 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unveiling Vulnerabilities of Large Reasoning Models in Machine Unlearning
Apr 05, 2026Large language models (LLMs) possess strong semantic understanding, driving significant progress in data mining applications. This is further enhanced by large reasoning models (LRMs), which provide explicit multi-step reasoning traces. On the other hand, the growing need for the right to be forgotten has driven the development of machine unlearning techniques, which aim to eliminate the influence of specific data from trained models without full retraining. However, unlearning may also introduce new security vulnerabilities by exposing additional interaction surfaces. Although many studies have investigated unlearning attacks, there is no prior work on LRMs. To bridge the gap, we first in this paper propose LRM unlearning attack that forces incorrect final answers while generating convincing but misleading reasoning traces. This objective is challenging due to non-differentiable logical constraints, weak optimization effect over long rationales, and discrete forget set selection. To overcome these challenges, we introduce a bi-level exact unlearning attack that incorporates a differentiable objective function, influential token alignment, and a relaxed indicator strategy. To demonstrate the effectiveness and generalizability of our attack, we also design novel optimization frameworks and conduct comprehensive experiments in both white-box and black-box settings, aiming to raise awareness of the emerging threats to LRM unlearning pipelines.
Membership Inference Attacks with False Discovery Rate Control
Aug 09, 2025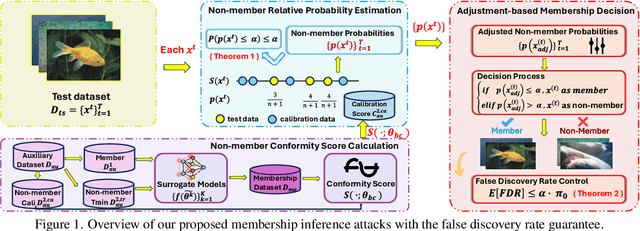

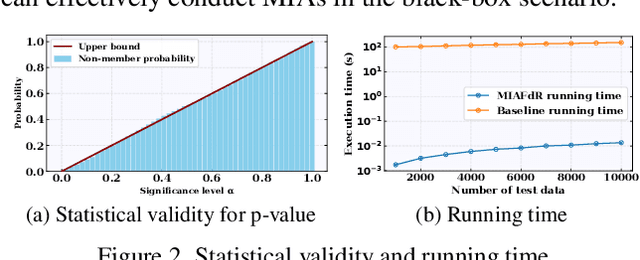
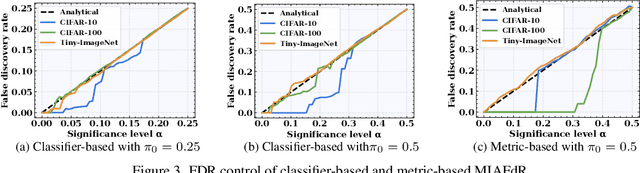
Recent studies have shown that deep learning models are vulnerable to membership inference attacks (MIAs), which aim to infer whether a data record was used to train a target model or not. To analyze and study these vulnerabilities, various MIA methods have been proposed. Despite the significance and popularity of MIAs, existing works on MIAs are limited in providing guarantees on the false discovery rate (FDR), which refers to the expected proportion of false discoveries among the identified positive discoveries. However, it is very challenging to ensure the false discovery rate guarantees, because the underlying distribution is usually unknown, and the estimated non-member probabilities often exhibit interdependence. To tackle the above challenges, in this paper, we design a novel membership inference attack method, which can provide the guarantees on the false discovery rate. Additionally, we show that our method can also provide the marginal probability guarantee on labeling true non-member data as member data. Notably, our method can work as a wrapper that can be seamlessly integrated with existing MIA methods in a post-hoc manner, while also providing the FDR control. We perform the theoretical analysis for our method. Extensive experiments in various settings (e.g., the black-box setting and the lifelong learning setting) are also conducted to verify the desirable performance of our method.
Exploring Fairness in Educational Data Mining in the Context of the Right to be Forgotten
May 29, 2024



In education data mining (EDM) communities, machine learning has achieved remarkable success in discovering patterns and structures to tackle educational challenges. Notably, fairness and algorithmic bias have gained attention in learning analytics of EDM. With the increasing demand for the right to be forgotten, there is a growing need for machine learning models to forget sensitive data and its impact, particularly within the realm of EDM. The paradigm of selective forgetting, also known as machine unlearning, has been extensively studied to address this need by eliminating the influence of specific data from a pre-trained model without complete retraining. However, existing research assumes that interactive data removal operations are conducted in secure and reliable environments, neglecting potential malicious unlearning requests to undermine the fairness of machine learning systems. In this paper, we introduce a novel class of selective forgetting attacks designed to compromise the fairness of learning models while maintaining their predictive accuracy, thereby preventing the model owner from detecting the degradation in model performance. Additionally, we propose an innovative optimization framework for selective forgetting attacks, capable of generating malicious unlearning requests across various attack scenarios. We validate the effectiveness of our proposed selective forgetting attacks on fairness through extensive experiments using diverse EDM datasets.