 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchTraceAP: A New Benchmark Dataset for Detecting Performance Anti-Patterns in Computer Vision Models
Dec 16, 2025



Identifying and addressing performance anti-patterns in machine learning (ML) models is critical for efficient training and inference, but it typically demands deep expertise spanning system infrastructure, ML models and kernel development. While large tech companies rely on dedicated ML infrastructure engineers to analyze torch traces and benchmarks, such resource-intensive workflows are largely inaccessible to computer vision researchers in general. Among the challenges, pinpointing problematic trace segments within lengthy execution traces remains the most time-consuming task, and is difficult to automate with current ML models, including LLMs. In this work, we present the first benchmark dataset specifically designed to evaluate and improve ML models' ability to detect anti patterns in traces. Our dataset contains over 600 PyTorch traces from diverse computer vision models classification, detection, segmentation, and generation collected across multiple hardware platforms. We also propose a novel iterative approach: a lightweight ML model first detects trace segments with anti patterns, followed by a large language model (LLM) for fine grained classification and targeted feedback. Experimental results demonstrate that our method significantly outperforms unsupervised clustering and rule based statistical techniques for detecting anti pattern regions. Our method also effectively compensates LLM's limited context length and reasoning inefficiencies.
Shape Deformation Networks for Automated Aortic Valve Finite Element Meshing from 3D CT Images
Nov 05, 2025



Accurate geometric modeling of the aortic valve from 3D CT images is essential for biomechanical analysis and patient-specific simulations to assess valve health or make a preoperative plan. However, it remains challenging to generate aortic valve meshes with both high-quality and consistency across different patients. Traditional approaches often produce triangular meshes with irregular topologies, which can result in poorly shaped elements and inconsistent correspondence due to inter-patient anatomical variation. In this work, we address these challenges by introducing a template-fitting pipeline with deep neural networks to generate structured quad (i.e., quadrilateral) meshes from 3D CT images to represent aortic valve geometries. By remeshing aortic valves of all patients with a common quad mesh template, we ensure a uniform mesh topology with consistent node-to-node and element-to-element correspondence across patients. This consistency enables us to simplify the learning objective of the deep neural networks, by employing a loss function with only two terms (i.e., a geometry reconstruction term and a smoothness regularization term), which is sufficient to preserve mesh smoothness and element quality. Our experiments demonstrate that the proposed approach produces high-quality aortic valve surface meshes with improved smoothness and shape quality, while requiring fewer explicit regularization terms compared to the traditional methods. These results highlight that using structured quad meshes for the template and neural network training not only ensures mesh correspondence and quality but also simplifies the training process, thus enhancing the effectiveness and efficiency of aortic valve modeling.
Contrastive Retrieval Heads Improve Attention-Based Re-Ranking
Oct 02, 2025The strong zero-shot and long-context capabilities of recent Large Language Models (LLMs) have paved the way for highly effective re-ranking systems. Attention-based re-rankers leverage attention weights from transformer heads to produce relevance scores, but not all heads are created equally: many contribute noise and redundancy, thus limiting performance. To address this, we introduce CoRe heads, a small set of retrieval heads identified via a contrastive scoring metric that explicitly rewards high attention heads that correlate with relevant documents, while downplaying nodes with higher attention that correlate with irrelevant documents. This relative ranking criterion isolates the most discriminative heads for re-ranking and yields a state-of-the-art list-wise re-ranker. Extensive experiments with three LLMs show that aggregated signals from CoRe heads, constituting less than 1% of all heads, substantially improve re-ranking accuracy over strong baselines. We further find that CoRe heads are concentrated in middle layers, and pruning the computation of final 50% of model layers preserves accuracy while significantly reducing inference time and memory usage.
