 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeaXDrive: Feasibility-aware Trajectory-Centric Diffusion Planning for End-to-End Autonomous Driving
Apr 14, 2026End-to-end diffusion planning has shown strong potential for autonomous driving, but the physical feasibility of generated trajectories remains insufficiently addressed. In particular, generated trajectories may exhibit local geometric irregularities, violate trajectory-level kinematic constraints, or deviate from the drivable area, indicating that the commonly used noise-centric formulation in diffusion planning is not yet well aligned with the trajectory space where feasibility is more naturally characterized. To address this issue, we propose FeaXDrive, a feasibility-aware trajectory-centric diffusion planning method for end-to-end autonomous driving. The core idea is to treat the clean trajectory as the unified object for feasibility-aware modeling throughout the diffusion process. Built on this trajectory-centric formulation, FeaXDrive integrates adaptive curvature-constrained training to improve intrinsic geometric and kinematic feasibility, drivable-area guidance within reverse diffusion sampling to enhance consistency with the drivable area, and feasibility-aware GRPO post-training to further improve planning performance while balancing trajectory-space feasibility. Experiments on the NAVSIM benchmark show that FeaXDrive achieves strong closed-loop planning performance while substantially improving trajectory-space feasibility. These findings highlight the importance of explicitly modeling trajectory-space feasibility in end-to-end diffusion planning and provide a step toward more reliable and physically grounded autonomous driving planners.
Multi-Agent AI Framework for Road Situation Detection and C-ITS Message Generation
Nov 10, 2025


Conventional road-situation detection methods achieve strong performance in predefined scenarios but fail in unseen cases and lack semantic interpretation, which is crucial for reliable traffic recommendations. This work introduces a multi-agent AI framework that combines multimodal large language models (MLLMs) with vision-based perception for road-situation monitoring. The framework processes camera feeds and coordinates dedicated agents for situation detection, distance estimation, decision-making, and Cooperative Intelligent Transport System (C-ITS) message generation. Evaluation is conducted on a custom dataset of 103 images extracted from 20 videos of the TAD dataset. Both Gemini-2.0-Flash and Gemini-2.5-Flash were evaluated. The results show 100\% recall in situation detection and perfect message schema correctness; however, both models suffer from false-positive detections and have reduced performance in terms of number of lanes, driving lane status and cause code. Surprisingly, Gemini-2.5-Flash, though more capable in general tasks, underperforms Gemini-2.0-Flash in detection accuracy and semantic understanding and incurs higher latency (Table II). These findings motivate further work on fine-tuning specialized LLMs or MLLMs tailored for intelligent transportation applications.
Uncertainty-Aware Safety-Critical Decision and Control for Autonomous Vehicles at Unsignalized Intersections
May 26, 2025Reinforcement learning (RL) has demonstrated potential in autonomous driving (AD) decision tasks. However, applying RL to urban AD, particularly in intersection scenarios, still faces significant challenges. The lack of safety constraints makes RL vulnerable to risks. Additionally, cognitive limitations and environmental randomness can lead to unreliable decisions in safety-critical scenarios. Therefore, it is essential to quantify confidence in RL decisions to improve safety. This paper proposes an Uncertainty-aware Safety-Critical Decision and Control (USDC) framework, which generates a risk-averse policy by constructing a risk-aware ensemble distributional RL, while estimating uncertainty to quantify the policy's reliability. Subsequently, a high-order control barrier function (HOCBF) is employed as a safety filter to minimize intervention policy while dynamically enhancing constraints based on uncertainty. The ensemble critics evaluate both HOCBF and RL policies, embedding uncertainty to achieve dynamic switching between safe and flexible strategies, thereby balancing safety and efficiency. Simulation tests on unsignalized intersections in multiple tasks indicate that USDC can improve safety while maintaining traffic efficiency compared to baselines.
