 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceCloak: A Multi-Dimensional Defense Framework against Unauthorized Diffusion-based Voice Cloning
May 18, 2025Diffusion Models (DMs) have achieved remarkable success in realistic voice cloning (VC), while they also increase the risk of malicious misuse. Existing proactive defenses designed for traditional VC models aim to disrupt the forgery process, but they have been proven incompatible with DMs due to the intricate generative mechanisms of diffusion. To bridge this gap, we introduce VoiceCloak, a multi-dimensional proactive defense framework with the goal of obfuscating speaker identity and degrading perceptual quality in potential unauthorized VC. To achieve these goals, we conduct a focused analysis to identify specific vulnerabilities within DMs, allowing VoiceCloak to disrupt the cloning process by introducing adversarial perturbations into the reference audio. Specifically, to obfuscate speaker identity, VoiceCloak first targets speaker identity by distorting representation learning embeddings to maximize identity variation, which is guided by auditory perception principles. Additionally, VoiceCloak disrupts crucial conditional guidance processes, particularly attention context, thereby preventing the alignment of vocal characteristics that are essential for achieving convincing cloning. Then, to address the second objective, VoiceCloak introduces score magnitude amplification to actively steer the reverse trajectory away from the generation of high-quality speech. Noise-guided semantic corruption is further employed to disrupt structural speech semantics captured by DMs, degrading output quality. Extensive experiments highlight VoiceCloak's outstanding defense success rate against unauthorized diffusion-based voice cloning. Audio samples of VoiceCloak are available at https://voice-cloak.github.io/VoiceCloak/.
Towards Open-world Generalized Deepfake Detection: General Feature Extraction via Unsupervised Domain Adaptation
May 18, 2025With the development of generative artificial intelligence, new forgery methods are rapidly emerging. Social platforms are flooded with vast amounts of unlabeled synthetic data and authentic data, making it increasingly challenging to distinguish real from fake. Due to the lack of labels, existing supervised detection methods struggle to effectively address the detection of unknown deepfake methods. Moreover, in open world scenarios, the amount of unlabeled data greatly exceeds that of labeled data. Therefore, we define a new deepfake detection generalization task which focuses on how to achieve efficient detection of large amounts of unlabeled data based on limited labeled data to simulate a open world scenario. To solve the above mentioned task, we propose a novel Open-World Deepfake Detection Generalization Enhancement Training Strategy (OWG-DS) to improve the generalization ability of existing methods. Our approach aims to transfer deepfake detection knowledge from a small amount of labeled source domain data to large-scale unlabeled target domain data. Specifically, we introduce the Domain Distance Optimization (DDO) module to align different domain features by optimizing both inter-domain and intra-domain distances. Additionally, the Similarity-based Class Boundary Separation (SCBS) module is used to enhance the aggregation of similar samples to ensure clearer class boundaries, while an adversarial training mechanism is adopted to learn the domain-invariant features. Extensive experiments show that the proposed deepfake detection generalization enhancement training strategy excels in cross-method and cross-dataset scenarios, improving the model's generalization.
M4-SAR: A Multi-Resolution, Multi-Polarization, Multi-Scene, Multi-Source Dataset and Benchmark for Optical-SAR Fusion Object Detection
May 16, 2025Single-source remote sensing object detection using optical or SAR images struggles in complex environments. Optical images offer rich textural details but are often affected by low-light, cloud-obscured, or low-resolution conditions, reducing the detection performance. SAR images are robust to weather, but suffer from speckle noise and limited semantic expressiveness. Optical and SAR images provide complementary advantages, and fusing them can significantly improve the detection accuracy. However, progress in this field is hindered by the lack of large-scale, standardized datasets. To address these challenges, we propose the first comprehensive dataset for optical-SAR fusion object detection, named Multi-resolution, Multi-polarization, Multi-scene, Multi-source SAR dataset (M4-SAR). It contains 112,184 precisely aligned image pairs and nearly one million labeled instances with arbitrary orientations, spanning six key categories. To enable standardized evaluation, we develop a unified benchmarking toolkit that integrates six state-of-the-art multi-source fusion methods. Furthermore, we propose E2E-OSDet, a novel end-to-end multi-source fusion detection framework that mitigates cross-domain discrepancies and establishes a robust baseline for future studies. Extensive experiments on M4-SAR demonstrate that fusing optical and SAR data can improve $mAP$ by 5.7\% over single-source inputs, with particularly significant gains in complex environments. The dataset and code are publicly available at https://github.com/wchao0601/M4-SAR.