A Computational Pipeline for Patient-Specific Modeling of Thoracic Aortic Aneurysm: From Medical Image to Finite Element Analysis
Sep 16, 2025The aorta is the body's largest arterial vessel, serving as the primary pathway for oxygenated blood within the systemic circulation. Aortic aneurysms consistently rank among the top twenty causes of mortality in the United States. Thoracic aortic aneurysm (TAA) arises from abnormal dilation of the thoracic aorta and remains a clinically significant disease, ranking as one of the leading causes of death in adults. A thoracic aortic aneurysm ruptures when the integrity of all aortic wall layers is compromised due to elevated blood pressure. Currently, three-dimensional computed tomography (3D CT) is considered the gold standard for diagnosing TAA. The geometric characteristics of the aorta, which can be quantified from medical imaging, and stresses on the aortic wall, which can be obtained by finite element analysis (FEA), are critical in evaluating the risk of rupture and dissection. Deep learning based image segmentation has emerged as a reliable method for extracting anatomical regions of interest from medical images. Voxel based segmentation masks of anatomical structures are typically converted into structured mesh representation to enable accurate simulation. Hexahedral meshes are commonly used in finite element simulations of the aorta due to their computational efficiency and superior simulation accuracy. Due to anatomical variability, patient specific modeling enables detailed assessment of individual anatomical and biomechanics behaviors, supporting precise simulations, accurate diagnoses, and personalized treatment strategies. Finite element (FE) simulations provide valuable insights into the biomechanical behaviors of tissues and organs in clinical studies. Developing accurate FE models represents a crucial initial step in establishing a patient-specific, biomechanically based framework for predicting the risk of TAA.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
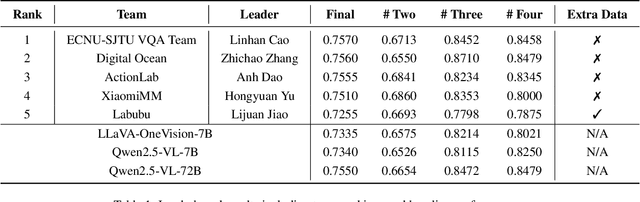
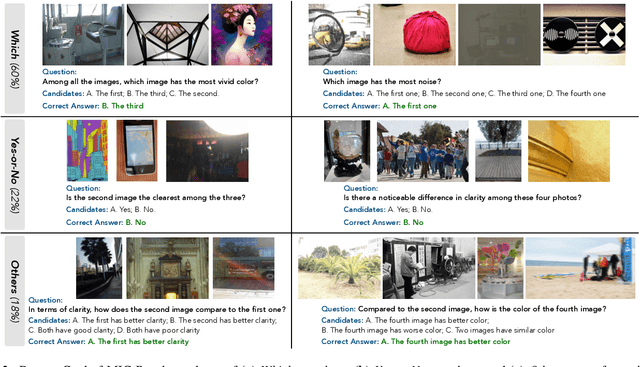
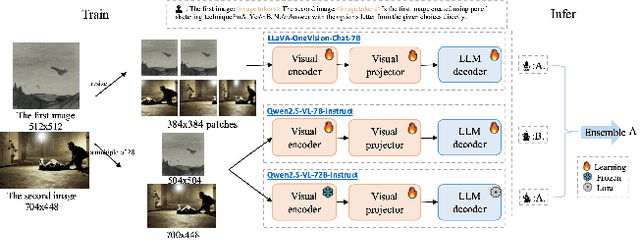
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
ACE-RL: Adaptive Constraint-Enhanced Reward for Long-form Generation Reinforcement Learning
Sep 05, 2025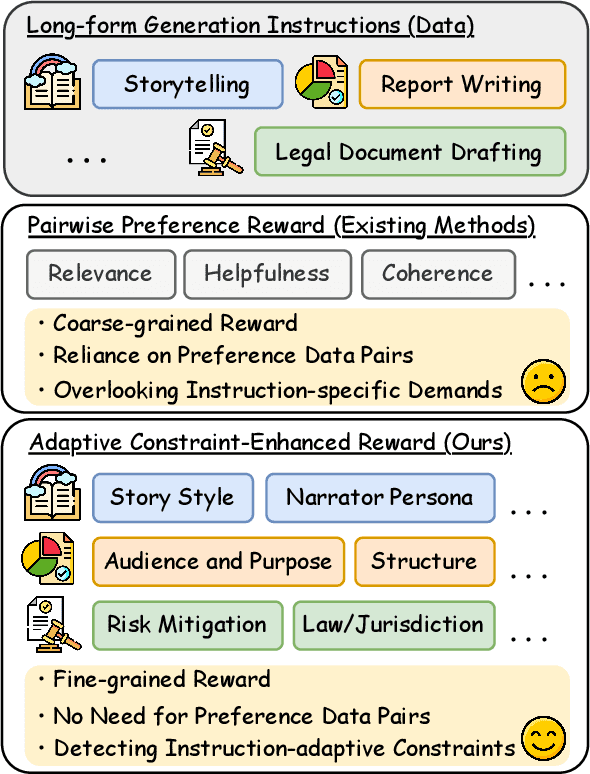

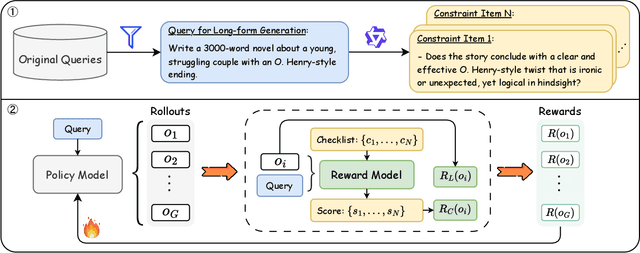
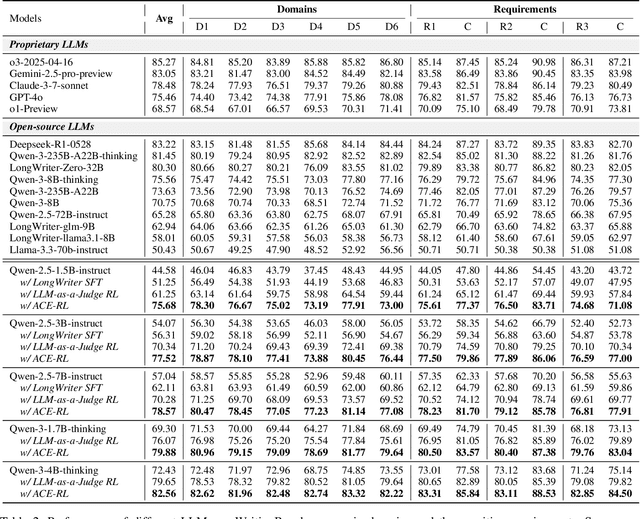
