 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPrompt: Exploring the Extreme of Prompt Tuning
Oct 10, 2022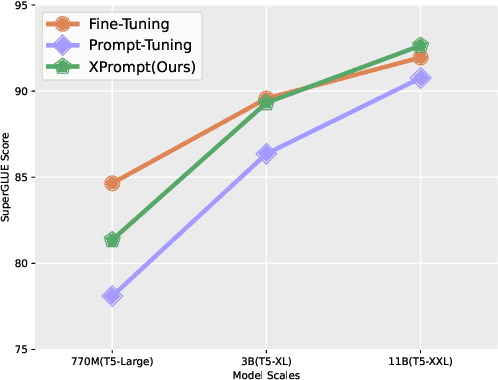
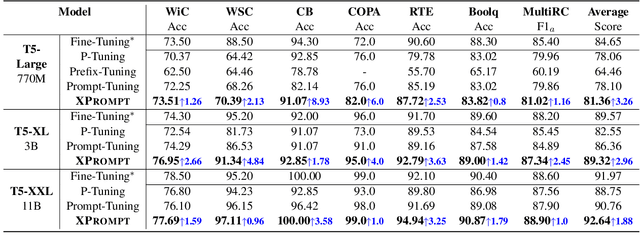
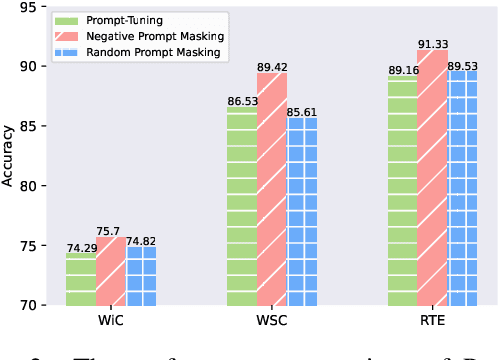
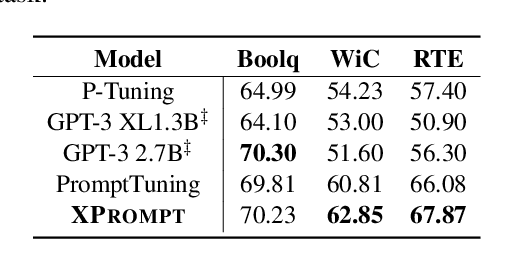
Prompt tuning learns soft prompts to condition frozen Pre-trained Language Models (PLMs) for performing downstream tasks in a parameter-efficient manner. While prompt tuning has gradually reached the performance level of fine-tuning as the model scale increases, there is still a large performance gap between prompt tuning and fine-tuning for models of moderate and small scales (typically less than 11B parameters). In this paper, we empirically show that the trained prompt tokens can have a negative impact on a downstream task and thus degrade its performance. To bridge the gap, we propose a novel Prompt tuning model with an eXtremely small scale (XPrompt) under the regime of lottery tickets hypothesis. Specifically, XPrompt eliminates the negative prompt tokens at different granularity levels through a hierarchical structured pruning, yielding a more parameter-efficient prompt yet with a competitive performance. Comprehensive experiments are carried out on SuperGLUE tasks, and the extensive results indicate that XPrompt is able to close the performance gap at smaller model scales.
