Jun 28, 2023



Treatment planning is a critical component of the radiotherapy workflow, typically carried out by a medical physicist using a time-consuming trial-and-error manner. Previous studies have proposed knowledge-based or deep learning-based methods for predicting dose distribution maps to assist medical physicists in improving the efficiency of treatment planning. However, these dose prediction methods usuallylack the effective utilization of distance information between surrounding tissues andtargets or organs-at-risk (OARs). Moreover, they are poor in maintaining the distribution characteristics of ray paths in the predicted dose distribution maps, resulting in a loss of valuable information obtained by medical physicists. In this paper, we propose a distance-aware diffusion model (DoseDiff) for precise prediction of dose distribution. We define dose prediction as a sequence of denoising steps, wherein the predicted dose distribution map is generated with the conditions of the CT image and signed distance maps (SDMs). The SDMs are obtained by a distance transformation from the masks of targets or OARs, which provide the distance information from each pixel in the image to the outline of the targets or OARs. Besides, we propose a multiencoder and multi-scale fusion network (MMFNet) that incorporates a multi-scale fusion and a transformer-based fusion module to enhance information fusion between the CT image and SDMs at the feature level. Our model was evaluated on two datasets collected from patients with breast cancer and nasopharyngeal cancer, respectively. The results demonstrate that our DoseDiff outperforms the state-of-the-art dose prediction methods in terms of both quantitative and visual quality.