 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLASS: Test-Time Acceleration for LLMs via Global-Local Neural Importance Aggregation
Aug 19, 2025Deploying Large Language Models (LLMs) on edge hardware demands aggressive, prompt-aware dynamic pruning to reduce computation without degrading quality. Static or predictor-based schemes either lock in a single sparsity pattern or incur extra runtime overhead, and recent zero-shot methods that rely on statistics from a single prompt fail on short prompt and/or long generation scenarios. We introduce A/I-GLASS: Activation- and Impact-based Global-Local neural importance Aggregation for feed-forward network SparSification, two training-free methods that dynamically select FFN units using a rank-aggregation of prompt local and model-intrinsic global neuron statistics. Empirical results across multiple LLMs and benchmarks demonstrate that GLASS significantly outperforms prior training-free methods, particularly in challenging long-form generation scenarios, without relying on auxiliary predictors or adding any inference overhead.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
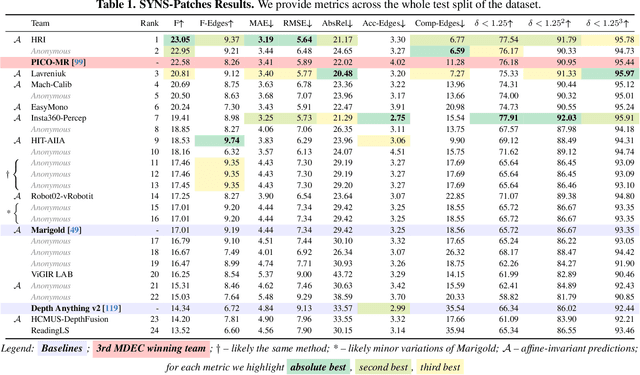
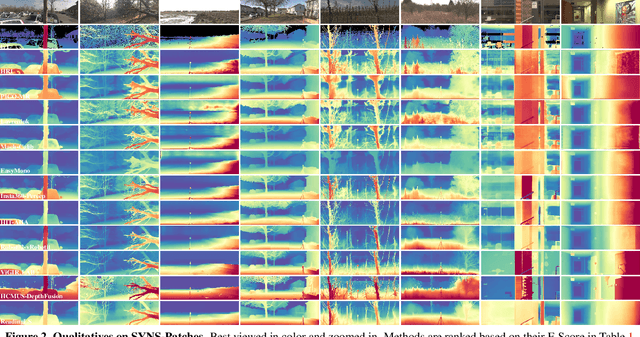
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
PixelMan: Consistent Object Editing with Diffusion Models via Pixel Manipulation and Generation
Dec 18, 2024



Recent research explores the potential of Diffusion Models (DMs) for consistent object editing, which aims to modify object position, size, and composition, etc., while preserving the consistency of objects and background without changing their texture and attributes. Current inference-time methods often rely on DDIM inversion, which inherently compromises efficiency and the achievable consistency of edited images. Recent methods also utilize energy guidance which iteratively updates the predicted noise and can drive the latents away from the original image, resulting in distortions. In this paper, we propose PixelMan, an inversion-free and training-free method for achieving consistent object editing via Pixel Manipulation and generation, where we directly create a duplicate copy of the source object at target location in the pixel space, and introduce an efficient sampling approach to iteratively harmonize the manipulated object into the target location and inpaint its original location, while ensuring image consistency by anchoring the edited image to be generated to the pixel-manipulated image as well as by introducing various consistency-preserving optimization techniques during inference. Experimental evaluations based on benchmark datasets as well as extensive visual comparisons show that in as few as 16 inference steps, PixelMan outperforms a range of state-of-the-art training-based and training-free methods (usually requiring 50 steps) on multiple consistent object editing tasks.
Human-Activity AGV Quality Assessment: A Benchmark Dataset and an Objective Evaluation Metric
Nov 25, 2024