DABERT: Dual Attention Enhanced BERT for Semantic Matching
Oct 07, 2022
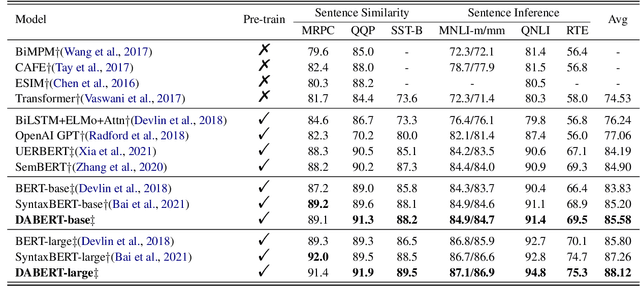
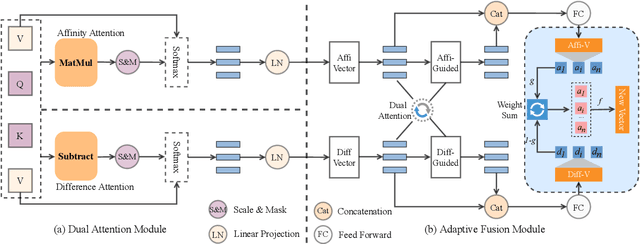
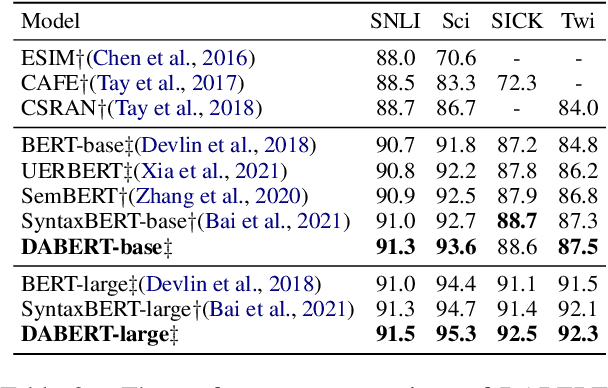
Transformer-based pre-trained language models such as BERT have achieved remarkable results in Semantic Sentence Matching. However, existing models still suffer from insufficient ability to capture subtle differences. Minor noise like word addition, deletion, and modification of sentences may cause flipped predictions. To alleviate this problem, we propose a novel Dual Attention Enhanced BERT (DABERT) to enhance the ability of BERT to capture fine-grained differences in sentence pairs. DABERT comprises (1) Dual Attention module, which measures soft word matches by introducing a new dual channel alignment mechanism to model affinity and difference attention. (2) Adaptive Fusion module, this module uses attention to learn the aggregation of difference and affinity features, and generates a vector describing the matching details of sentence pairs. We conduct extensive experiments on well-studied semantic matching and robustness test datasets, and the experimental results show the effectiveness of our proposed method.
From One to Many: Dynamic Cross Attention Networks for LiDAR and Camera Fusion
Sep 25, 2022
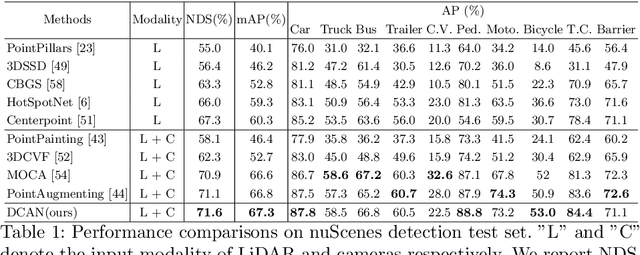
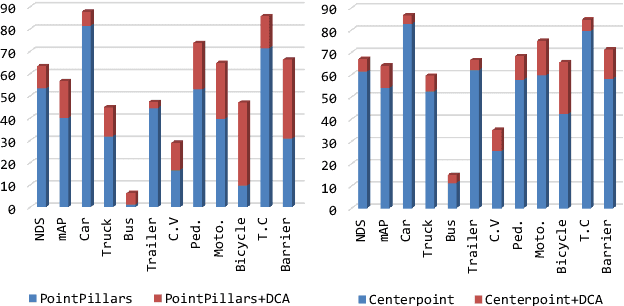
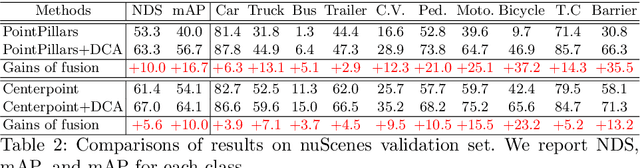
LiDAR and cameras are two complementary sensors for 3D perception in autonomous driving. LiDAR point clouds have accurate spatial and geometry information, while RGB images provide textural and color data for context reasoning. To exploit LiDAR and cameras jointly, existing fusion methods tend to align each 3D point to only one projected image pixel based on calibration, namely one-to-one mapping. However, the performance of these approaches highly relies on the calibration quality, which is sensitive to the temporal and spatial synchronization of sensors. Therefore, we propose a Dynamic Cross Attention (DCA) module with a novel one-to-many cross-modality mapping that learns multiple offsets from the initial projection towards the neighborhood and thus develops tolerance to calibration error. Moreover, a \textit{dynamic query enhancement} is proposed to perceive the model-independent calibration, which further strengthens DCA's tolerance to the initial misalignment. The whole fusion architecture named Dynamic Cross Attention Network (DCAN) exploits multi-level image features and adapts to multiple representations of point clouds, which allows DCA to serve as a plug-in fusion module. Extensive experiments on nuScenes and KITTI prove DCA's effectiveness. The proposed DCAN outperforms state-of-the-art methods on the nuScenes detection challenge.