Large Language Models (LLMs) have demonstrated remarkable progress in long-context understanding, yet they face significant challenges in high-quality long-form generation. Existing studies primarily suffer from two limitations: (1) A heavy reliance on scarce, high-quality long-form response data for supervised fine-tuning (SFT) or for pairwise preference reward in reinforcement learning (RL). (2) Focus on coarse-grained quality optimization dimensions, such as relevance, coherence, and helpfulness, overlooking the fine-grained specifics inherent to diverse long-form generation scenarios. To address this issue, we propose a framework using Adaptive Constraint-Enhanced reward for long-form generation Reinforcement Learning (ACE-RL). ACE-RL first automatically deconstructs each instruction into a set of fine-grained, adaptive constraint criteria by identifying its underlying intents and demands. Subsequently, we design a reward mechanism that quantifies the quality of long-form responses based on their satisfaction over corresponding constraints, converting subjective quality evaluation into constraint verification. Finally, we utilize reinforcement learning to guide models toward superior long-form generation capabilities. Experimental results demonstrate that our ACE-RL framework significantly outperforms existing SFT and RL baselines by 20.70% and 7.32% on WritingBench, and our top-performing model even surpasses proprietary systems like GPT-4o by 7.10%, providing a more effective training paradigm for LLMs to generate high-quality content across diverse long-form generation scenarios.
Audio-Assisted Face Video Restoration with Temporal and Identity Complementary Learning
Aug 06, 2025



Face videos accompanied by audio have become integral to our daily lives, while they often suffer from complex degradations. Most face video restoration methods neglect the intrinsic correlations between the visual and audio features, especially in mouth regions. A few audio-aided face video restoration methods have been proposed, but they only focus on compression artifact removal. In this paper, we propose a General Audio-assisted face Video restoration Network (GAVN) to address various types of streaming video distortions via identity and temporal complementary learning. Specifically, GAVN first captures inter-frame temporal features in the low-resolution space to restore frames coarsely and save computational cost. Then, GAVN extracts intra-frame identity features in the high-resolution space with the assistance of audio signals and face landmarks to restore more facial details. Finally, the reconstruction module integrates temporal features and identity features to generate high-quality face videos. Experimental results demonstrate that GAVN outperforms the existing state-of-the-art methods on face video compression artifact removal, deblurring, and super-resolution. Codes will be released upon publication.
