 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREMISE: Matching-based Prediction for Accurate Review Recommendation
May 02, 2025



We present PREMISE (PREdict with Matching ScorEs), a new architecture for the matching-based learning in the multimodal fields for the multimodal review helpfulness (MRHP) task. Distinct to previous fusion-based methods which obtains multimodal representations via cross-modal attention for downstream tasks, PREMISE computes the multi-scale and multi-field representations, filters duplicated semantics, and then obtained a set of matching scores as feature vectors for the downstream recommendation task. This new architecture significantly boosts the performance for such multimodal tasks whose context matching content are highly correlated to the targets of that task, compared to the state-of-the-art fusion-based methods. Experimental results on two publicly available datasets show that PREMISE achieves promising performance with less computational cost.
APSeg: Auto-Prompt Model with Acquired and Injected Knowledge for Nuclear Instance Segmentation and Classification
Apr 03, 2025



Nuclear instance segmentation and classification provide critical quantitative foundations for digital pathology diagnosis. With the advent of the foundational Segment Anything Model (SAM), the accuracy and efficiency of nuclear segmentation have improved significantly. However, SAM imposes a strong reliance on precise prompts, and its class-agnostic design renders its classification results entirely dependent on the provided prompts. Therefore, we focus on generating prompts with more accurate localization and classification and propose \textbf{APSeg}, \textbf{A}uto-\textbf{P}rompt model with acquired and injected knowledge for nuclear instance \textbf{Seg}mentation and classification. APSeg incorporates two knowledge-aware modules: (1) Distribution-Guided Proposal Offset Module (\textbf{DG-POM}), which learns distribution knowledge through density map guided, and (2) Category Knowledge Semantic Injection Module (\textbf{CK-SIM}), which injects morphological knowledge derived from category descriptions. We conducted extensive experiments on the PanNuke and CoNSeP datasets, demonstrating the effectiveness of our approach. The code will be released upon acceptance.
A Survey of Reinforcement Learning-Based Motion Planning for Autonomous Driving: Lessons Learned from a Driving Task Perspective
Mar 31, 2025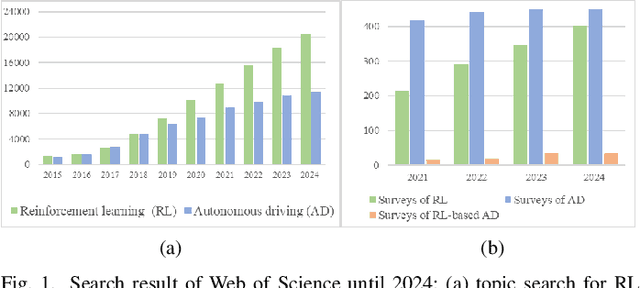