One-to-Many Semantic Communication Systems: Design, Implementation, Performance Evaluation
Sep 20, 2022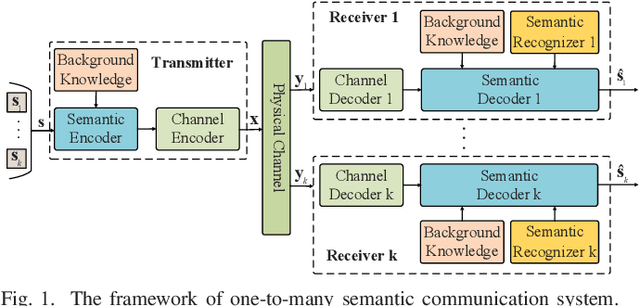
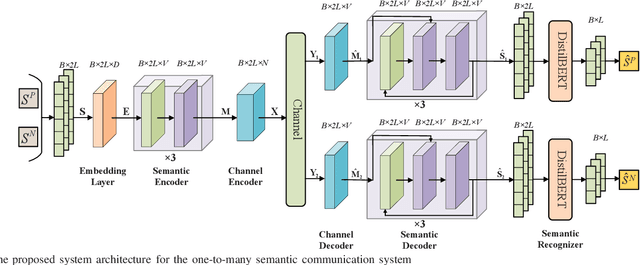
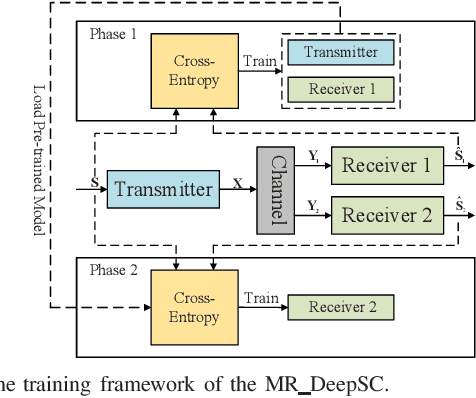
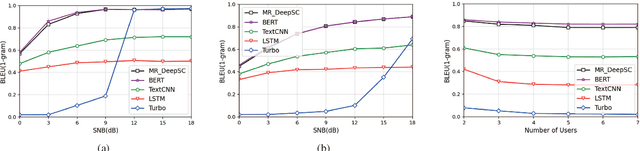
Semantic communication in the 6G era has been deemed a promising communication paradigm to break through the bottleneck of traditional communications. However, its applications for the multi-user scenario, especially the broadcasting case, remain under-explored. To effectively exploit the benefits enabled by semantic communication, in this paper, we propose a one-to-many semantic communication system. Specifically, we propose a deep neural network (DNN) enabled semantic communication system called MR\_DeepSC. By leveraging semantic features for different users, a semantic recognizer based on the pre-trained model, i.e., DistilBERT, is built to distinguish different users. Furthermore, the transfer learning is adopted to speed up the training of new receiver networks. Simulation results demonstrate that the proposed MR\_DeepSC can achieve the best performance in terms of BLEU score than the other benchmarks under different channel conditions, especially in the low signal-to-noise ratio (SNR) regime.