HCRMP: A LLM-Hinted Contextual Reinforcement Learning Framework for Autonomous Driving
May 21, 2025



Integrating Large Language Models (LLMs) with Reinforcement Learning (RL) can enhance autonomous driving (AD) performance in complex scenarios. However, current LLM-Dominated RL methods over-rely on LLM outputs, which are prone to hallucinations.Evaluations show that state-of-the-art LLM indicates a non-hallucination rate of only approximately 57.95% when assessed on essential driving-related tasks. Thus, in these methods, hallucinations from the LLM can directly jeopardize the performance of driving policies. This paper argues that maintaining relative independence between the LLM and the RL is vital for solving the hallucinations problem. Consequently, this paper is devoted to propose a novel LLM-Hinted RL paradigm. The LLM is used to generate semantic hints for state augmentation and policy optimization to assist RL agent in motion planning, while the RL agent counteracts potential erroneous semantic indications through policy learning to achieve excellent driving performance. Based on this paradigm, we propose the HCRMP (LLM-Hinted Contextual Reinforcement Learning Motion Planner) architecture, which is designed that includes Augmented Semantic Representation Module to extend state space. Contextual Stability Anchor Module enhances the reliability of multi-critic weight hints by utilizing information from the knowledge base. Semantic Cache Module is employed to seamlessly integrate LLM low-frequency guidance with RL high-frequency control. Extensive experiments in CARLA validate HCRMP's strong overall driving performance. HCRMP achieves a task success rate of up to 80.3% under diverse driving conditions with different traffic densities. Under safety-critical driving conditions, HCRMP significantly reduces the collision rate by 11.4%, which effectively improves the driving performance in complex scenarios.
A Survey of Reinforcement Learning-Based Motion Planning for Autonomous Driving: Lessons Learned from a Driving Task Perspective
Mar 31, 2025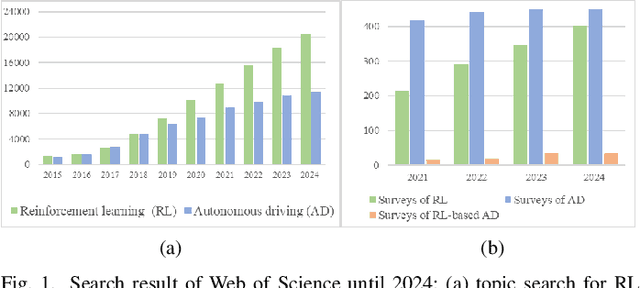

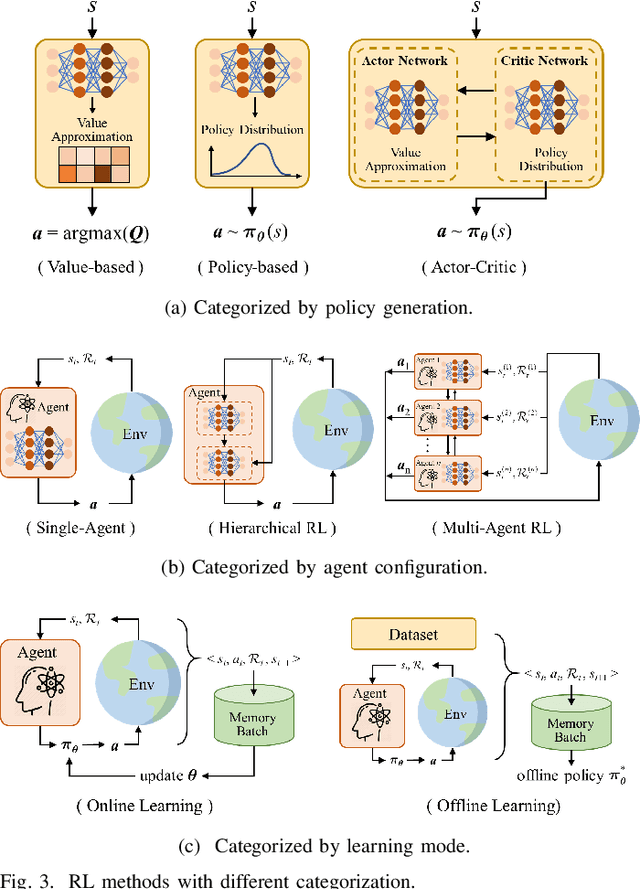
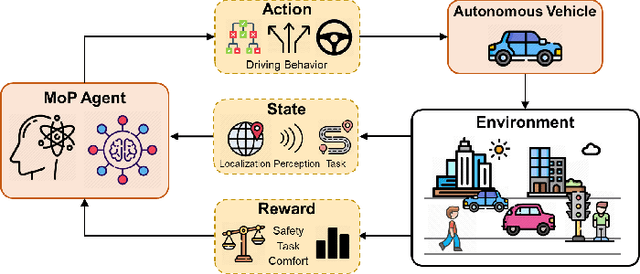
Reinforcement learning (RL), with its ability to explore and optimize policies in complex, dynamic decision-making tasks, has emerged as a promising approach to addressing motion planning (MoP) challenges in autonomous driving (AD). Despite rapid advancements in RL and AD, a systematic description and interpretation of the RL design process tailored to diverse driving tasks remains underdeveloped. This survey provides a comprehensive review of RL-based MoP for AD, focusing on lessons from task-specific perspectives. We first outline the fundamentals of RL methodologies, and then survey their applications in MoP, analyzing scenario-specific features and task requirements to shed light on their influence on RL design choices. Building on this analysis, we summarize key design experiences, extract insights from various driving task applications, and provide guidance for future implementations. Additionally, we examine the frontier challenges in RL-based MoP, review recent efforts to addresse these challenges, and propose strategies for overcoming unresolved issues.