AI-driven video generation techniques have made significant progress in recent years. However, AI-generated videos (AGVs) involving human activities often exhibit substantial visual and semantic distortions, hindering the practical application of video generation technologies in real-world scenarios. To address this challenge, we conduct a pioneering study on human activity AGV quality assessment, focusing on visual quality evaluation and the identification of semantic distortions. First, we construct the AI-Generated Human activity Video Quality Assessment (Human-AGVQA) dataset, consisting of 3,200 AGVs derived from 8 popular text-to-video (T2V) models using 400 text prompts that describe diverse human activities. We conduct a subjective study to evaluate the human appearance quality, action continuity quality, and overall video quality of AGVs, and identify semantic issues of human body parts. Based on Human-AGVQA, we benchmark the performance of T2V models and analyze their strengths and weaknesses in generating different categories of human activities. Second, we develop an objective evaluation metric, named AI-Generated Human activity Video Quality metric (GHVQ), to automatically analyze the quality of human activity AGVs. GHVQ systematically extracts human-focused quality features, AI-generated content-aware quality features, and temporal continuity features, making it a comprehensive and explainable quality metric for human activity AGVs. The extensive experimental results show that GHVQ outperforms existing quality metrics on the Human-AGVQA dataset by a large margin, demonstrating its efficacy in assessing the quality of human activity AGVs. The Human-AGVQA dataset and GHVQ metric will be released in public at https://github.com/zczhang-sjtu/GHVQ.git
LMM-VQA: Advancing Video Quality Assessment with Large Multimodal Models
Aug 26, 2024



The explosive growth of videos on streaming media platforms has underscored the urgent need for effective video quality assessment (VQA) algorithms to monitor and perceptually optimize the quality of streaming videos. However, VQA remains an extremely challenging task due to the diverse video content and the complex spatial and temporal distortions, thus necessitating more advanced methods to address these issues. Nowadays, large multimodal models (LMMs), such as GPT-4V, have exhibited strong capabilities for various visual understanding tasks, motivating us to leverage the powerful multimodal representation ability of LMMs to solve the VQA task. Therefore, we propose the first Large Multi-Modal Video Quality Assessment (LMM-VQA) model, which introduces a novel spatiotemporal visual modeling strategy for quality-aware feature extraction. Specifically, we first reformulate the quality regression problem into a question and answering (Q&A) task and construct Q&A prompts for VQA instruction tuning. Then, we design a spatiotemporal vision encoder to extract spatial and temporal features to represent the quality characteristics of videos, which are subsequently mapped into the language space by the spatiotemporal projector for modality alignment. Finally, the aligned visual tokens and the quality-inquired text tokens are aggregated as inputs for the large language model (LLM) to generate the quality score and level. Extensive experiments demonstrate that LMM-VQA achieves state-of-the-art performance across five VQA benchmarks, exhibiting an average improvement of $5\%$ in generalization ability over existing methods. Furthermore, due to the advanced design of the spatiotemporal encoder and projector, LMM-VQA also performs exceptionally well on general video understanding tasks, further validating its effectiveness. Our code will be released at https://github.com/Sueqk/LMM-VQA.
FRAP: Faithful and Realistic Text-to-Image Generation with Adaptive Prompt Weighting
Aug 21, 2024



Text-to-image (T2I) diffusion models have demonstrated impressive capabilities in generating high-quality images given a text prompt. However, ensuring the prompt-image alignment remains a considerable challenge, i.e., generating images that faithfully align with the prompt's semantics. Recent works attempt to improve the faithfulness by optimizing the latent code, which potentially could cause the latent code to go out-of-distribution and thus produce unrealistic images. In this paper, we propose FRAP, a simple, yet effective approach based on adaptively adjusting the per-token prompt weights to improve prompt-image alignment and authenticity of the generated images. We design an online algorithm to adaptively update each token's weight coefficient, which is achieved by minimizing a unified objective function that encourages object presence and the binding of object-modifier pairs. Through extensive evaluations, we show FRAP generates images with significantly higher prompt-image alignment to prompts from complex datasets, while having a lower average latency compared to recent latent code optimization methods, e.g., 4 seconds faster than D&B on the COCO-Subject dataset. Furthermore, through visual comparisons and evaluation on the CLIP-IQA-Real metric, we show that FRAP not only improves prompt-image alignment but also generates more authentic images with realistic appearances. We also explore combining FRAP with prompt rewriting LLM to recover their degraded prompt-image alignment, where we observe improvements in both prompt-image alignment and image quality.
Achieving Complex Image Edits via Function Aggregation with Diffusion Models
Aug 16, 2024