Generalized Intent Discovery: Learning from Open World Dialogue System
Sep 13, 2022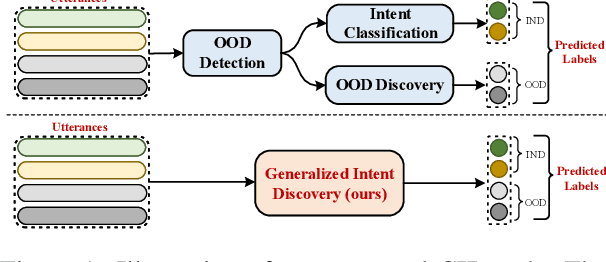

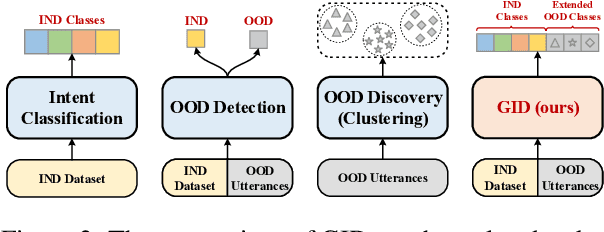

Traditional intent classification models are based on a pre-defined intent set and only recognize limited in-domain (IND) intent classes. But users may input out-of-domain (OOD) queries in a practical dialogue system. Such OOD queries can provide directions for future improvement. In this paper, we define a new task, Generalized Intent Discovery (GID), which aims to extend an IND intent classifier to an open-world intent set including IND and OOD intents. We hope to simultaneously classify a set of labeled IND intent classes while discovering and recognizing new unlabeled OOD types incrementally. We construct three public datasets for different application scenarios and propose two kinds of frameworks, pipeline-based and end-to-end for future work. Further, we conduct exhaustive experiments and qualitative analysis to comprehend key challenges and provide new guidance for future GID research.
Structural Bias for Aspect Sentiment Triplet Extraction
Sep 02, 2022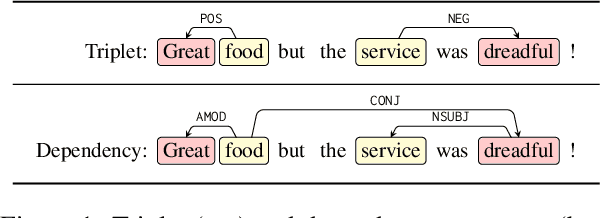
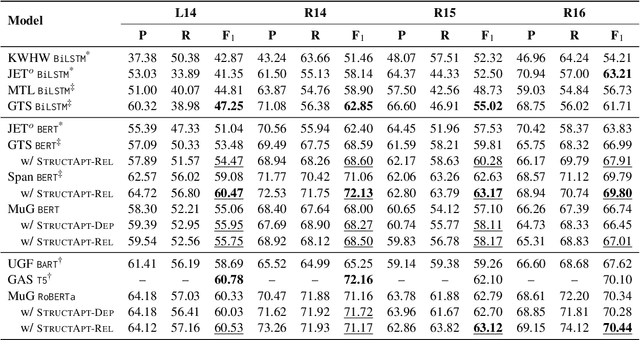
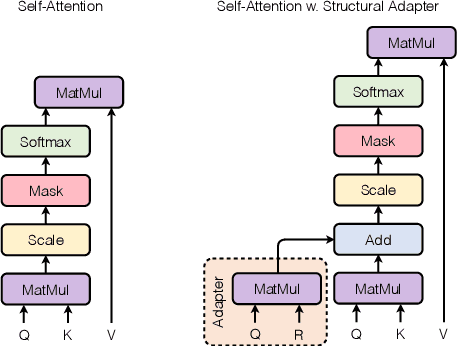
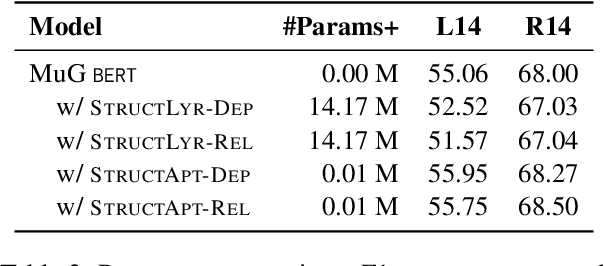
Structural bias has recently been exploited for aspect sentiment triplet extraction (ASTE) and led to improved performance. On the other hand, it is recognized that explicitly incorporating structural bias would have a negative impact on efficiency, whereas pretrained language models (PLMs) can already capture implicit structures. Thus, a natural question arises: Is structural bias still a necessity in the context of PLMs? To answer the question, we propose to address the efficiency issues by