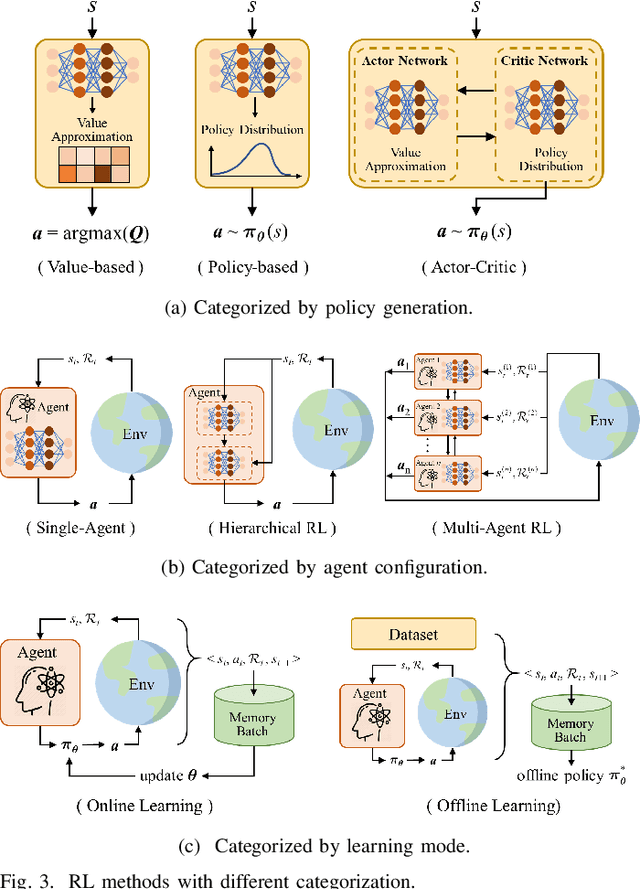
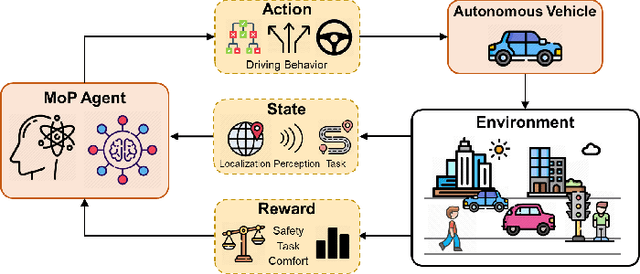
Reinforcement learning (RL), with its ability to explore and optimize policies in complex, dynamic decision-making tasks, has emerged as a promising approach to addressing motion planning (MoP) challenges in autonomous driving (AD). Despite rapid advancements in RL and AD, a systematic description and interpretation of the RL design process tailored to diverse driving tasks remains underdeveloped. This survey provides a comprehensive review of RL-based MoP for AD, focusing on lessons from task-specific perspectives. We first outline the fundamentals of RL methodologies, and then survey their applications in MoP, analyzing scenario-specific features and task requirements to shed light on their influence on RL design choices. Building on this analysis, we summarize key design experiences, extract insights from various driving task applications, and provide guidance for future implementations. Additionally, we examine the frontier challenges in RL-based MoP, review recent efforts to addresse these challenges, and propose strategies for overcoming unresolved issues.
Risk-Aware Reinforcement Learning for Autonomous Driving: Improving Safety When Driving through Intersection
Mar 27, 2025Applying reinforcement learning to autonomous driving has garnered widespread attention. However, classical reinforcement learning methods optimize policies by maximizing expected rewards but lack sufficient safety considerations, often putting agents in hazardous situations. This paper proposes a risk-aware reinforcement learning approach for autonomous driving to improve the safety performance when crossing the intersection. Safe critics are constructed to evaluate driving risk and work in conjunction with the reward critic to update the actor. Based on this, a Lagrangian relaxation method and cyclic gradient iteration are combined to project actions into a feasible safe region. Furthermore, a Multi-hop and Multi-layer perception (MLP) mixed Attention Mechanism (MMAM) is incorporated into the actor-critic network, enabling the policy to adapt to dynamic traffic and overcome permutation sensitivity challenges. This allows the policy to focus more effectively on surrounding potential risks while enhancing the identification of passing opportunities. Simulation tests are conducted on different tasks at unsignalized intersections. The results show that the proposed approach effectively reduces collision rates and improves crossing efficiency in comparison to baseline algorithms. Additionally, our ablation experiments demonstrate the benefits of incorporating risk-awareness and MMAM into RL.
Hybrid Action Based Reinforcement Learning for Multi-Objective Compatible Autonomous Driving
Jan 14, 2025Reinforcement Learning (RL) has shown excellent performance in solving decision-making and control problems of autonomous driving, which is increasingly applied in diverse driving scenarios. However, driving is a multi-attribute problem, leading to challenges in achieving multi-objective compatibility for current RL methods, especially in both policy execution and policy iteration. On the one hand, the common action space structure with single action type limits driving flexibility or results in large behavior fluctuations during policy execution. On the other hand, the multi-attribute weighted single reward function result in the agent's disproportionate attention to certain objectives during policy iterations. To this end, we propose a Multi-objective Ensemble-Critic reinforcement learning method with Hybrid Parametrized Action for multi-objective compatible autonomous driving. Specifically, a parameterized action space is constructed to generate hybrid driving actions, combining both abstract guidance and concrete control commands. A multi-objective critics architecture is constructed considering multiple attribute rewards, to ensure simultaneously focusing on different driving objectives. Additionally, uncertainty-based exploration strategy is introduced to help the agent faster approach viable driving policy. The experimental results in both the simulated traffic environment and the HighD dataset demonstrate that our method can achieve multi-objective compatible autonomous driving in terms of driving efficiency, action consistency, and safety. It enhances the general performance of the driving while significantly increasing training efficiency.
A Survey on Multi-Generative Agent System: Recent Advances and New Frontiers
Dec 23, 2024