Diffusion models have demonstrated strong performance in generative tasks, making them ideal candidates for image editing. Recent studies highlight their ability to apply desired edits effectively by following textual instructions, yet two key challenges persist. First, these models struggle to apply multiple edits simultaneously, resulting in computational inefficiencies due to their reliance on sequential processing. Second, relying on textual prompts to determine the editing region can lead to unintended alterations in other parts of the image. In this work, we introduce FunEditor, an efficient diffusion model designed to learn atomic editing functions and perform complex edits by aggregating simpler functions. This approach enables complex editing tasks, such as object movement, by aggregating multiple functions and applying them simultaneously to specific areas. FunEditor is 5 to 24 times faster inference than existing methods on complex tasks like object movement. Our experiments demonstrate that FunEditor significantly outperforms recent baselines, including both inference-time optimization methods and fine-tuned models, across various metrics, such as image quality assessment (IQA) and object-background consistency.
Benchmarking AIGC Video Quality Assessment: A Dataset and Unified Model
Jul 31, 2024



In recent years, artificial intelligence (AI) driven video generation has garnered significant attention due to advancements in stable diffusion and large language model techniques. Thus, there is a great demand for accurate video quality assessment (VQA) models to measure the perceptual quality of AI-generated content (AIGC) videos as well as optimize video generation techniques. However, assessing the quality of AIGC videos is quite challenging due to the highly complex distortions they exhibit (e.g., unnatural action, irrational objects, etc.). Therefore, in this paper, we try to systemically investigate the AIGC-VQA problem from both subjective and objective quality assessment perspectives. For the subjective perspective, we construct a Large-scale Generated Vdeo Quality assessment (LGVQ) dataset, consisting of 2,808 AIGC videos generated by 6 video generation models using 468 carefully selected text prompts. Unlike previous subjective VQA experiments, we evaluate the perceptual quality of AIGC videos from three dimensions: spatial quality, temporal quality, and text-to-video alignment, which hold utmost importance for current video generation techniques. For the objective perspective, we establish a benchmark for evaluating existing quality assessment metrics on the LGVQ dataset, which reveals that current metrics perform poorly on the LGVQ dataset. Thus, we propose a Unify Generated Video Quality assessment (UGVQ) model to comprehensively and accurately evaluate the quality of AIGC videos across three aspects using a unified model, which uses visual, textual and motion features of video and corresponding prompt, and integrates key features to enhance feature expression. We hope that our benchmark can promote the development of quality evaluation metrics for AIGC videos. The LGVQ dataset and the UGVQ metric will be publicly released.
Building Optimal Neural Architectures using Interpretable Knowledge
Mar 20, 2024



Neural Architecture Search is a costly practice. The fact that a search space can span a vast number of design choices with each architecture evaluation taking nontrivial overhead makes it hard for an algorithm to sufficiently explore candidate networks. In this paper, we propose AutoBuild, a scheme which learns to align the latent embeddings of operations and architecture modules with the ground-truth performance of the architectures they appear in. By doing so, AutoBuild is capable of assigning interpretable importance scores to architecture modules, such as individual operation features and larger macro operation sequences such that high-performance neural networks can be constructed without any need for search. Through experiments performed on state-of-the-art image classification, segmentation, and Stable Diffusion models, we show that by mining a relatively small set of evaluated architectures, AutoBuild can learn to build high-quality architectures directly or help to reduce search space to focus on relevant areas, finding better architectures that outperform both the original labeled ones and ones found by search baselines. Code available at https://github.com/Ascend-Research/AutoBuild
CascadedGaze: Efficiency in Global Context Extraction for Image Restoration
Jan 26, 2024



Image restoration tasks traditionally rely on convolutional neural networks. However, given the local nature of the convolutional operator, they struggle to capture global information. The promise of attention mechanisms in Transformers is to circumvent this problem, but it comes at the cost of intensive computational overhead. Many recent studies in image restoration have focused on solving the challenge of balancing performance and computational cost via Transformer variants. In this paper, we present CascadedGaze Network (CGNet), an encoder-decoder architecture that employs Global Context Extractor (GCE), a novel and efficient way to capture global information for image restoration. The GCE module leverages small kernels across convolutional layers to learn global dependencies, without requiring self-attention. Extensive experimental results show that our approach outperforms a range of state-of-the-art methods on denoising benchmark datasets including both real image denoising and synthetic image denoising, as well as on image deblurring task, while being more computationally efficient.