using an adapter to integrate structural bias in the PLM and using a cheap-to-compute relative position structure in place of the syntactic dependency structure. Benchmarking evaluation is conducted on the SemEval datasets. The results show that our proposed structural adapter is beneficial to PLMs and achieves state-of-the-art performance over a range of strong baselines, yet with a light parameter demand and low latency. Meanwhile, we give rise to the concern that the current evaluation default with data of small scale is under-confident. Consequently, we release a large-scale dataset for ASTE. The results on the new dataset hint that the structural adapter is confidently effective and efficient to a large scale. Overall, we draw the conclusion that structural bias shall still be a necessity even with PLMs.
Unified Knowledge Prompt Pre-training for Customer Service Dialogues
Aug 31, 2022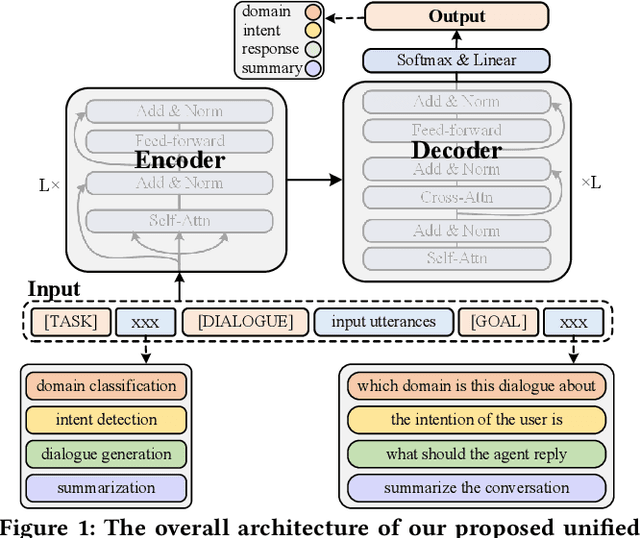
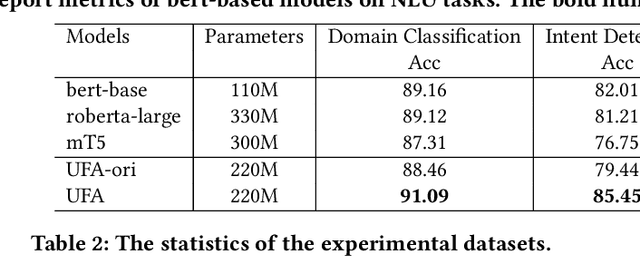
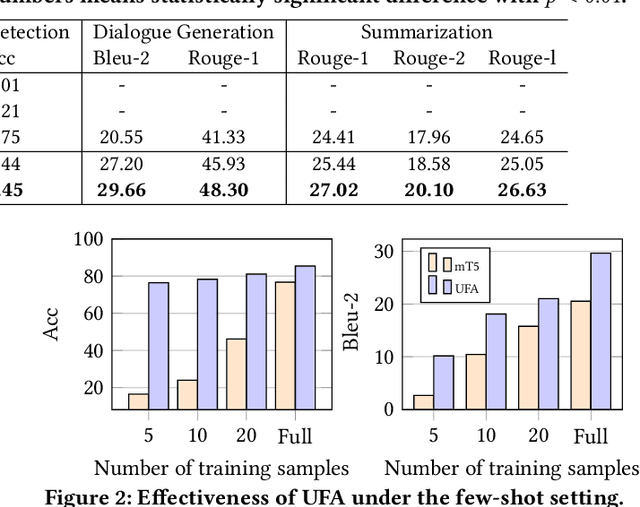
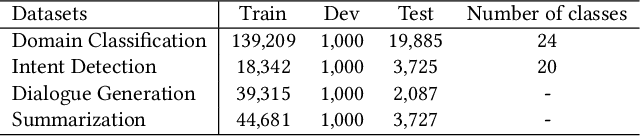
Dialogue bots have been widely applied in customer service scenarios to provide timely and user-friendly experience. These bots must classify the appropriate domain of a dialogue, understand the intent of users, and generate proper responses. Existing dialogue pre-training models are designed only for several dialogue tasks and ignore weakly-supervised expert knowledge in customer service dialogues. In this paper, we propose a novel unified knowledge prompt pre-training framework, UFA (\textbf{U}nified Model \textbf{F}or \textbf{A}ll Tasks), for customer service dialogues. We formulate all the tasks of customer service dialogues as a unified text-to-text generation task and introduce a knowledge-driven prompt strategy to