Multi-generative agent systems (MGASs) have become a research hotspot since the rise of large language models (LLMs). However, with the continuous influx of new related works, the existing reviews struggle to capture them comprehensively. This paper presents a comprehensive survey of these studies. We first discuss the definition of MGAS, a framework encompassing much of previous work. We provide an overview of the various applications of MGAS in (i) solving complex tasks, (ii) simulating specific scenarios, and (iii) evaluating generative agents. Building on previous studies, we also highlight several challenges and propose future directions for research in this field.
Hyperbolic-constraint Point Cloud Reconstruction from Single RGB-D Images
Dec 12, 2024Reconstructing desired objects and scenes has long been a primary goal in 3D computer vision. Single-view point cloud reconstruction has become a popular technique due to its low cost and accurate results. However, single-view reconstruction methods often rely on expensive CAD models and complex geometric priors. Effectively utilizing prior knowledge about the data remains a challenge. In this paper, we introduce hyperbolic space to 3D point cloud reconstruction, enabling the model to represent and understand complex hierarchical structures in point clouds with low distortion. We build upon previous methods by proposing a hyperbolic Chamfer distance and a regularized triplet loss to enhance the relationship between partial and complete point clouds. Additionally, we design adaptive boundary conditions to improve the model's understanding and reconstruction of 3D structures. Our model outperforms most existing models, and ablation studies demonstrate the significance of our model and its components. Experimental results show that our method significantly improves feature extraction capabilities. Our model achieves outstanding performance in 3D reconstruction tasks.
DRUM: Learning Demonstration Retriever for Large MUlti-modal Models
Dec 10, 2024



Recently, large language models (LLMs) have demonstrated impressive capabilities in dealing with new tasks with the help of in-context learning (ICL). In the study of Large Vision-Language Models (LVLMs), when implementing ICL, researchers usually adopts the naive strategies like fixed demonstrations across different samples, or selecting demonstrations directly via a visual-language embedding model. These methods does not guarantee the configured demonstrations fit the need of the LVLMs. To address this issue, we now propose a novel framework, \underline{d}emonstration \underline{r}etriever for large m\underline{u}lti-modal \underline{m}odel (DRUM), which fine-tunes the visual-language embedding model to better meet the LVLM's needs. First, we discuss the retrieval strategies for a visual-language task, assuming an embedding model is given. And we propose to concate the image and text embeddings to enhance the retrieval performance. Second, we propose to re-rank the demonstrations retrieved by the embedding model via the LVLM's feedbacks, and calculate a list-wise ranking loss for training the embedding model. Third, we propose an iterative demonstration mining strategy to improve the training of the embedding model. Through extensive experiments on 3 types of visual-language tasks, 7 benchmark datasets, our DRUM framework is proven to be effective in boosting the LVLM's in-context learning performance via retrieving more proper demonstrations.
Two are better than one: Context window extension with multi-grained self-injection
Oct 25, 2024



The limited context window of contemporary large language models (LLMs) remains a huge barrier to their broader application across various domains. While continual pre-training on long-context data is a straightforward and effective solution, it incurs substantial costs in terms of data acquisition and computational resources. To alleviate this issue, we propose SharedLLM, a novel approach grounded in the design philosophy of multi-grained context compression and query-aware information retrieval. SharedLLM is composed of two short-context LLMs such as LLaMA-2, termed upper model and lower model. The lower model functions as a compressor while the upper model acts as a decoder. The upper model receives compressed, multi-grained context information from the lower model and performs context-aware modeling on the running text. Information transfer between the compressor and decoder occurs only at the lowest layers to refrain from long forward paths in the lower model and redundant cross-attention modules in the upper model. Based on this architecture, we introduce a specialized tree-style data structure to efficiently encode, store and retrieve multi-grained contextual information for text chunks. This structure, combined with a search algorithm, enables rapid encoding and retrieval of relevant information from various levels of the tree based on the input query. This entire process, wherein the sender and receiver are derived from the same LLM layer, is referred to as self-injection.
PEDRO: Parameter-Efficient Fine-tuning with Prompt DEpenDent Representation MOdification
Sep 26, 2024



Due to their substantial sizes, large language models (LLMs) are typically deployed within a single-backbone multi-tenant framework. In this setup, a single instance of an LLM backbone must cater to multiple users or tasks through the application of various parameter-efficient fine-tuning (PEFT) models. Despite the availability of numerous effective PEFT techniques such as LoRA, there remains a need for a PEFT approach that achieves both high efficiency during inference and competitive performance on downstream tasks. In this research, we introduce a new and straightforward PEFT methodology named \underline{P}rompt D\underline{E}pen\underline{D}ent \underline{R}epresentation M\underline{O}dification (PEDRO). The proposed method involves integrating a lightweight vector generator into each Transformer layer, which generates vectors contingent upon the input prompts. These vectors then modify the hidden representations created by the LLM through a dot product operation, thereby influencing the semantic output and generated content of the model. Extensive experimentation across a variety of tasks indicates that: (a) PEDRO surpasses recent PEFT benchmarks when using a similar number of tunable parameters. (b) Under the single-backbone multi-tenant deployment model, PEDRO exhibits superior efficiency compared to LoRA, indicating significant industrial potential.