CompressedVQA-HDR: Generalized Full-reference and No-reference Quality Assessment Models for Compressed High Dynamic Range Videos
Jul 16, 2025Video compression is a standard procedure applied to all videos to minimize storage and transmission demands while preserving visual quality as much as possible. Therefore, evaluating the visual quality of compressed videos is crucial for guiding the practical usage and further development of video compression algorithms. Although numerous compressed video quality assessment (VQA) methods have been proposed, they often lack the generalization capability needed to handle the increasing diversity of video types, particularly high dynamic range (HDR) content. In this paper, we introduce CompressedVQA-HDR, an effective VQA framework designed to address the challenges of HDR video quality assessment. Specifically, we adopt the Swin Transformer and SigLip 2 as the backbone networks for the proposed full-reference (FR) and no-reference (NR) VQA models, respectively. For the FR model, we compute deep structural and textural similarities between reference and distorted frames using intermediate-layer features extracted from the Swin Transformer as its quality-aware feature representation. For the NR model, we extract the global mean of the final-layer feature maps from SigLip 2 as its quality-aware representation. To mitigate the issue of limited HDR training data, we pre-train the FR model on a large-scale standard dynamic range (SDR) VQA dataset and fine-tune it on the HDRSDR-VQA dataset. For the NR model, we employ an iterative mixed-dataset training strategy across multiple compressed VQA datasets, followed by fine-tuning on the HDRSDR-VQA dataset. Experimental results show that our models achieve state-of-the-art performance compared to existing FR and NR VQA models. Moreover, CompressedVQA-HDR-FR won first place in the FR track of the Generalizable HDR & SDR Video Quality Measurement Grand Challenge at IEEE ICME 2025. The code is available at https://github.com/sunwei925/CompressedVQA-HDR.
Occlusion-Aware 3D Hand-Object Pose Estimation with Masked AutoEncoders
Jun 12, 2025Hand-object pose estimation from monocular RGB images remains a significant challenge mainly due to the severe occlusions inherent in hand-object interactions. Existing methods do not sufficiently explore global structural perception and reasoning, which limits their effectiveness in handling occluded hand-object interactions. To address this challenge, we propose an occlusion-aware hand-object pose estimation method based on masked autoencoders, termed as HOMAE. Specifically, we propose a target-focused masking strategy that imposes structured occlusion on regions of hand-object interaction, encouraging the model to learn context-aware features and reason about the occluded structures. We further integrate multi-scale features extracted from the decoder to predict a signed distance field (SDF), capturing both global context and fine-grained geometry. To enhance geometric perception, we combine the implicit SDF with an explicit point cloud derived from the SDF, leveraging the complementary strengths of both representations. This fusion enables more robust handling of occluded regions by combining the global context from the SDF with the precise local geometry provided by the point cloud. Extensive experiments on challenging DexYCB and HO3Dv2 benchmarks demonstrate that HOMAE achieves state-of-the-art performance in hand-object pose estimation. We will release our code and model.
Mitigating Negative Interference in Multilingual Sequential Knowledge Editing through Null-Space Constraints
Jun 12, 2025Efficiently updating multilingual knowledge in large language models (LLMs), while preserving consistent factual representations across languages, remains a long-standing and unresolved challenge. While deploying separate editing systems for each language might seem viable, this approach incurs substantial costs due to the need to manage multiple models. A more efficient solution involves integrating knowledge updates across all languages into a unified model. However, performing sequential edits across languages often leads to destructive parameter interference, significantly degrading multilingual generalization and the accuracy of injected knowledge. To address this challenge, we propose LangEdit, a novel null-space constrained framework designed to precisely isolate language-specific knowledge updates. The core innovation of LangEdit lies in its ability to project parameter updates for each language onto the orthogonal complement of previous updated subspaces. This approach mathematically guarantees update independence while preserving multilingual generalization capabilities. We conduct a comprehensive evaluation across three model architectures, six languages, and four downstream tasks, demonstrating that LangEdit effectively mitigates parameter interference and outperforms existing state-of-the-art editing methods. Our results highlight its potential for enabling efficient and accurate multilingual knowledge updates in LLMs. The code is available at https://github.com/VRCMF/LangEdit.git.