jointly learn from a mixture of distinct dialogue tasks. We pre-train UFA on a large-scale Chinese customer service corpus collected from practical scenarios and get significant improvements on both natural language understanding (NLU) and natural language generation (NLG) benchmarks.
CLOWER: A Pre-trained Language Model with Contrastive Learning over Word and Character Representations
Aug 23, 2022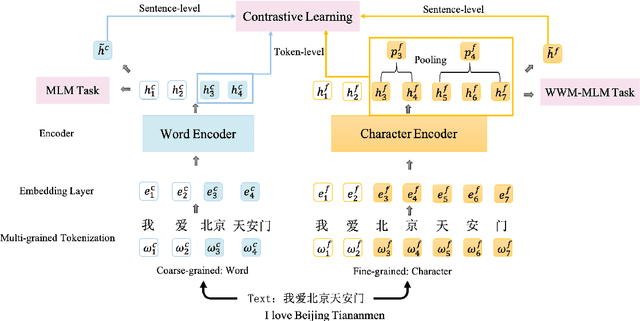
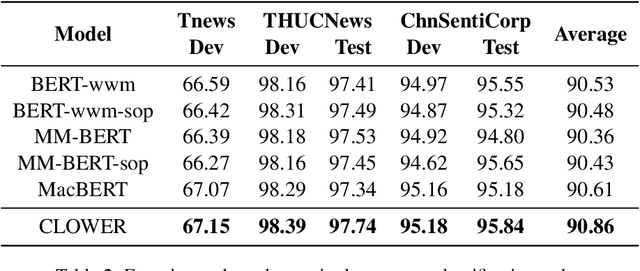
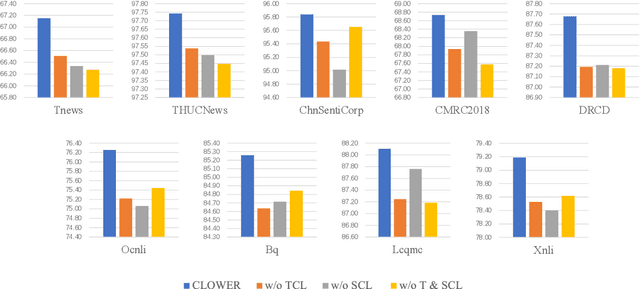
Pre-trained Language Models (PLMs) have achieved remarkable performance gains across numerous downstream tasks in natural language understanding. Various Chinese PLMs have been successively proposed for learning better Chinese language representation. However, most current models use Chinese characters as inputs and are not able to encode semantic information contained in Chinese words. While recent pre-trained models incorporate both words and characters simultaneously, they usually suffer from deficient semantic interactions and fail to capture the semantic relation between words and characters. To address the above issues, we propose a simple yet effective PLM CLOWER, which adopts the Contrastive Learning Over Word and charactER representations. In particular, CLOWER implicitly encodes the coarse-grained information (i.e., words) into the fine-grained representations (i.e., characters) through contrastive learning on multi-grained information. CLOWER is of great value in realistic scenarios since it can be easily incorporated into any existing fine-grained based PLMs without modifying the production pipelines.Extensive experiments conducted on a range of downstream tasks demonstrate the superior performance of CLOWER over several state-of-the-art baselines.