Risk-Aware Reinforcement Learning for Autonomous Driving: Improving Safety When Driving through Intersection
Mar 27, 2025Applying reinforcement learning to autonomous driving has garnered widespread attention. However, classical reinforcement learning methods optimize policies by maximizing expected rewards but lack sufficient safety considerations, often putting agents in hazardous situations. This paper proposes a risk-aware reinforcement learning approach for autonomous driving to improve the safety performance when crossing the intersection. Safe critics are constructed to evaluate driving risk and work in conjunction with the reward critic to update the actor. Based on this, a Lagrangian relaxation method and cyclic gradient iteration are combined to project actions into a feasible safe region. Furthermore, a Multi-hop and Multi-layer perception (MLP) mixed Attention Mechanism (MMAM) is incorporated into the actor-critic network, enabling the policy to adapt to dynamic traffic and overcome permutation sensitivity challenges. This allows the policy to focus more effectively on surrounding potential risks while enhancing the identification of passing opportunities. Simulation tests are conducted on different tasks at unsignalized intersections. The results show that the proposed approach effectively reduces collision rates and improves crossing efficiency in comparison to baseline algorithms. Additionally, our ablation experiments demonstrate the benefits of incorporating risk-awareness and MMAM into RL.
Hybrid Action Based Reinforcement Learning for Multi-Objective Compatible Autonomous Driving
Jan 14, 2025Reinforcement Learning (RL) has shown excellent performance in solving decision-making and control problems of autonomous driving, which is increasingly applied in diverse driving scenarios. However, driving is a multi-attribute problem, leading to challenges in achieving multi-objective compatibility for current RL methods, especially in both policy execution and policy iteration. On the one hand, the common action space structure with single action type limits driving flexibility or results in large behavior fluctuations during policy execution. On the other hand, the multi-attribute weighted single reward function result in the agent's disproportionate attention to certain objectives during policy iterations. To this end, we propose a Multi-objective Ensemble-Critic reinforcement learning method with Hybrid Parametrized Action for multi-objective compatible autonomous driving. Specifically, a parameterized action space is constructed to generate hybrid driving actions, combining both abstract guidance and concrete control commands. A multi-objective critics architecture is constructed considering multiple attribute rewards, to ensure simultaneously focusing on different driving objectives. Additionally, uncertainty-based exploration strategy is introduced to help the agent faster approach viable driving policy. The experimental results in both the simulated traffic environment and the HighD dataset demonstrate that our method can achieve multi-objective compatible autonomous driving in terms of driving efficiency, action consistency, and safety. It enhances the general performance of the driving while significantly increasing training efficiency.