Weakly-supervised Audio Temporal Forgery Localization via Progressive Audio-language Co-learning Network
May 03, 2025Audio temporal forgery localization (ATFL) aims to find the precise forgery regions of the partial spoof audio that is purposefully modified. Existing ATFL methods rely on training efficient networks using fine-grained annotations, which are obtained costly and challenging in real-world scenarios. To meet this challenge, in this paper, we propose a progressive audio-language co-learning network (LOCO) that adopts co-learning and self-supervision manners to prompt localization performance under weak supervision scenarios. Specifically, an audio-language co-learning module is first designed to capture forgery consensus features by aligning semantics from temporal and global perspectives. In this module, forgery-aware prompts are constructed by using utterance-level annotations together with learnable prompts, which can incorporate semantic priors into temporal content features dynamically. In addition, a forgery localization module is applied to produce forgery proposals based on fused forgery-class activation sequences. Finally, a progressive refinement strategy is introduced to generate pseudo frame-level labels and leverage supervised semantic contrastive learning to amplify the semantic distinction between real and fake content, thereby continuously optimizing forgery-aware features. Extensive experiments show that the proposed LOCO achieves SOTA performance on three public benchmarks.
Diffusion-based Adversarial Identity Manipulation for Facial Privacy Protection
Apr 30, 2025The success of face recognition (FR) systems has led to serious privacy concerns due to potential unauthorized surveillance and user tracking on social networks. Existing methods for enhancing privacy fail to generate natural face images that can protect facial privacy. In this paper, we propose diffusion-based adversarial identity manipulation (DiffAIM) to generate natural and highly transferable adversarial faces against malicious FR systems. To be specific, we manipulate facial identity within the low-dimensional latent space of a diffusion model. This involves iteratively injecting gradient-based adversarial identity guidance during the reverse diffusion process, progressively steering the generation toward the desired adversarial faces. The guidance is optimized for identity convergence towards a target while promoting semantic divergence from the source, facilitating effective impersonation while maintaining visual naturalness. We further incorporate structure-preserving regularization to preserve facial structure consistency during manipulation. Extensive experiments on both face verification and identification tasks demonstrate that compared with the state-of-the-art, DiffAIM achieves stronger black-box attack transferability while maintaining superior visual quality. We also demonstrate the effectiveness of the proposed approach for commercial FR APIs, including Face++ and Aliyun.
Vidi: Large Multimodal Models for Video Understanding and Editing
Apr 22, 2025



Humans naturally share information with those they are connected to, and video has become one of the dominant mediums for communication and expression on the Internet. To support the creation of high-quality large-scale video content, a modern pipeline requires a comprehensive understanding of both the raw input materials (e.g., the unedited footage captured by cameras) and the editing components (e.g., visual effects). In video editing scenarios, models must process multiple modalities (e.g., vision, audio, text) with strong background knowledge and handle flexible input lengths (e.g., hour-long raw videos), which poses significant challenges for traditional models. In this report, we introduce Vidi, a family of Large Multimodal Models (LMMs) for a wide range of video understand editing scenarios. The first release focuses on temporal retrieval, i.e., identifying the time ranges within the input videos corresponding to a given text query, which plays a critical role in intelligent editing. The model is capable of processing hour-long videos with strong temporal understanding capability, e.g., retrieve time ranges for certain queries. To support a comprehensive evaluation in real-world scenarios, we also present the VUE-TR benchmark, which introduces five key advancements. 1) Video duration: significantly longer than existing temporal retrival datasets, 2) Audio support: includes audio-based queries, 3) Query format: diverse query lengths/formats, 4) Annotation quality: ground-truth time ranges are manually annotated. 5) Evaluation metric: a refined IoU metric to support evaluation over multiple time ranges. Remarkably, Vidi significantly outperforms leading proprietary models, e.g., GPT-4o and Gemini, on the temporal retrieval task, indicating its superiority in video editing scenarios.
FakeScope: Large Multimodal Expert Model for Transparent AI-Generated Image Forensics
Mar 31, 2025



The rapid and unrestrained advancement of generative artificial intelligence (AI) presents a double-edged sword: while enabling unprecedented creativity, it also facilitates the generation of highly convincing deceptive content, undermining societal trust. As image generation techniques become increasingly sophisticated, detecting synthetic images is no longer just a binary task: it necessitates interpretable, context-aware methodologies that enhance trustworthiness and transparency. However, existing detection models primarily focus on classification, offering limited explanatory insights into image authenticity. In this work, we propose FakeScope, an expert multimodal model (LMM) tailored for AI-generated image forensics, which not only identifies AI-synthetic images with high accuracy but also provides rich, interpretable, and query-driven forensic insights. We first construct FakeChain dataset that contains linguistic authenticity reasoning based on visual trace evidence, developed through a novel human-machine collaborative framework. Building upon it, we further present FakeInstruct, the largest multimodal instruction tuning dataset containing 2 million visual instructions tailored to enhance forensic awareness in LMMs. FakeScope achieves state-of-the-art performance in both closed-ended and open-ended forensic scenarios. It can distinguish synthetic images with high accuracy while offering coherent and insightful explanations, free-form discussions on fine-grained forgery attributes, and actionable enhancement strategies. Notably, despite being trained exclusively on qualitative hard labels, FakeScope demonstrates remarkable zero-shot quantitative capability on detection, enabled by our proposed token-based probability estimation strategy. Furthermore, FakeScope exhibits strong generalization and in-the-wild ability, ensuring its applicability in real-world scenarios.