Mask and Reason: Pre-Training Knowledge Graph Transformers for Complex Logical Queries
Aug 16, 2022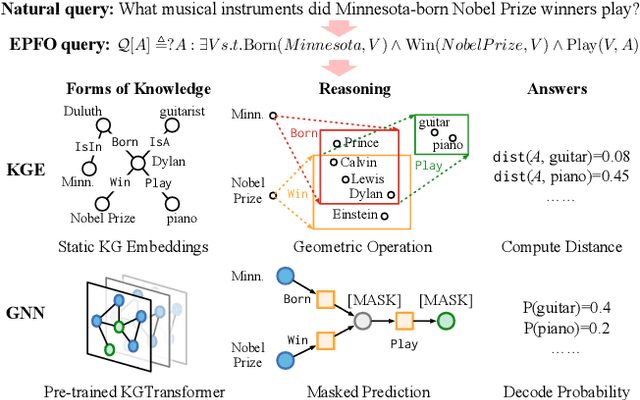
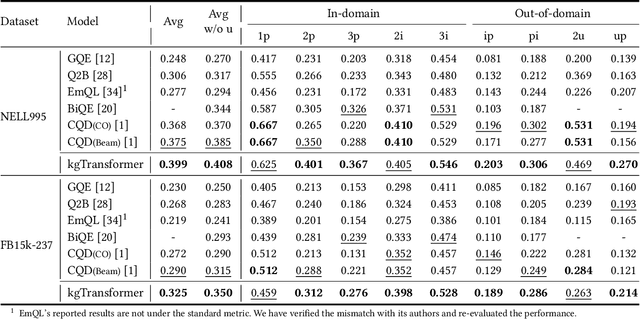
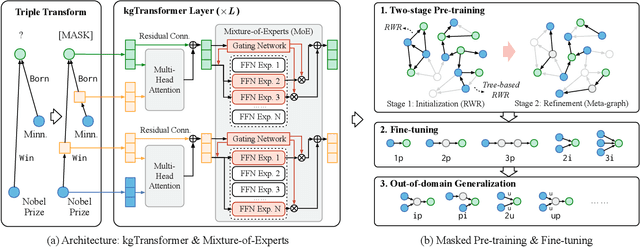
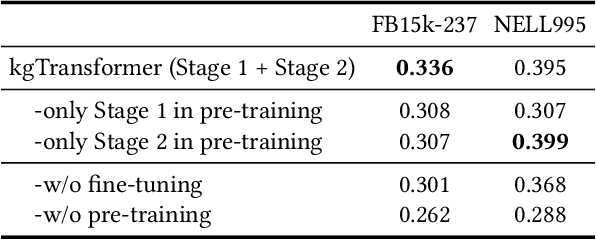
Knowledge graph (KG) embeddings have been a mainstream approach for reasoning over incomplete KGs. However, limited by their inherently shallow and static architectures, they can hardly deal with the rising focus on complex logical queries, which comprise logical operators, imputed edges, multiple source entities, and unknown intermediate entities. In this work, we present the Knowledge Graph Transformer (kgTransformer) with masked pre-training and fine-tuning strategies. We design a KG triple transformation method to enable Transformer to handle KGs, which is further strengthened by the Mixture-of-Experts (MoE) sparse activation. We then formulate the complex logical queries as masked prediction and introduce a two-stage masked pre-training strategy to improve transferability and generalizability. Extensive experiments on two benchmarks demonstrate that kgTransformer can consistently outperform both KG embedding-based baselines and advanced encoders on nine in-domain and out-of-domain reasoning tasks. Additionally, kgTransformer can reason with explainability via providing the full reasoning paths to interpret given answers.
