 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPrompt: Exploring the Extreme of Prompt Tuning
Oct 10, 2022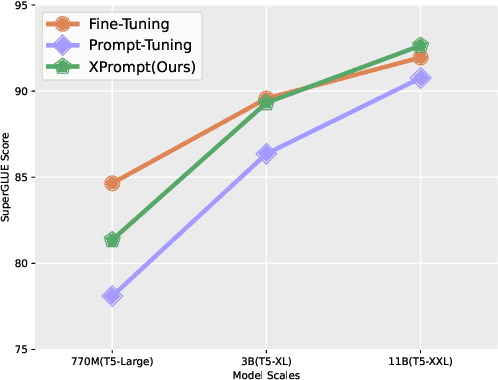
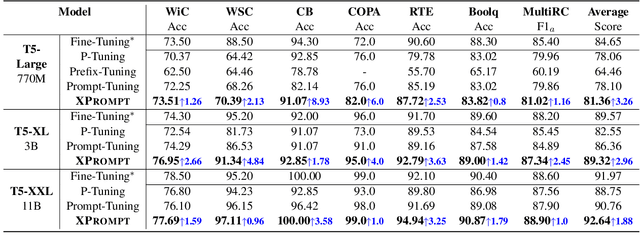
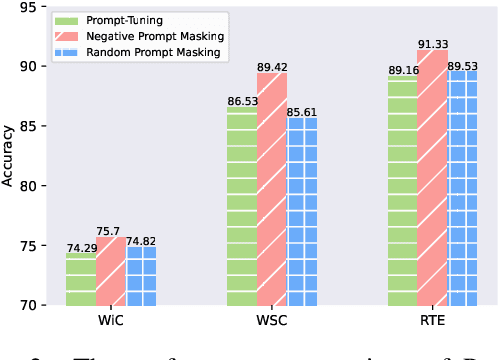
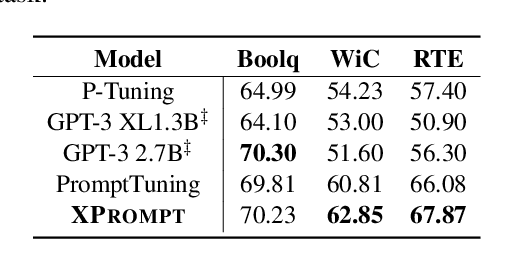
Prompt tuning learns soft prompts to condition frozen Pre-trained Language Models (PLMs) for performing downstream tasks in a parameter-efficient manner. While prompt tuning has gradually reached the performance level of fine-tuning as the model scale increases, there is still a large performance gap between prompt tuning and fine-tuning for models of moderate and small scales (typically less than 11B parameters). In this paper, we empirically show that the trained prompt tokens can have a negative impact on a downstream task and thus degrade its performance. To bridge the gap, we propose a novel Prompt tuning model with an eXtremely small scale (XPrompt) under the regime of lottery tickets hypothesis. Specifically, XPrompt eliminates the negative prompt tokens at different granularity levels through a hierarchical structured pruning, yielding a more parameter-efficient prompt yet with a competitive performance. Comprehensive experiments are carried out on SuperGLUE tasks, and the extensive results indicate that XPrompt is able to close the performance gap at smaller model scales.