LEGNet: Lightweight Edge-Gaussian Driven Network for Low-Quality Remote Sensing Image Object Detection
Mar 18, 2025
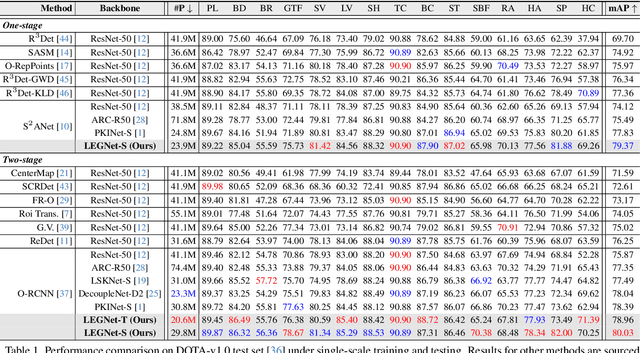
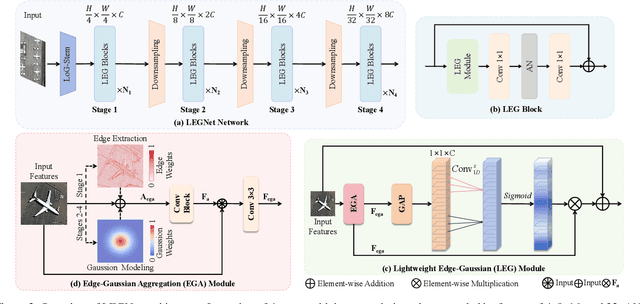
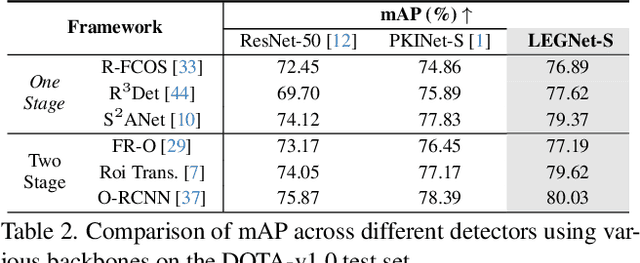
Remote sensing object detection (RSOD) faces formidable challenges in complex visual environments. Aerial and satellite images inherently suffer from limitations such as low spatial resolution, sensor noise, blurred objects, low-light degradation, and partial occlusions. These degradation factors collectively compromise the feature discriminability in detection models, resulting in three key issues: (1) reduced contrast that hampers foreground-background separation, (2) structural discontinuities in edge representations, and (3) ambiguous feature responses caused by variations in illumination. These collectively weaken model robustness and deployment feasibility. To address these challenges, we propose LEGNet, a lightweight network that incorporates a novel edge-Gaussian aggregation (EGA) module specifically designed for low-quality remote sensing images. Our key innovation lies in the synergistic integration of Scharr operator-based edge priors with uncertainty-aware Gaussian modeling: (a) The orientation-aware Scharr filters preserve high-frequency edge details with rotational invariance; (b) The uncertainty-aware Gaussian layers probabilistically refine low-confidence features through variance estimation. This design enables precision enhancement while maintaining architectural simplicity. Comprehensive evaluations across four RSOD benchmarks (DOTA-v1.0, v1.5, DIOR-R, FAIR1M-v1.0) and a UAV-view dataset (VisDrone2019) demonstrate significant improvements. LEGNet achieves state-of-the-art performance across five benchmark datasets while ensuring computational efficiency, making it well-suited for deployment on resource-constrained edge devices in real-world remote sensing applications. The code is available at https://github.com/lwCVer/LEGNet.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
ChatReID: Open-ended Interactive Person Retrieval via Hierarchical Progressive Tuning for Vision Language Models
Feb 27, 2025



Person re-identification (Re-ID) is a critical task in human-centric intelligent systems, enabling consistent identification of individuals across different camera views using multi-modal query information. Recent studies have successfully integrated LVLMs with person Re-ID, yielding promising results. However, existing LVLM-based methods face several limitations. They rely on extracting textual embeddings from fixed templates, which are used either as intermediate features for image representation or for prompt tuning in domain-specific tasks. Furthermore, they are unable to adopt the VQA inference format, significantly restricting their broader applicability. In this paper, we propose a novel, versatile, one-for-all person Re-ID framework, ChatReID. Our approach introduces a Hierarchical Progressive Tuning (HPT) strategy, which ensures fine-grained identity-level retrieval by progressively refining the model's ability to distinguish pedestrian identities. Extensive experiments demonstrate that our approach outperforms SOTA methods across ten benchmarks in four different Re-ID settings, offering enhanced flexibility and user-friendliness. ChatReID provides a scalable, practical solution for real-world person Re-ID applications, enabling effective multi-modal interaction and fine-grained identity discrimination.