Long Short-Term Preference Modeling for Continuous-Time Sequential Recommendation
Aug 01, 2022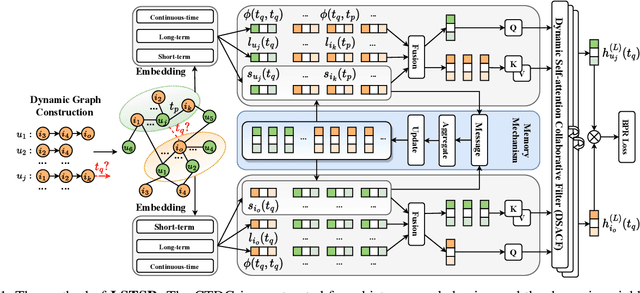

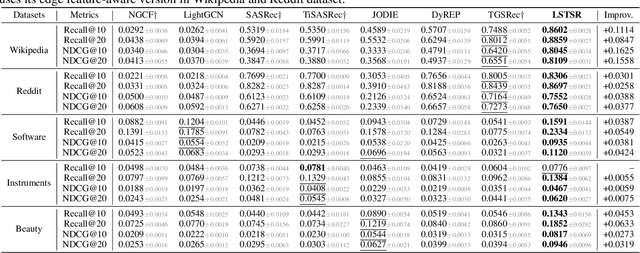
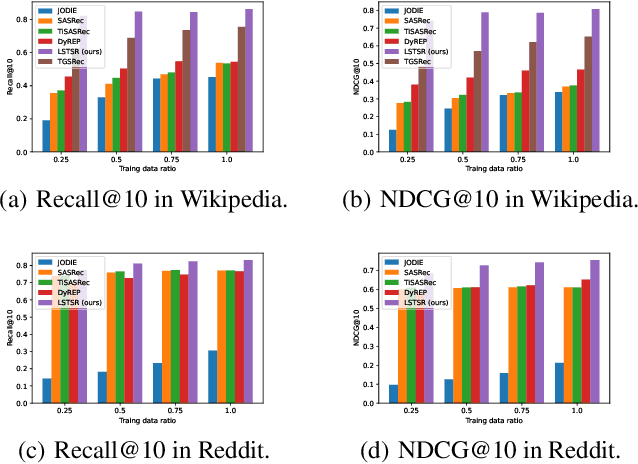
Modeling the evolution of user preference is essential in recommender systems. Recently, dynamic graph-based methods have been studied and achieved SOTA for recommendation, majority of which focus on user's stable long-term preference. However, in real-world scenario, user's short-term preference evolves over time dynamically. Although there exists sequential methods that attempt to capture it, how to model the evolution of short-term preference with dynamic graph-based methods has not been well-addressed yet. In particular: 1) existing methods do not explicitly encode and capture the evolution of short-term preference as sequential methods do; 2) simply using last few interactions is not enough for modeling the changing trend. In this paper, we propose Long Short-Term Preference Modeling for Continuous-Time Sequential Recommendation (LSTSR) to capture the evolution of short-term preference under dynamic graph. Specifically, we explicitly encode short-term preference and optimize it via memory mechanism, which has three key operations: Message, Aggregate and Update. Our memory mechanism can not only store one-hop information, but also trigger with new interactions online. Extensive experiments conducted on five public datasets show that LSTSR consistently outperforms many state-of-the-art recommendation methods across various lines.