Structural Bias for Aspect Sentiment Triplet Extraction
Sep 02, 2022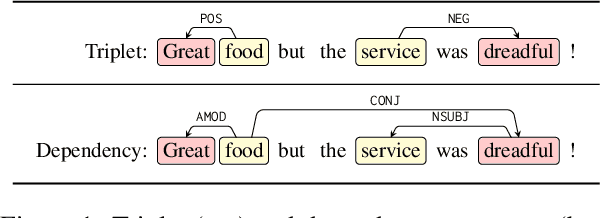
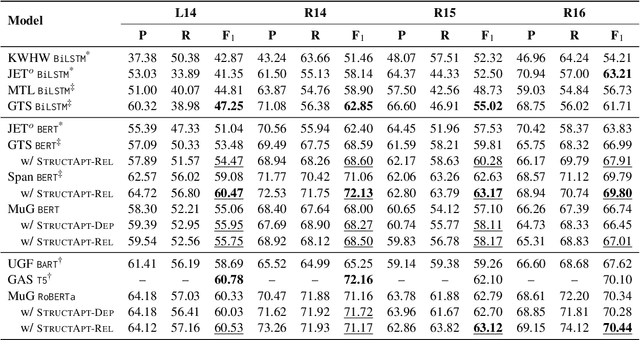
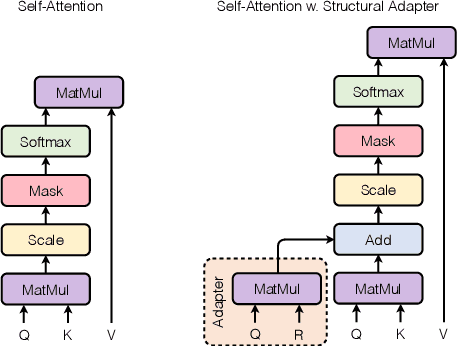
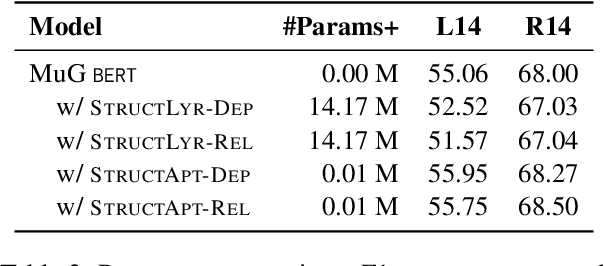
Structural bias has recently been exploited for aspect sentiment triplet extraction (ASTE) and led to improved performance. On the other hand, it is recognized that explicitly incorporating structural bias would have a negative impact on efficiency, whereas pretrained language models (PLMs) can already capture implicit structures. Thus, a natural question arises: Is structural bias still a necessity in the context of PLMs? To answer the question, we propose to address the efficiency issues by using an adapter to integrate structural bias in the PLM and using a cheap-to-compute relative position structure in place of the syntactic dependency structure. Benchmarking evaluation is conducted on the SemEval datasets. The results show that our proposed structural adapter is beneficial to PLMs and achieves state-of-the-art performance over a range of strong baselines, yet with a light parameter demand and low latency. Meanwhile, we give rise to the concern that the current evaluation default with data of small scale is under-confident. Consequently, we release a large-scale dataset for ASTE. The results on the new dataset hint that the structural adapter is confidently effective and efficient to a large scale. Overall, we draw the conclusion that structural bias shall still be a necessity even with PLMs.
A Multibias-mitigated and Sentiment Knowledge Enriched Transformer for Debiasing in Multimodal Conversational Emotion Recognition
Jul 17, 2022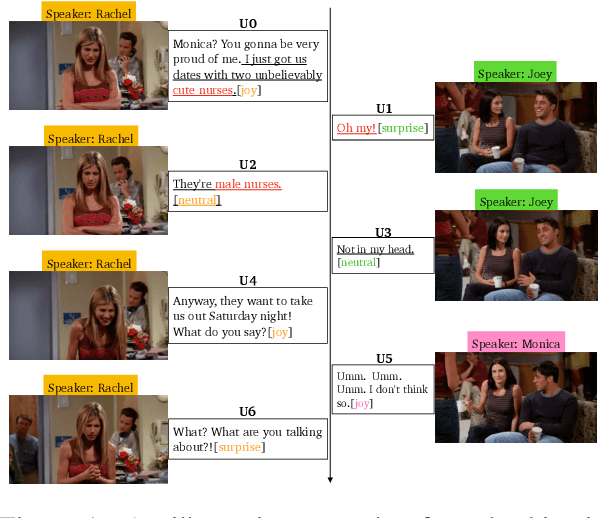

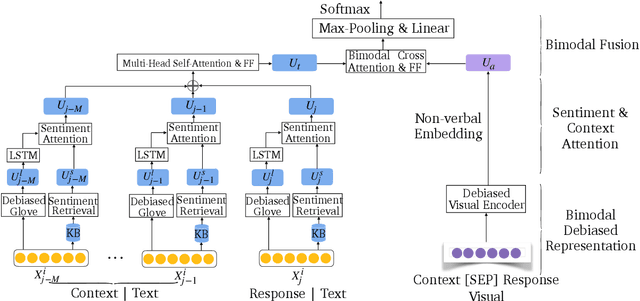
Multimodal emotion recognition in conversations (mERC) is an active research topic in natural language processing (NLP), which aims to predict human's emotional states in communications of multiple modalities, e,g., natural language and facial gestures. Innumerable implicit prejudices and preconceptions fill human language and conversations, leading to the question of whether the current data-driven mERC approaches produce a biased error. For example, such approaches may offer higher emotional scores on the utterances by females than males. In addition, the existing debias models mainly focus on gender or race, where multibias mitigation is still an unexplored task in mERC. In this work, we take the first step to solve these issues by proposing a series of approaches to mitigate five typical kinds of bias in textual utterances (i.e., gender, age, race, religion and LGBTQ+) and visual representations (i.e, gender and age), followed by a Multibias-Mitigated and sentiment Knowledge Enriched bi-modal Transformer (MMKET). Comprehensive experimental results show the effectiveness of the proposed model and prove that the debias operation has a great impact on the classification performance for mERC. We hope our study will benefit the development of bias mitigation in mERC and related emotion studies.
Aspect-specific Context Modeling for Aspect-based Sentiment Analysis
Jul 17, 2022
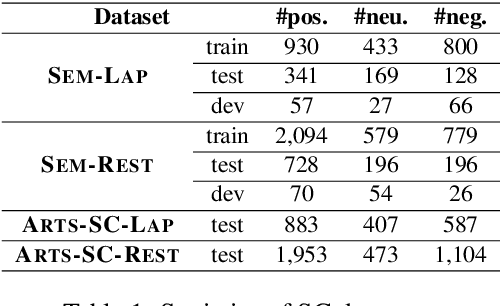
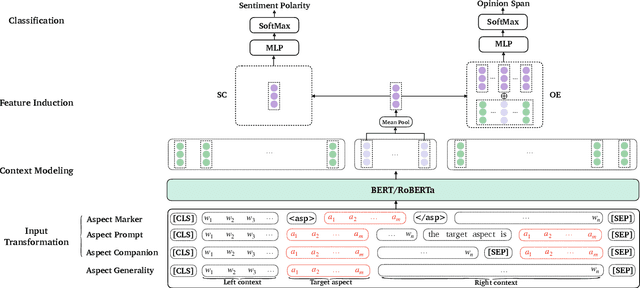
Aspect-based sentiment analysis (ABSA) aims at predicting sentiment polarity (SC) or extracting opinion span (OE) expressed towards a given aspect. Previous work in ABSA mostly relies on rather complicated aspect-specific feature induction. Recently, pretrained language models (PLMs), e.g., BERT, have been used as context modeling layers to simplify the feature induction structures and achieve state-of-the-art performance. However, such PLM-based context modeling can be not that aspect-specific. Therefore, a key question is left under-explored: how the aspect-specific context can be better modeled through PLMs? To answer the question, we attempt to enhance aspect-specific context modeling with PLM in a non-intrusive manner. We propose three aspect-specific input transformations, namely aspect companion, aspect prompt, and aspect marker. Informed by these transformations, non-intrusive aspect-specific PLMs can be achieved to promote the PLM to pay more attention to the aspect-specific context in a sentence. Additionally, we craft an adversarial benchmark for ABSA (advABSA) to see how aspect-specific modeling can impact model robustness. Extensive experimental results on standard and adversarial benchmarks for SC and OE demonstrate the effectiveness and robustness of the proposed method, yielding new state-of-the-art performance on OE and competitive performance on SC.
Adaptable Text Matching via Meta-Weight Regulator
Apr 27, 2022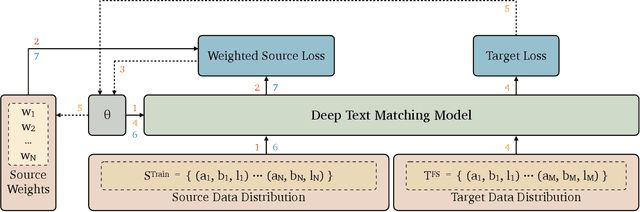
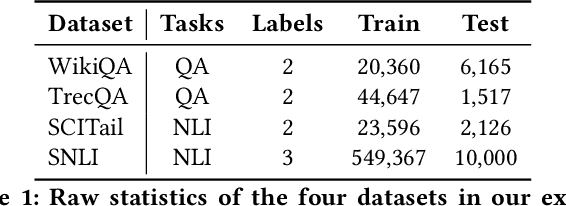
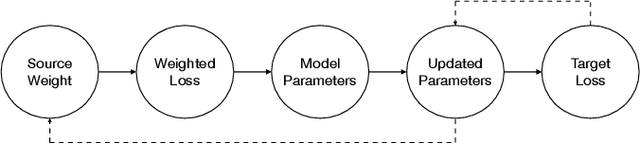
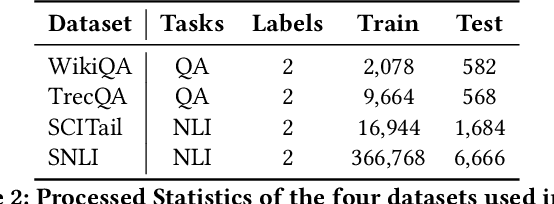
Neural text matching models have been used in a range of applications such as question answering and natural language inference, and have yielded a good performance. However, these neural models are of a limited adaptability, resulting in a decline in performance when encountering test examples from a different dataset or even a different task. The adaptability is particularly important in the few-shot setting: in many cases, there is only a limited amount of labeled data available for a target dataset or task, while we may have access to a richly labeled source dataset or task. However, adapting a model trained on the abundant source data to a few-shot target dataset or task is challenging. To tackle this challenge, we propose a Meta-Weight Regulator (MWR), which is a meta-learning approach that learns to assign weights to the source examples based on their relevance to the target loss. Specifically, MWR first trains the model on the uniformly weighted source examples, and measures the efficacy of the model on the target examples via a loss function. By iteratively performing a (meta) gradient descent, high-order gradients are propagated to the source examples. These gradients are then used to update the weights of source examples, in a way that is relevant to the target performance. As MWR is model-agnostic, it can be applied to any backbone neural model. Extensive experiments are conducted with various backbone text matching models, on four widely used datasets and two tasks. The results demonstrate that our proposed approach significantly outperforms a number of existing adaptation methods and effectively improves the cross-dataset and cross-task adaptability of the neural text matching models in the few-shot setting.
Exploiting Position Bias for Robust Aspect Sentiment Classification
May 29, 2021
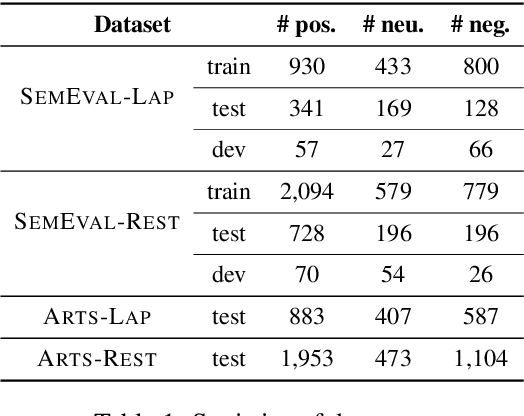
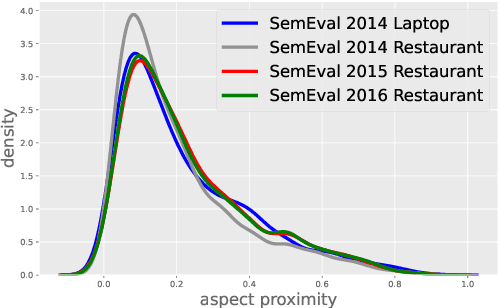
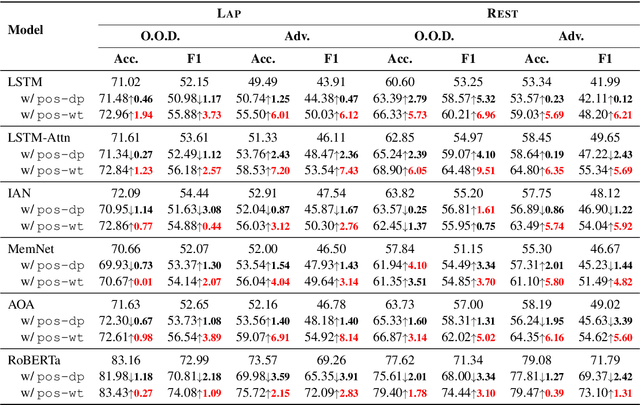
Aspect sentiment classification (ASC) aims at determining sentiments expressed towards different aspects in a sentence. While state-of-the-art ASC models have achieved remarkable performance, they are recently shown to suffer from the issue of robustness. Particularly in two common scenarios: when domains of test and training data are different (out-of-domain scenario) or test data is adversarially perturbed (adversarial scenario), ASC models may attend to irrelevant words and neglect opinion expressions that truly describe diverse aspects. To tackle the challenge, in this paper, we hypothesize that position bias (i.e., the words closer to a concerning aspect would carry a higher degree of importance) is crucial for building more robust ASC models by reducing the probability of mis-attending. Accordingly, we propose two mechanisms for capturing position bias, namely position-biased weight and position-biased dropout, which can be flexibly injected into existing models to enhance representations for classification. Experiments conducted on out-of-domain and adversarial datasets demonstrate that our proposed approaches largely improve the robustness and effectiveness of current models.